Model free sampling learning. Prediction setting: learn online from experience under policy Monte Carlo
- Update value towards sampled return
Temporal-difference learning:
- Update value towards estimated return
- is called the TD error
Comparison of backup
between dynamic programming, Monte Carlo and Temporal difference.
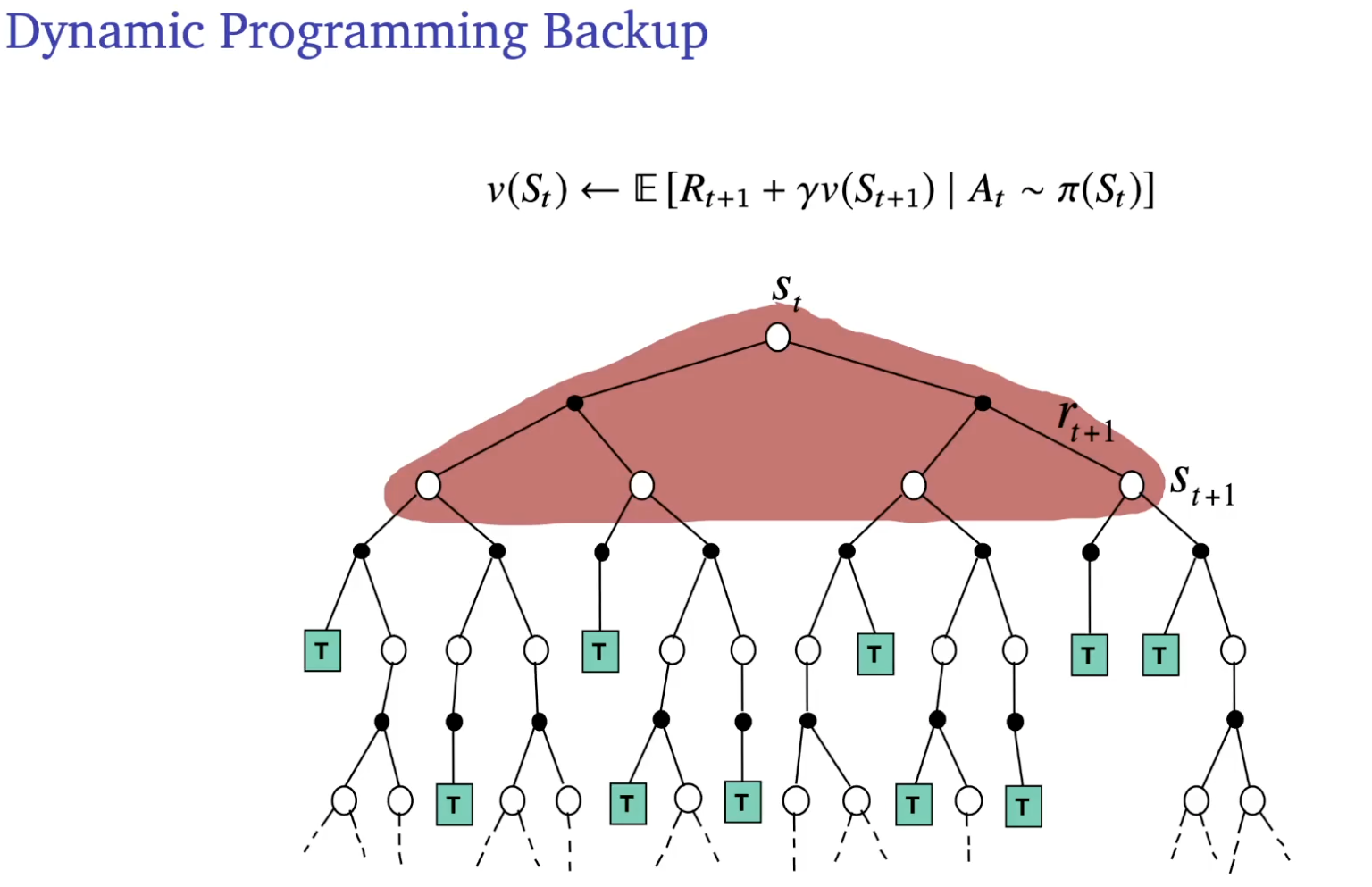
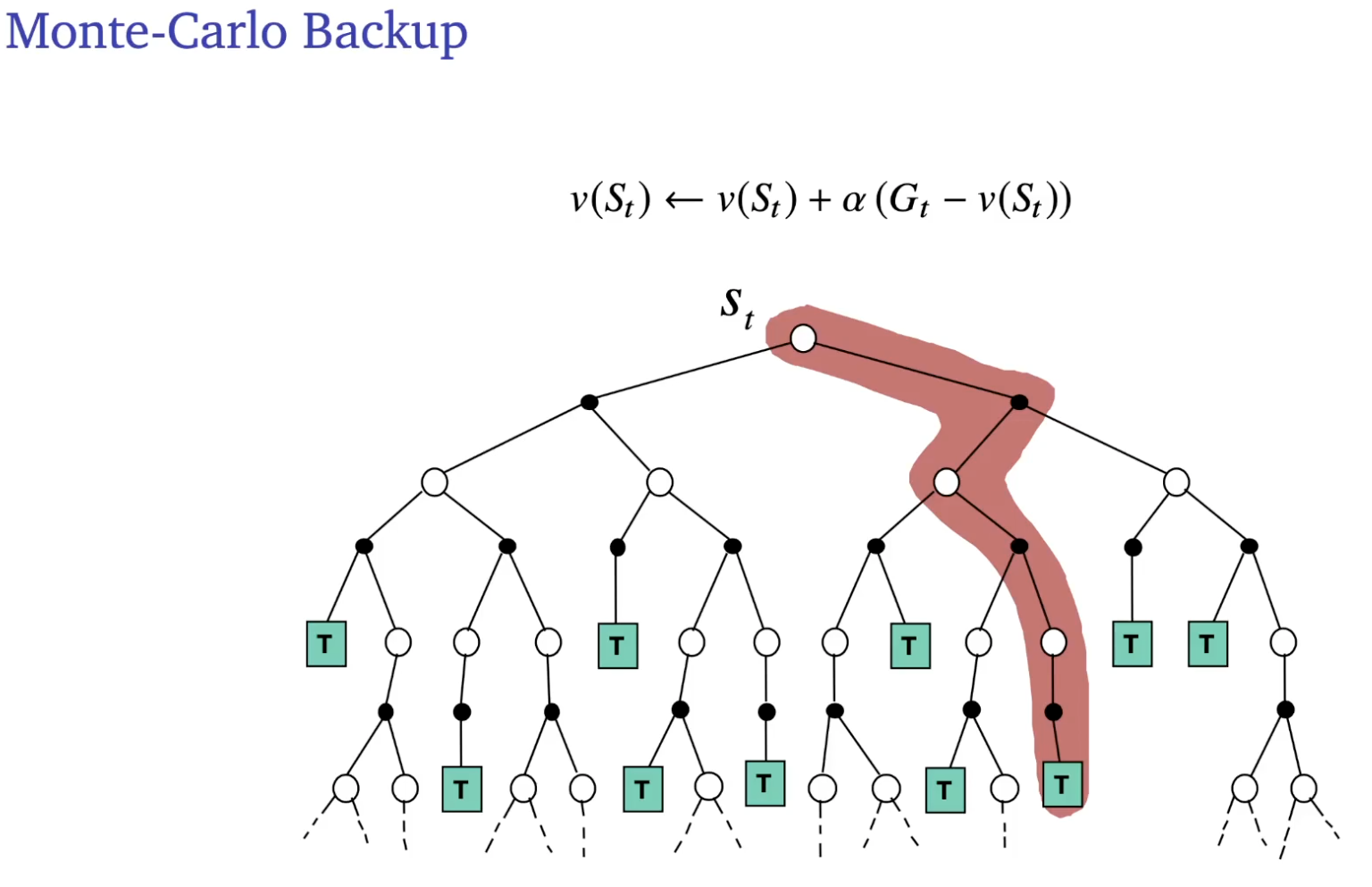
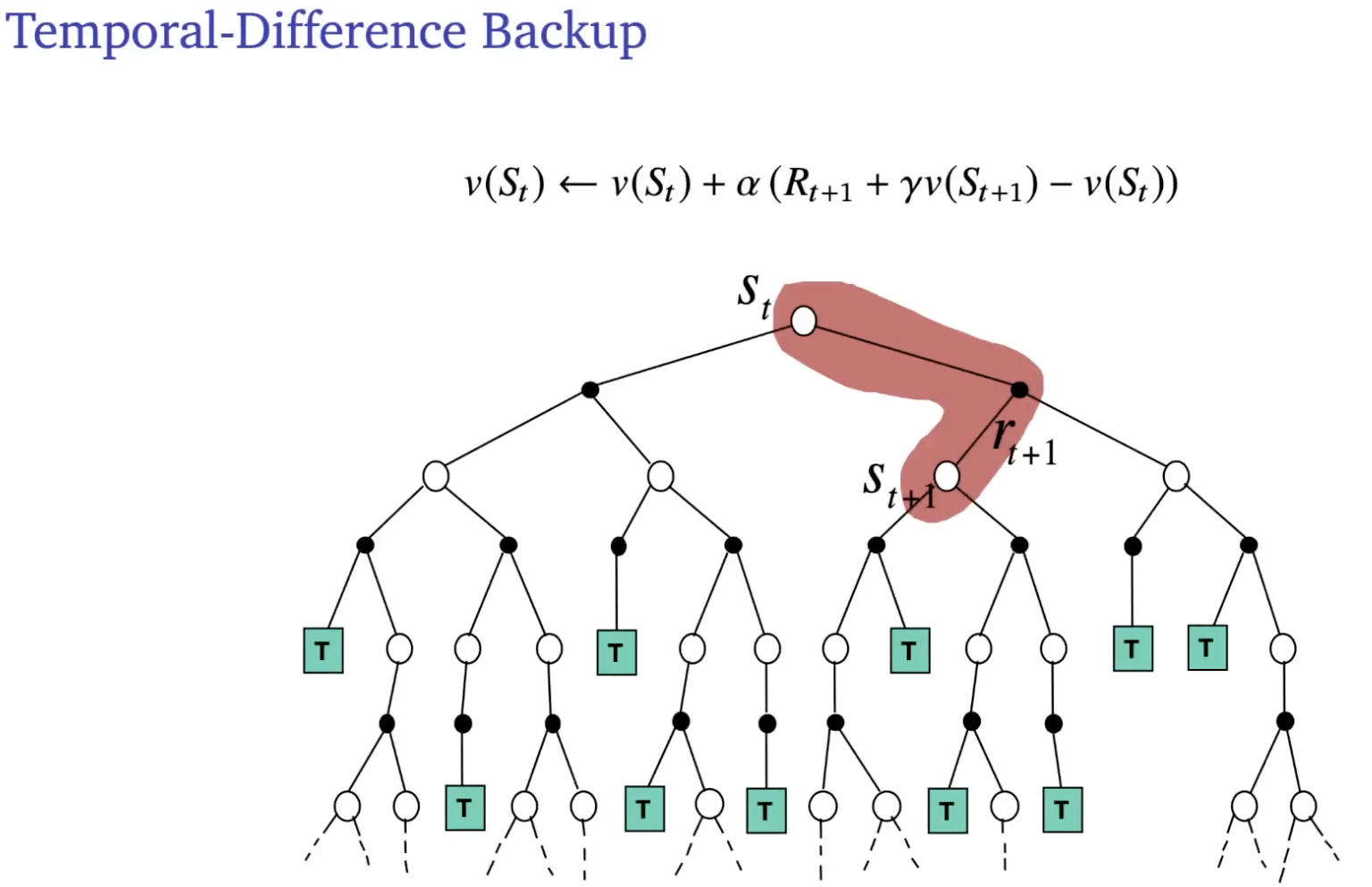
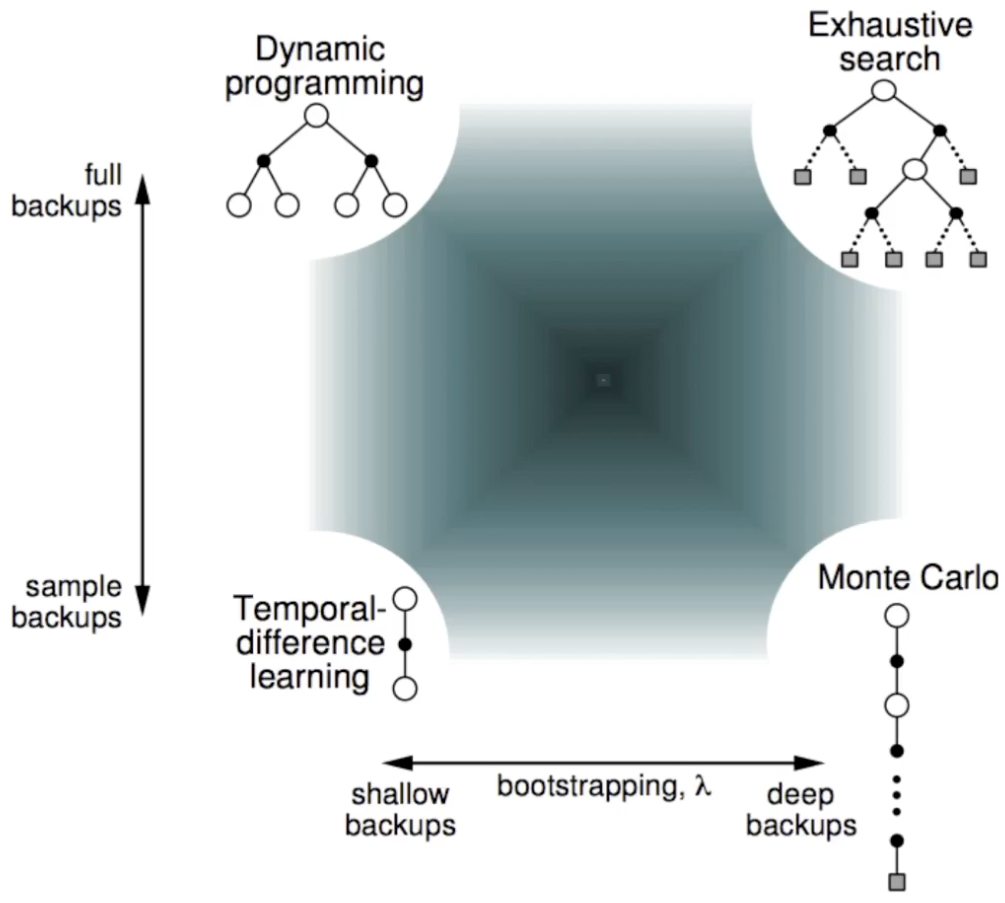
On bootstrapping
We call something bootstrapping if the update involves an estimate. I.e. it need to start from somewhere. Because of that, TD target is a bias estimate. But it has lower variance.
On the convergence
Monte Carlo converges to best mean-squared fit for the observed returns
TD converges to solution of max likelihood Markov model, given the data. It’s the solution to the empirical MDP that best fits the data.
We can kinda see that since TD only do one step.
TD exploits Markov property: can help in fully observable environments. MC does not exploit Markov property: can help in partially-observable environments.
Multi-step returns
Consider the following -step returns for :
In general, the -step return is defined by
Multi-step temporal-difference learning
With good tuning of and , it can converge faster and better than both MC and TD(0).
Mixing multi-step returns
Mixing bootstrapping and MC:
Multi-step returns bootstrap on one state, :
You can also bootstrap a little bit on multiple states:
This gives a weighted average of -step returns:
(Note, )
Think about it this way: if we only rely on , that’s MC. If only on bootstrap, that’s TD(0).
Intuition: is the ‘horizon’, so .