Model free means we are going to do sampling because we cannot enumerate what my next state would be. We only know it when we run it. Recall for known model, we have Policy & value iteration, for model free, we have the “sampling version” for them.
It should also be noticed that we will need function approximation because we need generalization. So we will first have a loss function or objective function, and then we’ll apply stochastic gradient descent to update our parameters.
The very basic bias-free method is the Monte Carlo. An overview of the methods can be found in Temporal difference.
These are the prediction methods (predict the value function). For the control part (improve the policy).
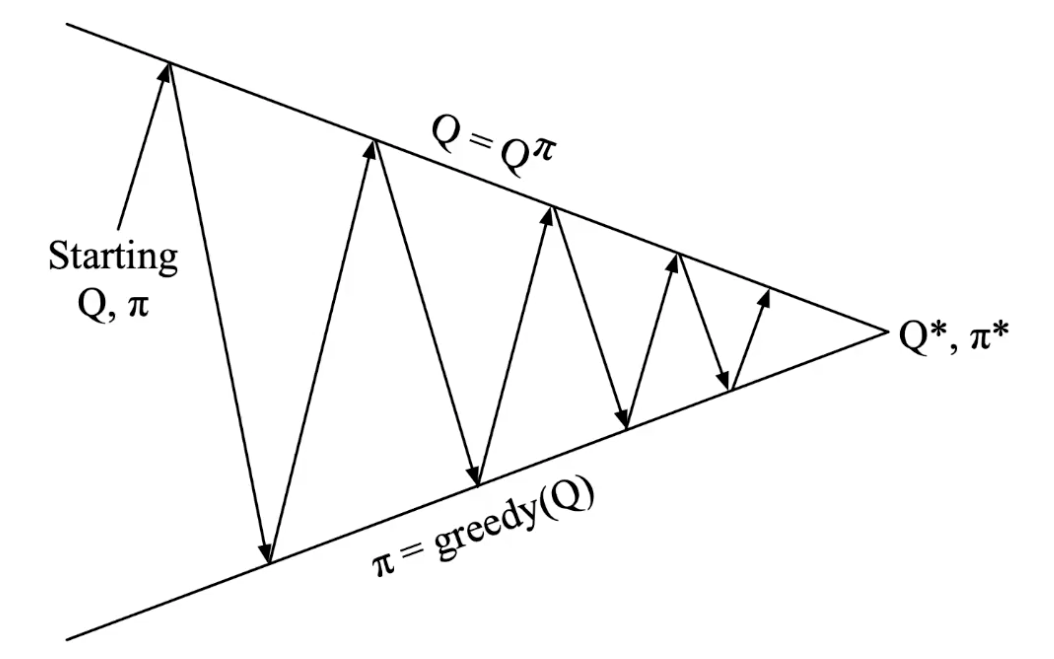 Recall we are sampling the state for MC evaluation, that means there could be state we never tried. No exploration.
Recall we are sampling the state for MC evaluation, that means there could be state we never tried. No exploration.
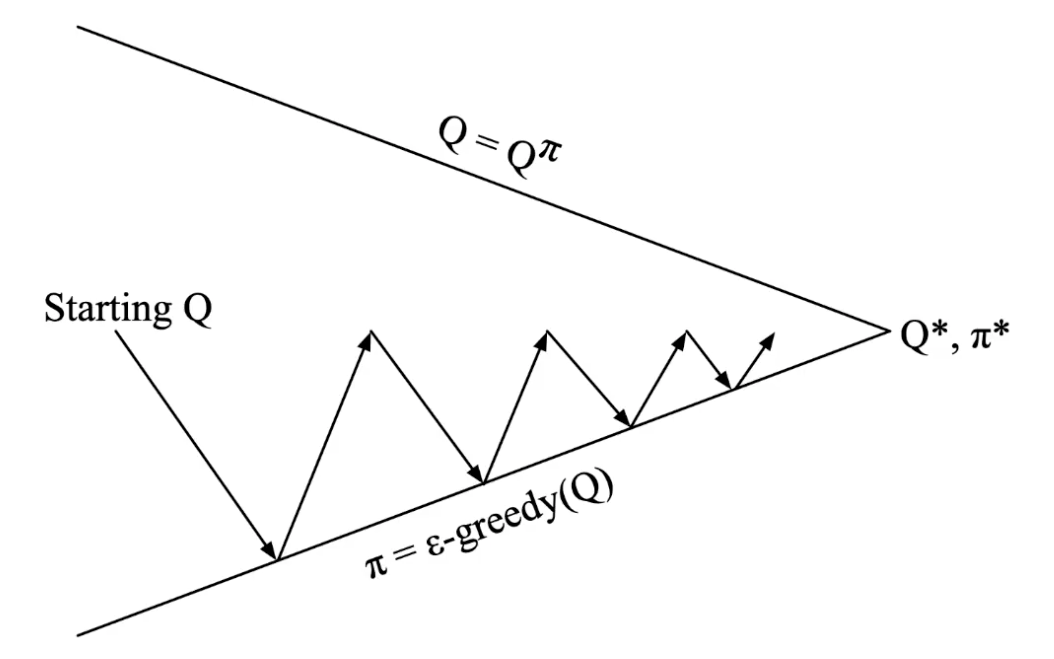 A common choice is .
Well that is very convenient, but how do we make sure it’s sound? That’s guaranteed by the theorem: GLIE Model-free control converges to the optimal action-value function, .
A common choice is .
Well that is very convenient, but how do we make sure it’s sound? That’s guaranteed by the theorem: GLIE Model-free control converges to the optimal action-value function, .
We can also use TD learning instead of MC for policy evaluation and it’s still sound.
A very simple Tabular SARSA with both prediction and control: