Created with conversation with Claude Sonnet 4.6
Ideas
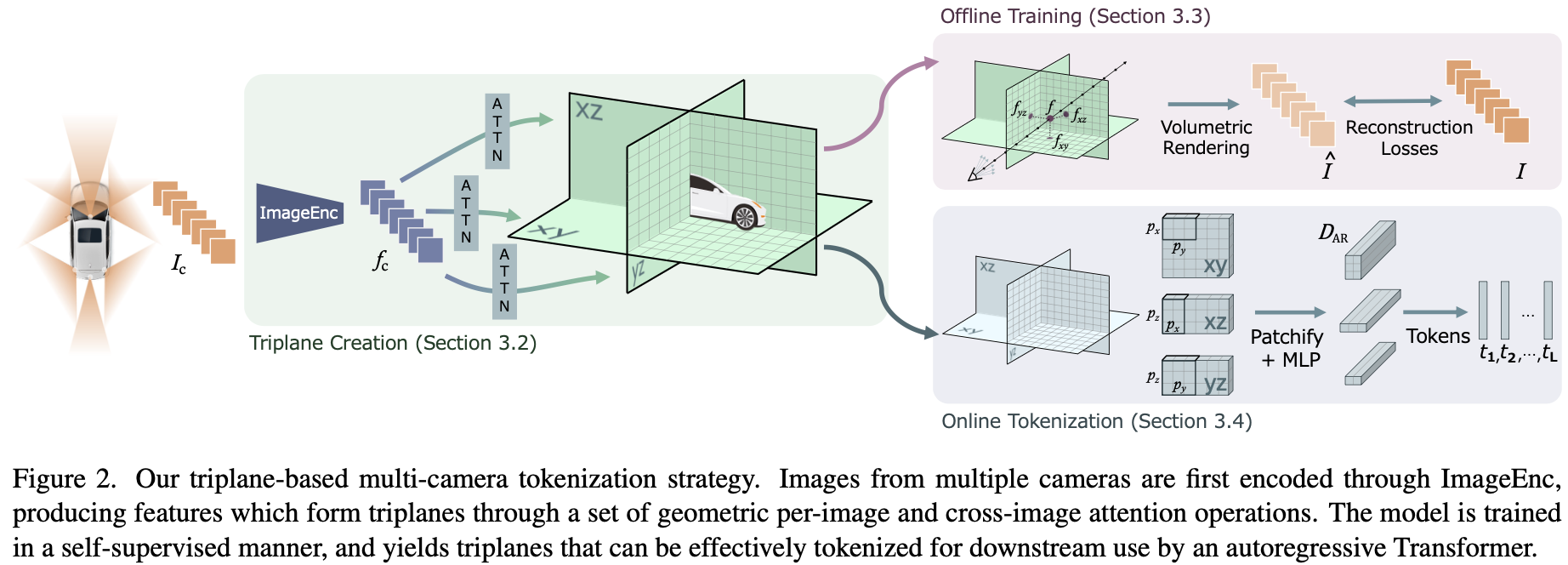
Idea 1: Fuse cameras into 3D first, tokenize after
The root problem with patch-based tokenization is that it treats cameras independently. Token count scales as N × H × W — more cameras, more tokens, longer sequences, slower LLM.
The fix: fuse all cameras into a shared 3D world representation first, then tokenize that. The 3D world doesn’t grow with camera count, so token count stays fixed regardless of how many cameras you have. This is an architectural property, not just an efficiency trick — it’s why the triplane barely degrades adding cameras while DINOv2 degrades significantly and becomes unstable.
The right 3D representation here is a triplane — three axis-aligned orthogonal feature planes. Fixed size, feedforward encodable, and geometry-aware. See TPVFormer for the construction mechanism, borrowed directly here.
Idea 2: The 3D grid can’t be uniform — use nonlinear warping
A fixed-size grid covering an unbounded driving scene faces a fundamental tradeoff: fine resolution means small coverage, large coverage means coarse resolution.
The solution is to warp the coordinate system so nearby space gets more cells and far-away space gets fewer. Think of it like a fisheye lens — the center is detailed, the periphery is compressed but still represented. This comes from Mip-NeRF 360, applied here to the triplane grid.
Why not log scale?
Log scale has a singularity at the origin (ego vehicle = center of the grid), compresses too aggressively at ranges that still matter (80–180m), and creates uneven gradient magnitudes during training. Piecewise linear avoids all of this.
Idea 3: Use NeRF rendering as the self-supervised training signal
The triplane needs a training signal that forces it to encode correct 3D geometry — not just 2D texture statistics. Volumetric rendering is the natural choice: to correctly render a pixel from a novel viewpoint, the 3D representation must be geometrically correct. Multi-camera setups are ideal because each camera supervises the same triplane from a different angle.
Why not other approaches:
- MAE masking: purely 2D, model can cheat with texture, no geometric consistency enforced
- CLIP/contrastive: requires paired data, collapses toward global embeddings, loses spatial structure
- DINO self-distillation**: spatially rich features, but no explicit 3D geometric constraint
- Gaussian Splatting: variable Gaussian count → variable token count, breaks fixed tokenization
NeRF rendering is not novel here — SelfOcc uses the same idea for occupancy prediction. The novelty is applying it to produce tokens for a downstream AR policy.
No GAN loss needed
Pixel-wise losses produce blurry outputs because they optimize for the mean of the distribution. LPIPS (perceptual loss in pretrained feature space) is sufficient to avoid this without the training instability of a GAN. This matters because VQGAN-style baselines require GAN training which is notoriously finicky.
Idea 4: Decouple patchification from training
Tokenizing the triplane (splitting planes into patches → MLP → tokens) happens after triplane creation and is not part of triplane training. This means patch sizes can be changed post-training as a free inference-time knob — more aggressive patchification = fewer tokens = faster but slightly less accurate. No retraining needed.
Idea 5: Drop unused triplane regions (halfplane trick)
When using only front-facing cameras, the rear halves of the xy and xz planes model space the vehicle never observes. These regions can simply be dropped.
Implementation
Triplane construction (from TPVFormer)
- Encode each camera image through a backbone to get a 2D spatial feature map
- Initialize a grid of 3D query points
- Queries attend to image features via deformable attention, using camera intrinsics/extrinsics for 3D→2D projection. Sinusoidal positional encodings represent triplane grid locations
- Average updated queries along each spatial axis →
Why the encoder must output a spatial feature map
Deformable attention looks up features at specific image coordinates derived from a 3D→2D projection. This only works if the feature map preserves spatial structure — each position must correspond to a meaningful image region. Both CNNs and ViTs satisfy this (see the ViT note for why attention preserves token-to-position correspondence). A global bottleneck like a VAE latent vector would destroy spatial correspondence and break the projection.
Encoder choice: DINOv2-small (22M params) — ViT-based, internet pretrained, produces spatially rich per-patch features. ResNet50 works too and gets slightly better PSNR, but slower inference.
Bilinear coordinate warping
For axis x, a grid coordinate maps to ego-relative coordinates with:
where and are inner and outer resolutions (m/cell). Z-axis is handled asymmetrically since there is no space below ground.
Concrete config: , , . Covers ±180m in x/y, −3m to +45m in z. Inner region: cells (±80m).
Training loss
with .
To render : sample rays → project each 3D sample point onto all three planes → bilinear interpolate → elementwise product to aggregate features → lightweight MLP decodes to color + density → standard volumetric rendering integral.
Tokenization
Each plane is patchified and projected to AR dimension:
A single-layer MLP projects from . for the 1B backbone used in experiments.
Patch size configs evaluated:
- : 104 tokens/image, matches baseline inference speed
- : 45 tokens/image, ~50% faster than baselines
Discrete tokens via FSQ were attempted but underperformed continuous tokens — dropped.
What’s Actually Novel
Honest assessment: TPVFormer’s triplane construction + SelfOcc’s NeRF rendering loss, applied to tokenization instead of occupancy. Modest conceptual leap.
Genuine contributions:
- Halfplane trick — simple, practically useful
- Patchification decoupled from training — free post-training inference knob
- Empirical demonstration that patch tokenization is architecturally wrong for multi-camera AV — the camera-count agnosticism experiment makes this case cleanly
Limitations and Future Work
- Per-timestep only — no temporal modeling across triplane states. Natural extension: generate future triplane states directly as a world model (video diffusion in triplane space)
- Discrete tokens failed — limits LLM vocabulary compatibility
- Triplane size / feature dimension compression unexplored
- Tokenizer latency not yet optimized for on-vehicle deployment (TensorRT, pruning)