The note comes out from my conversation with Claude Sonnet 4.6
One-line summary
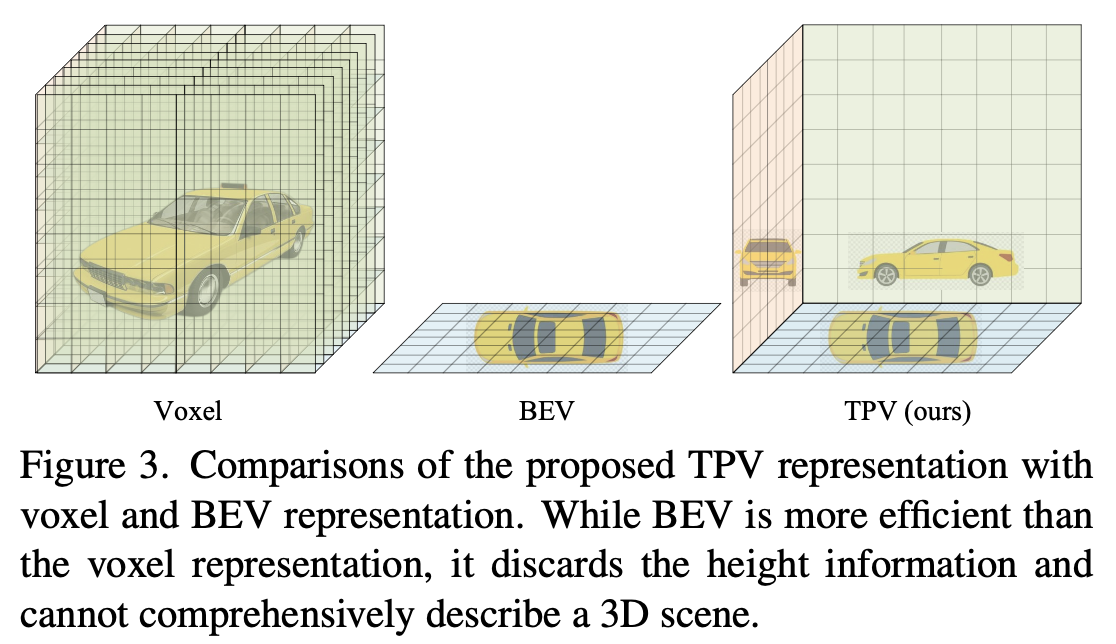
Three orthogonal BEV-like planes (top, side, front) whose features sum to reconstruct any 3D point feature — a lightweight factored voxel representation, encoded by a BEVFormer-style transformer with added cross-plane attention.
The paper is inventing too many too many things and overcomplicates stuff with no good illustration. I don’t like the writing style.
The Core Representation: TPV
The central idea is a generalization of BEV from one top-down plane to three mutually orthogonal planes:
| Plane | Axes | Captures |
|---|---|---|
| top-down | x–y layout, road structure | |
| side view | z–x depth + height | |
| front view | y–z width + height |
The feature at any 3D point is reconstructed by projecting onto all three planes and summing:
The key insight
This is essentially a rank-1 Tucker decomposition of a full voxel volume along three axes. Storage drops from to — an order of magnitude cheaper, yet any 3D point can still be queried on demand.
BEV ignores vertical variation entirely. TPV diversifies point features along each plane’s orthogonal axis by drawing from the other two. Each plane only has to encode its own view-specific pillar information, not the complete scene.
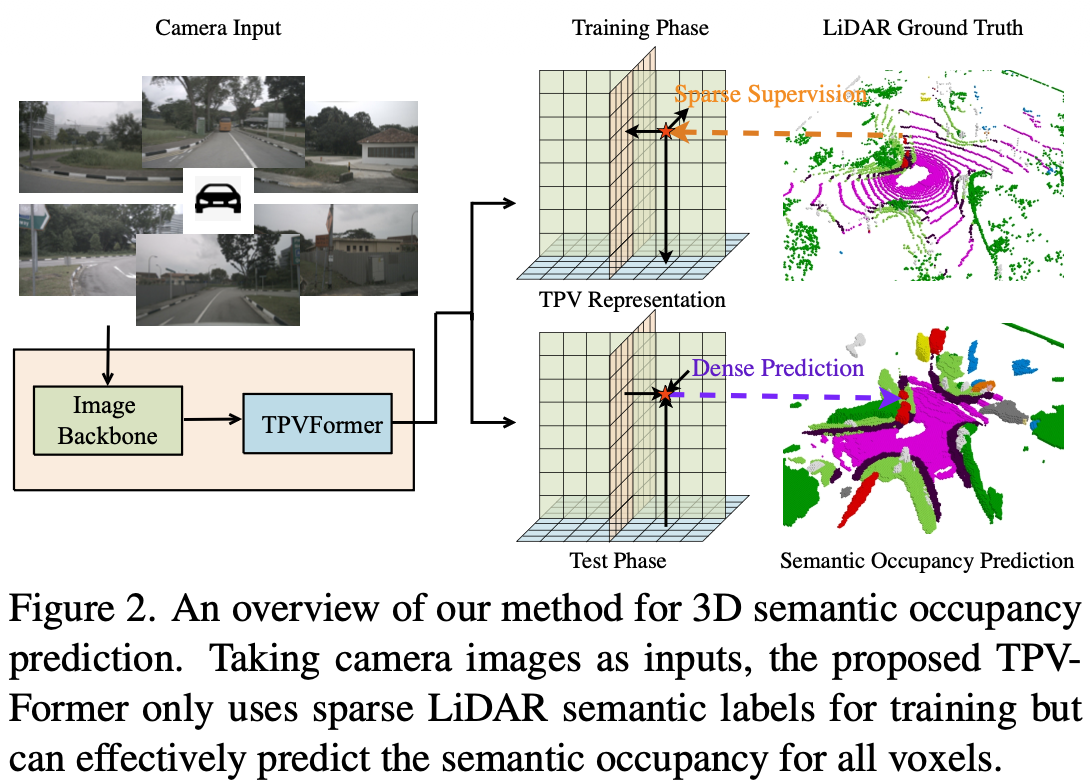
TPVFormer: The Encoder
TPVFormer is best understood as ==BEVFormer applied to three planes simultaneously, with a cross-plane attention module added==.
Two attention primitives
ICA — Image Cross-Attention The 2D→3D lift. Each TPV query knows its 3D pillar location. ICA samples reference points uniformly along that pillar, projects each into every camera’s image plane via the camera extrinsic/intrinsic, then aggregates image features using deformable attention. This is exactly BEVFormer-style cross-attention, applied to all three planes.
Lineage
This is not new. ICA is essentially identical to the spatial cross-attention in BEVFormer and the image-to-BEV lifting in BEV baseline. The shared recipe:
- For each 2D grid query, convert to real-world coordinates
- Sample 3D points along the pillar perpendicular to the plane — covering all heights since the relevant surface depth is unknown
- Project each 3D point into every camera via extrinsic + intrinsic to get a 2D pixel location
- use that pixel location as the deformable attention center, with learned offsets and weights predicted from the query itself
- cameras where no projected point lands on the image are discarded, and the valid-camera count normalizes the result.
TPVFormer’s only extension is applying this to all three planes, not just the top-down BEV plane.
CVHA — Cross-View Hybrid-Attention The cross-plane talk. A top-plane query at corresponds to a pillar that also intersects the side and front planes at specific cells. CVHA groups reference points into three disjoint subsets — one per plane — and attends to all of them in a single deformable attention call:
“Hybrid” here means attending across multiple views in one pass — not mixing attention types. The keys and values are the TPV planes themselves.
Two block types

The ordering is deliberate. Queries start as random noise, so early layers need ICA to bootstrap with actual image content. Once queries have absorbed enough visual information, further image lookup adds less; HAB layers then refine through cross-plane context exchange alone.
Why this complexity is necessary
The deformable attention requires explicit reference points. Because there is no implicit spatial inductive bias in attention, the 3D→2D geometry has to be computed and injected manually — that’s what makes ICA look complicated. CVHA then just applies the same deformable mechanism but with the three planes as keys/values instead of image feature maps.
Output: Point and Voxel Features
The output head is surprisingly minimal.
Point query (LiDAR segmentation): Given a point , project onto all three planes, bilinearly sample the plane features, sum:
Pass through a 2-layer MLP → semantic label.
Dense voxel (occupancy prediction): Broadcast each plane along its missing axis to produce three tensors, sum them, apply the same MLP at every voxel location. Same per-point operation applied everywhere at once.
Elegant factoring
The broadcast+sum in dense mode is exactly the same math as the point query mode — just applied to every grid cell simultaneously. There is no separate decoder, no FPN, no upsampling network.
Key Results and Findings
- Camera-only model reaches ~70% mIoU on nuScenes LiDAR segmentation, competitive with most LiDAR-based methods. This is the headline result.
- Trained on sparse LiDAR labels only — no dense voxel ground truth. The model learns dense occupancy from sparse point supervision, which is practically significant.
- Resolution >> channel depth (Table 4): doubling plane resolution outperforms doubling feature dimension. Spatial precision matters more than feature richness here. Useful design principle for adaptation.
- HCAB count matters more than HAB count (Table 5): confirms ICA is doing real work; CVHA alone cannot substitute for image grounding in early layers.
Discussion Notes
Known failure mode
The rank-1 factorization breaks down for scenes with strong axis interactions — e.g. vertically stacked objects at the same footprint. The model can’t represent features that require non-decomposable interactions between all three axes simultaneously. See Figure 7 in the paper.
What's genuinely good
The additive reconstruction is clean and principled. Each plane is only responsible for its own view-specific pillar information, which keeps the representation efficient while the cross-plane attention allows global context to propagate across views.