Notes written by Claude (Opus 4.8) from a reading discussion.
D4RT (CVPR 2026 best paper) does 4D reconstruction from a single video — depth, point clouds, 3D point tracks, and camera parameters for dynamic scenes, where moving objects break the rigid-world assumption most 3D reconstruction relies on.
Its one new idea is a unified query interface: every task becomes the same question — “where in 3D is 2D point from source frame , seen at target time , in camera ‘s frame?” — answered by a decoder cross-attending into a frozen scene representation. That reframing is what lets one model do dynamic correspondence (which VGGT structurally cannot) and unlocks an efficient dense-tracking algorithm. The rest is recombination: a VGGT encoder (initialized from VideoMAE — load-bearing, see What the results lean on) feeding an SRT-style cross-attention decoder.
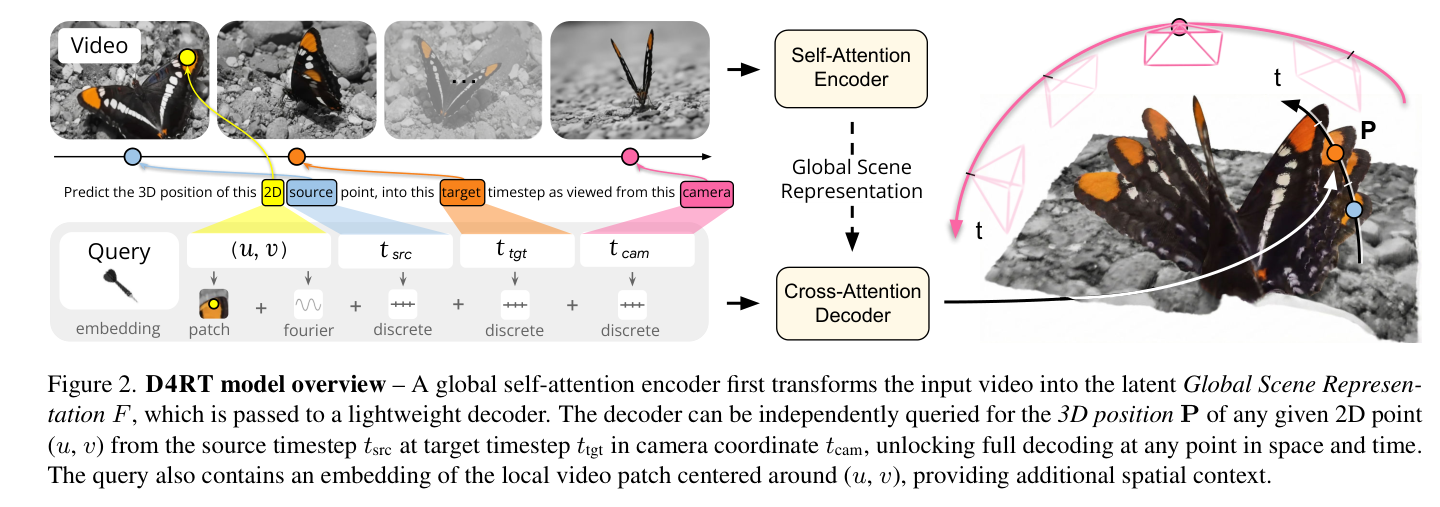
Everything is one query
The query is decoded independently against the frozen scene representation into a 3D point . The three temporal indices are free, independent parameters — so every 4D task is just a slice of the Cartesian product:
| Task | vary | fix |
|---|---|---|
| Point track | one | |
| Point cloud | all , all | fixed (one world frame) |
| Depth map | all | , keep only Z |
| Extrinsics | grid, two | → Umeyama between the two point sets |
| Intrinsics | grid | pinhole equation on predicted points |
Depth is the identity case (, keep Z); point cloud predicts every pixel directly in one shared frame, sidestepping the noisy per-frame stitching that pairwise methods (DUSt3R lineage) need.
Why the query works
Dynamic correspondence is the capability no dense decoder has. VGGT’s tracking assumes the same 3D point across views (rigid world) — a moving leg breaks it. D4RT’s query has time built in, so “where did this pixel go” is one forward pass; vary for the whole trajectory.
The decoder answers each query independently, and that buys three things: cheap sparse training (~2048 queries/clip vs. dense ), free add/drop of queries (what makes Algorithm 1 possible), and — crucially — a stronger encoder. They found query-to-query attention hurts: forcing every query to be answered cold from alone pushes all scene understanding into the encoder. It’s the mirror image of VGGT’s over-complete prediction — both make the shared representation carry the full geometric burden.
It’s VGGT + SRT
The encoder is VGGT unchanged (ViT-g, interleaved frame-wise + global attention over spatio-temporal patches), initialized from VideoMAE. The encode-then-query framing — a “Global Scene Representation” you cross-attend into — is SRT (Scene Representation Transformer, Sajjadi et al. 2022): SRT encodes posed images into latents and queries them with rays for color. D4RT swaps the ray query for a spatio-temporal point query and outputs 3D position instead of RGB.
Placing it in the NeRF → SRT → D4RT lineage
Two axes, not just “more tasks”:
- Richness of use: SRT (one renderer) → VGGT (task-specific heads) → D4RT (one query interface subsuming all tasks).
- What forces geometry: SRT supervises RGB (geometry stays implicit); D4RT supervises 3D points directly (geometry explicit from the start).
On those axes: SRT = implicit + appearance, TriPlane Tokenizer = explicit + appearance (triplane, but trained by NeRF-style rendering), D4RT = implicit + geometry; VGGT sits between SRT and D4RT. Shared template throughout: encode multi-view observations into a scene rep, then query it.
- NeRF: per-scene MLP, ray-marched. No generalization.
- SRT: learned encoder + ray query for color. NeRF’s task, feedforward.
- D4RT: point query → 3D position, no rendering anywhere.
One consequence of D4RT’s implicit : it has no spatial coordinates, so you can’t look up a feature by 3D position (unlike a triplane) — the decoder is mandatory.
Two design choices that carry the results
Local RGB patch → sub-pixel detail
Each query also gets a Fourier embedding of and the local RGB patch at — the cheap analog of DPT’s skip connections. Not minor: AbsRel(S) , ATE (Table 7). The real payoff (App. C): since is continuous, decoding resolution decouples from encoding resolution — feed full-res patches while the encoder stays at and recover sub-pixel detail (hair, sharp boundaries; PDBE ). VGGT’s DPT head can’t do this.
Cameras for free (no camera head)
Both recovered analytically from point predictions: intrinsics from the pinhole model on a decoded grid (, median-pooled); extrinsics by decoding the same grid at two values and running Umeyama (3×3 SVD) between the two point sets. This is the inverse of VGGT’s over-complete prediction: VGGT predicts cameras+depth+points jointly to force consistency; D4RT predicts only points and derives cameras by algebra. The point head is the camera head.
Dense tracking as a coverage problem
Tracking every pixel naively is . Instead, a track from marks every spatio-temporal pixel it visibly passes through as done in an occupancy grid , so new tracks start only from unvisited pixels. Adaptive 5–15× speedup (more for static scenes, which have more redundancy); 18–300× more full-video tracks than DELTA/SpatialTrackerV2 at fixed FPS (Table 3). Only possible because queries are independent and cheap.
\begin{algorithm}
\begin{algorithmic}
\REQUIRE Input video $V$, encoder $\mathcal{E}$, decoder $\mathcal{D}$
\STATE $F \gets \mathcal{E}(V)$ \COMMENT{Global Scene Representation}
\STATE $G \gets \{\textbf{false}\}^{T\times H\times W}$ \COMMENT{Occupancy grid}
\STATE $\mathcal{T} \gets \emptyset$ \COMMENT{Set of dense tracks}
\WHILE{$\textbf{any}(G = \textbf{false})$}
\STATE Sample a batch $B$ of unvisited source points from $G$
\FOR{each $(u,v,t_\text{src}) \in B$ \textbf{in parallel}}
\STATE $Q \gets \{(u,v,t_\text{src}, t_\text{tgt}{=}k, t_\text{cam}{=}k)\}_{k=1}^{T}$
\STATE $P \gets \{\mathcal{D}(q_k, F)\}_{k=1}^{T}$ \COMMENT{Run decoder}
\STATE Mark $\textbf{Visible}(P)$ pixels as visited in $G$
\STATE $\mathcal{T} \gets \mathcal{T} \cup P$
\ENDFOR
\ENDWHILE
\RETURN $\mathcal{T}$
\end{algorithmic}
\end{algorithm}
What the results lean on
The headline numbers are a VideoMAE fine-tune
Without VideoMAE init the model collapses — ATE , AbsRel(S) (Table 11). The VGGT+DINOv2 comparison is fair-ish (both lean on internet-scale pretraining), but VideoMAE is video pretraining vs. DINOv2’s static images — a more task-appropriate foundation. Open question (same as the VGGT note, DINOv2 → DINOv3): how much of D4RT’s edge is the query architecture vs. the backbone? Not controlled for.
Smaller print
- Auxiliary losses help — and echo VGGT. 2D position, normals, displacement, visibility, confidence each improve results (Table 8) — same mechanism as VGGT’s over-complete prediction, but as linear projections discarded at inference. Trade-off: dropping the confidence loss slightly helps depth but wrecks pose.
- Confidence loss ⇒ optimum : calibrated uncertainty learned jointly with accuracy (Kendall & Gal; see Uncertainty based learnable weighting). The 3D L1 is on depth-normalized points through to stop far points dominating.
- Two unablated tricks: 30% of queries oversampled near depth/motion boundaries (Sobel); with prob 0.4 (the easy identity case). Stated as fact; likely matter for reproduction.
- Scale/training: ViT-g encoder ≈1B params, decoder 144M (so “lightweight” = the decoder). Kauldron; 48-frame clips, 2048 queries; AdamW, 500k steps, 64 TPU chips, ~2 days. Training data includes Waymo Open (relevant for driving-scene comparisons vs. VGGT).
- Long videos (App. B): overlapping segments stitched by Umeyama on high-confidence overlap points, no loop closure (unlike VGGT-Long). Best ATE on KITTI 1000-frame sequences.