*Note written by Claude Sonnet 4.6 from a reading discussion on 2026-05-24.
Alpamayo-R1
NVIDIA’s AV system paper. A VLA that thinks in natural language before predicting a trajectory. The dual-representation backbone is borrowed wholesale from π0.5-KI — the architectural mechanism is not new. The contribution is upstream and downstream of that: a Chain of Causation (CoC) labeling protocol that makes reasoning traces actually causally honest, and a multi-reward RL stage where one reward — the consistency between the trace and the action — turns out to do almost all the work.
TLDR
Take π0.5-KI’s dual representation (discrete tokens for backbone training, flow matching for inference, stop-gradient between them). Bolt on a reasoning layer in front of the trajectory tokens. Train in three stages: (1) action modality injection → Alpamayo-VA, (2) SFT on CoC traces, (3) GRPO with three rewards. Most of the rest of the paper is plumbing.
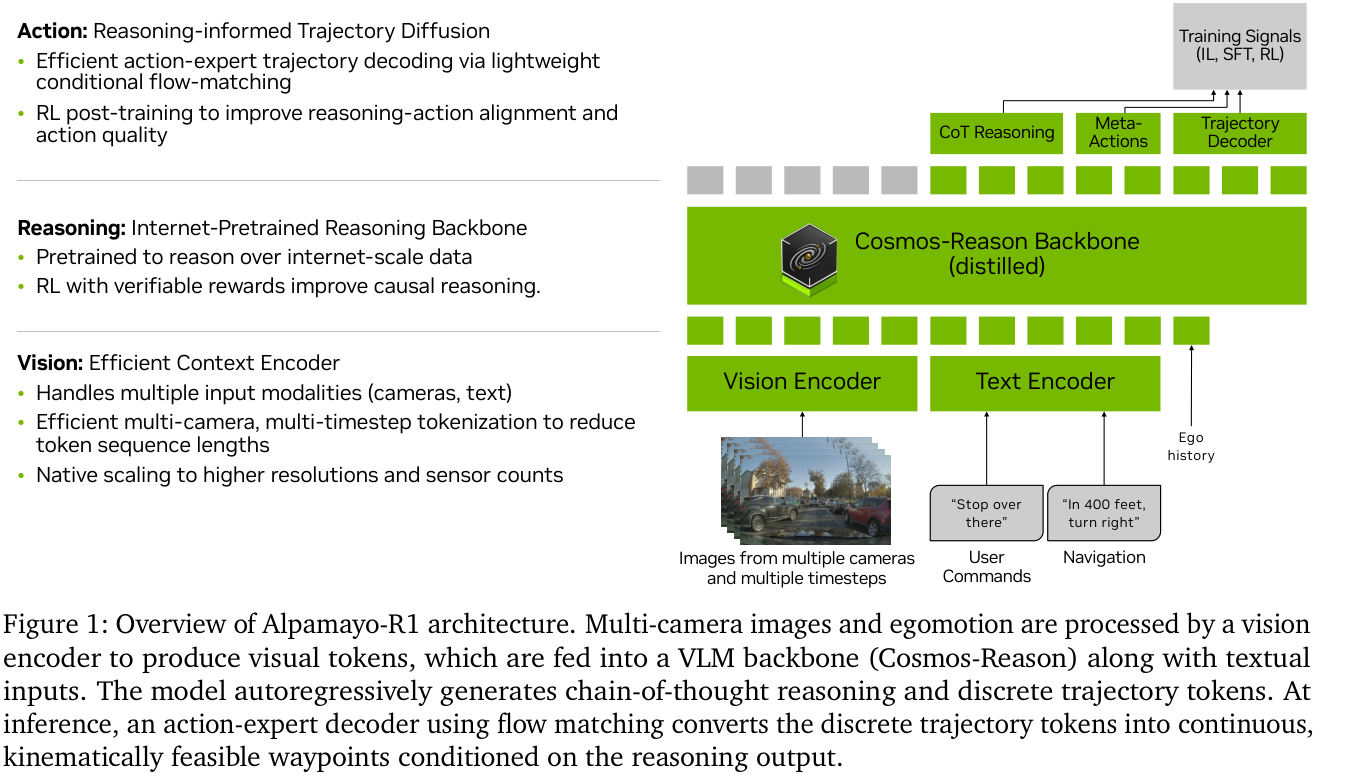
What’s actually new (vs π0.5-KI)
The borrowed pieces: dual representation + stop-gradient training, flow matching action expert, the whole “use discrete tokens as a surrogate training signal for the backbone without letting the random-init action expert corrupt it” trick. AR1 even ablates against this in Table 9.
AV-specific adaptations that the paper sometimes frames as design choices but are really just standard practice:
- Unicycle dynamics (control inputs instead of waypoints). Exact analog of robotics outputting joint velocities rather than Cartesian end-effector targets — guarantees kinematic feasibility, matches what the downstream MPC controller consumes. Standard AV motion planning for decades.
- Multi-camera surround + TriPlane Tokenizer / Flex for vision compression. Token count engineering. Necessary for real-time, not the contribution.
- Naive uniform binning instead of FAST tokenization. The π0.5-KI paper actually shows FAST is better; AR1 accepts the regression because their 64-step (acceleration, curvature) sequence is lower-dimensional than robot joint control.
The genuinely novel pieces:
- Chain of Causation labeling — a way to write training-quality reasoning traces that don’t leak future information and don’t decouple from the action.
- The consistency reward — the load-bearing component of the RL objective.
Chain of Causation: constrain the conclusion, not the language
Prior AV reasoning datasets produce traces that look reasonable but don’t connect to the trajectory. Three failure modes the paper calls out:
- Vague decisions — “be cautious”, “watch out for X” doesn’t specify what the car does.
- Superficial reasoning — cites contextual facts (wet road, sunny weather) with no causal link to the ego decision.
- Causal confusion — labeler watches the full video and references future events not yet observable at the decision moment.
A model trained on these learns to sound plausible without learning to reason. The fix is constraint design: anchor every trace to an explicit driving decision from a closed taxonomy (~15 longitudinal options × ~15 lateral, see Table 1), and require all causal factors to come only from the observable history window.

Closed decisions ≠ closed reasoning
The conclusion is a fixed vocabulary; that’s what aligns the trace to the trajectory. The reasoning path (which causal factors, how they interact) stays open-ended natural language. The expressive-power concern only applies to the decision label, not the trace. Closer to supervised classification on the action with free-form rationale than to a templated reasoning chain.
Annotation mirrors inference conditions to prevent causal leakage: labelers see only the 0–2s history window when identifying causal factors (Stage I), then see the future video when selecting the driving decision (Stage II). ~10% human-labeled (SFT + eval), ~90% auto-labeled by GPT-5 with the same two-stage prompt logic. The keyframe is placed ~0.5s before the behavior change so the future hasn’t happened yet at the decision moment.
The consistency reward is doing all the work
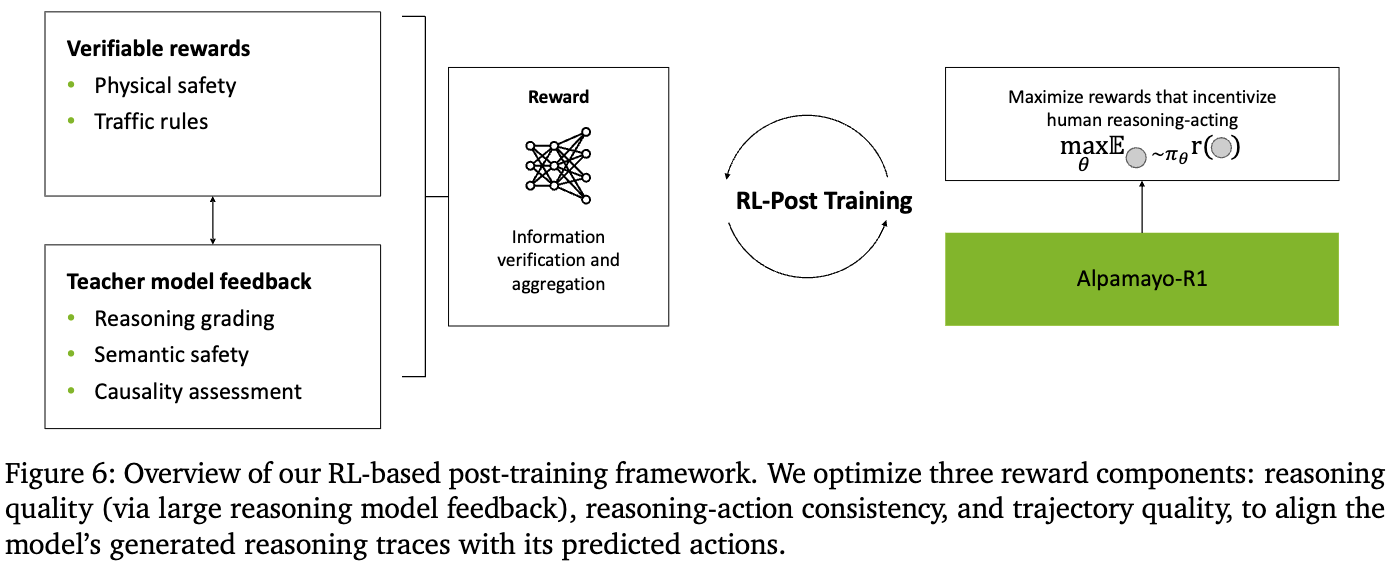
Three rewards in the GRPO stage:
- Reasoning quality — LRM critic (DeepSeek-R1 / Cosmos-Reason) grades the generated reasoning trace (the text, not the trajectory) against the labeled ground-truth CoC trace on a 0–5 rubric: behavior consistency (same driving decision?) + causal factor accuracy (same causes identified?).
- CoC-action consistency — parse the trace into intended meta-actions, parse the predicted trajectory into meta-actions via rule-based detector, check they agree. Binary. This is what bridges the text reward and the trajectory.
- Trajectory quality — L2 to expert + collision penalty + jerk. Graded on the trajectory only.
Table 9 is the most important table in the paper. Optimizing reasoning quality alone degrades ADE (2.12→2.19m) and consistency (0.62→0.53) — the model learns to produce fluent reasoning that’s causally disconnected from its actions. Classic reward hacking, just in language space. The consistency reward isn’t an add-on; it’s what makes the reasoning reward not harmful.
Why L2 in RL is different from L2 in SFT
In SFT the loss runs under teacher forcing — the model always sees ground truth context and never has to recover from its own distribution. In RL it’s computed on on-policy rollouts, directly addressing the train/inference distribution shift. Same mathematical form, different signal.
Does RL actually reach the flow matching expert?
GRPO operates on the discrete token head. The flow matching expert sits behind a stop-gradient and receives no direct RL gradient. It only benefits indirectly: RL improves discrete token predictions → backbone representations adapt → KV-cache improves → action expert produces better continuous trajectories, hopefully.
That “hopefully” is the gap. The paper reports ADE improvements from RL, but ADE is measured using the flow matching decoder, and the paper never disentangles whether the gain comes from improved backbone KV-cache propagating through, or something else. The assumption that backbone improvement propagates faithfully through stop-gradient is never tested.
Contrast with π0.6 RECAP / CFGRL
Both papers face the same problem: flow matching doesn’t give clean log π(action|state) for policy gradient methods. AR1 sidesteps by maintaining a parallel discrete representation that GRPO can chew on, accepting the train-inference mismatch. CFGRL recognizes that classifier-free guidance scale is already a policy improvement operator and learns to modulate it via reward — RL acts directly on the inference-time model. More principled, more complex. AR1 is simpler engineering that rests on the unverified propagation assumption.
The RL data curation argument is shaky
The proposed scheme: prioritize samples where the model’s implicit reward (logits) most disagrees with the Boltzmann reward distribution. Conceptually the continuous analog of the DPO insight — log vs reward divergence is exactly where preferences are miscalibrated. Compelling.
But the cost-saving argument doesn’t quite work:
Two unresolved issues
- Offline vs online? Section 5.3.3 is ambiguous. If online (re-curate each iteration), you’re paying full LRM inference cost on the candidate pool every time — backprop was never the bottleneck. Nothing is saved. If offline (one-shot before RL), it amortizes, but then —
- Scenario selection grows stale. The Boltzmann disagreement was computed under the SFT model. As GRPO training progresses, the policy drifts and the “high-information” set is increasingly information about a model that no longer exists. The paper doesn’t address either issue.
What the paper doesn’t address
- Whether the flow matching expert actually benefits from RL or only the token head does
- Whether ~15 longitudinal × ~15 lateral decision categories cover genuinely novel long-tail scenarios — the open-ended causal factors partially compensate, but the bottleneck is never stress-tested
- No ablation comparing the curriculum (Stage 1 then Stage 2) against a single joint SFT phase with both action-token and CoC-text losses on from the start. RL still has to come after, but the SFT split is a choice that’s never justified empirically.