The following notes come from my discussion with Claude Sonnet 4.6
Stable Diffusion 3 — Scaling Rectified Flow Transformers
Abstract
SD3 introduces the Multimodal Diffusion Transformer (MMDiT) — a rectified-flow model that treats text and image tokens as two parallel streams with separate weights but joint attention. Key contributions: (1) a careful empirical study of timestep sampling schedules, (2) the MMDiT architecture, (3) improved text conditioning via multiple encoders, and (4) resolution-aware positional encoding and timestep shifting.
1. Timestep Sampling: Why Log-Normal?
1.1 The Core Problem
Rectified flow trains with a uniform distribution over , but the prediction difficulty is not uniform across timesteps. At the extremes:
- : image is nearly clean → optimal prediction is just the mean of (trivial)
- : image is nearly pure noise → optimal prediction is the mean of (also trivial)
The hard, information-rich region is the middle, where signal and noise are genuinely mixed. We want to oversample it.
1.2 Log-SNR: The Natural Coordinate
For rectified flow with , , the log signal-to-noise ratio is:
is the natural axis for measuring difficulty: each unit of corresponds to a doubling/halving of the signal-to-noise ratio. At , — equal signal and noise. As , (all signal); as , (all noise).
1.3 Why Log-Normal Specifically
If prediction difficulty is roughly uniform per unit of — each octave of SNR deserves equal training — then we want uniformly distributed. Since , pulling back through the change of variables gives distributed as logit-normal: place a Gaussian on , then invert.
Concretely, the density is:
- Location : shifts weight toward data () or noise (). Default peaks at .
- Scale : controls width. Larger → flatter, closer to uniform.
- Tails vanish at 0 and 1: the denominator is the Jacobian of the logit transform — no wasted signal at the trivial endpoints.
1.4 Comparison: π Series Prioritizes Opposite End
SD3’s log-normal peaks in the middle because images need both coarse structure and fine detail — no strong asymmetry.
Pi 0 and the RECAP series (robot learning) do the opposite: up-weight high-noise timesteps (large , low SNR). For robot action generation, coarse trajectory correctness dominates — a wrong global motion plan fails the task regardless of fine detail. Fine denoising at small is cheap to recover from; coarse denoising at large is not. Opposite asymmetry from image generation.
Key takeaway
The right timestep distribution reflects the loss asymmetry of your task. SD3: symmetric → log-normal. Pi 0: coarse matters more → up-weight high noise.
2. Architecture: MMDiT
2.1 Overview
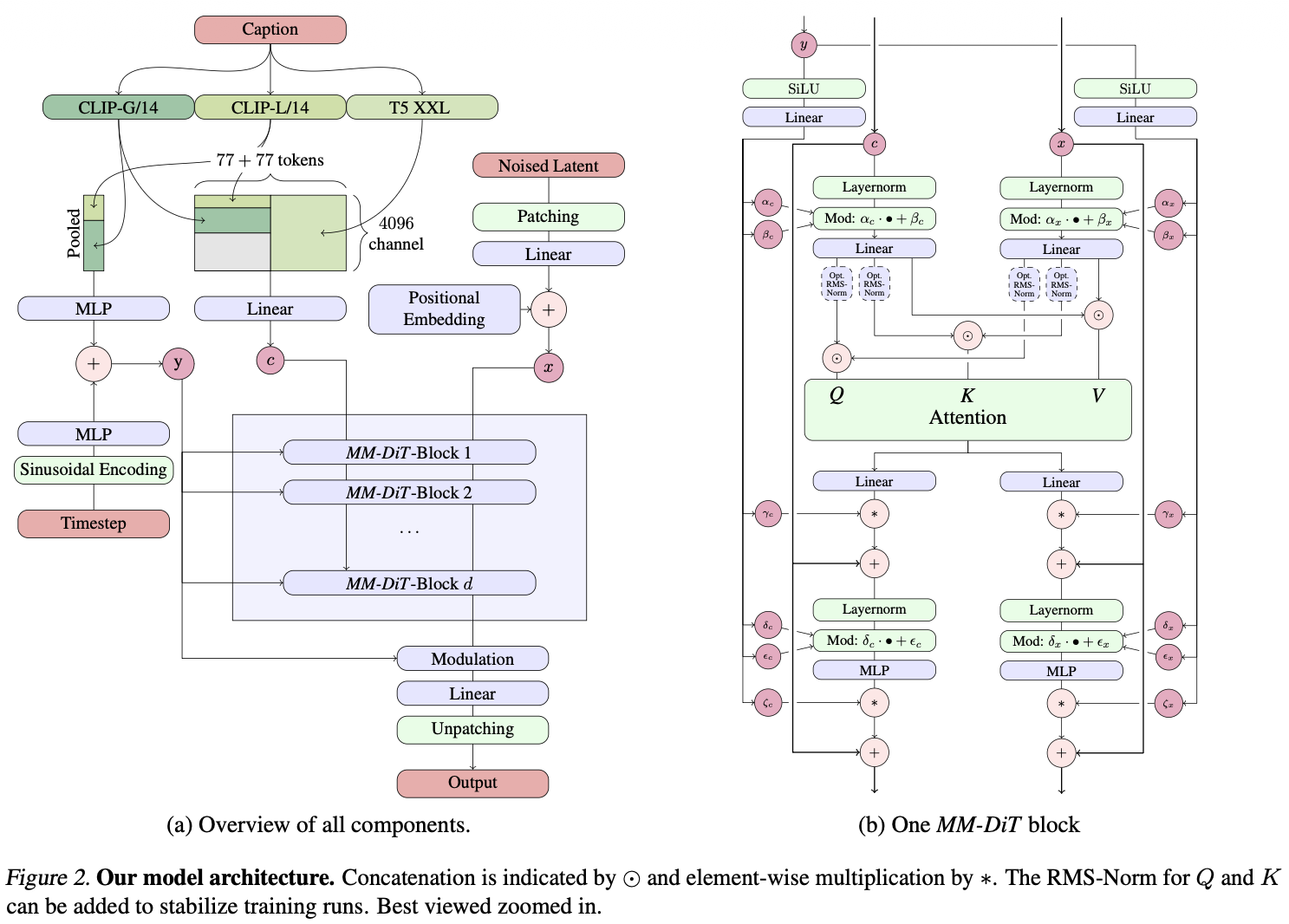
The architecture has three components: text conditioning, the MMDiT backbone, and the VAE. See DiT and Flow Matching for the underlying building blocks.
2.2 Two Conditioning Signals: c_vec → y and c_ctxt
The text is encoded by three frozen models and split into two representations with fundamentally different roles:
c_vec (pooled, global) → becomes y
CLIP-L and OpenCLIP-G pooled outputs are concatenated → . Combined with the timestep embedding, fed through an MLP to produce scale/shift/gate parameters of adaLN-zero at every MMDiT block.
- Carries: what kind of image is this? — holistic semantic gist
- The timestep naturally lives here too: also a scalar global signal
- Mechanism: modulates the gain and bias of every activation uniformly
c_ctxt (full sequence, local) → joint attention
CLIP penultimate hidden states (zero-padded 2048→4096) concatenated with T5-XXL hidden states → (77 CLIP + 77 T5 tokens). Concatenated with image patch tokens for bidirectional joint self-attention.
- Carries: which words say what, and where? — token-level spatial grounding
- Mechanism: cross-token attention lets patches route to relevant words
The 77-token limit on CLIP comes from its fixed positional embedding table (76 content positions + [EOS]). T5 is also truncated to 77 for uniform concatenation.
Do we actually need
y/c_vecin addition toc_ctxt?Honestly unclear. The pooled vector has a different representational character — CLIP’s
[EOS]token is contrastively trained for global image-text similarity, not token-level semantics. adaLN is also a cheaper and more direct broadcast path than attention.But there is no ablation isolating
c_vec’s contribution while keepingc_ctxt. It was inherited from SDXL (found empirically to help) and never seriously questioned. The timestep needs to live somewhere global — adaLN is the natural home — andc_vecis just concatenated to it cheaply.
2.3 MMDiT as Co-Attending Independent Streams
The dual-stream design is often loosely described as a hard-routed MoE, but the analogy is imprecise and worth unpacking. There is a spectrum of parameter sharing:
| QKV | Attention context | FFN | |
|---|---|---|---|
| Standard MoE | Shared | Shared | Separate (routed) |
| MMDiT / Pi0 | Separate per modality | Shared (K, V concatenated) | Separate per modality |
| Fully separate | Separate | Separate | Separate |
MMDiT is actually more separated than standard MoE, not a variant of it. Standard MoE’s logic is: tokens live in one shared representation space (shared QKV), but per-position computation specializes (separate FFN). MMDiT says: modalities have such different statistical characters that even the projection into Q/K/V space should be separate — but they still need to cross-attend.
The only joint operation is the attention context: each stream’s K and V are concatenated before softmax, so every token (text or image) attends over the full combined key-value set. A better name than “MoE” is co-attending independent streams — two fully independent weight sets that read each other’s working memory through attention.
Pi 0 uses the exact same mechanism — separate QKV weights per expert, concatenated for a single joint attention pass. See Pi 0 for implementation details and the distinction between the paper’s “blockwise causal mask” framing and what the code actually does.
2.4 Improved Text Encoders and Synthetic Captions
SD3 uses larger encoders than previous SD versions (CLIP bigG + T5-XXL vs CLIP-L alone). Training images are re-captioned using a separate VLM to generate dense, descriptive context labels — the model sees both the original human caption and the synthetic VLM caption at a 50/50 ratio. See Hi Robot for a similar synthetic captioning approach applied to robot data. The synthetic captions are more compositionally detailed and help the model learn fine-grained attribute binding.
3. QK Normalization
SD3 applies RMSNorm with learnable scale to Q and K vectors in both streams before computing attention logits.
The problem: when fine-tuning at higher resolutions, patch token count grows quadratically, attention logits grow unboundedly → entropy explodes → training diverges. First documented for large ViTs (Dehghani et al. 2023, ViT-22B).
Why it works: normalizing Q and K bounds all attention logits by , preventing softmax saturation and “winner-take-all” collapse.
Is it specific to diffusion models? No — but more critical for them. Variable resolution training creates extreme sequence length variation, triggering logit explosion more acutely than fixed-length LLM training. LLMs that use it: Gemma 2/3, OLMo 2, OpenELM. One notable incompatibility: QK-norm requires materializing full Q/K vectors, making it incompatible with MLA (DeepSeek’s multi-latent attention), where Q/K are reconstructed from low-rank factors at inference time.
Adopted as a headline change in SD3.5 (enabling stable 8B training), and present in Flux.1 (both doubleand single-stream blocks).
Tip
QK-norm constrains attention scores to a hypersphere — all comparisons become cosine similarities, bounded in regardless of depth or sequence length.
4. Positional Encoding for Varying Aspect Ratios
SD3 uses 2D sinusoidal frequency embeddings over a canonical coordinate grid. The challenge: embeddings must be physically consistent across aspect ratios — “far right” should mean the same thing in square, wide, or tall images.
The approach: build a canonical grid spanning the maximum extent across all aspect ratio buckets:
where is the latent size (after VAE + patching), is the tallest latent across all buckets, is target resolution. For any specific image, take a center crop of this canonical grid.
Why center-crop rather than interpolate? ViT-style interpolation distorts physical meaning — “position 50” means a different spatial fraction at different aspect ratios. Center-cropping from a fixed coordinate system preserves it: every position value corresponds to a fixed spatial distance regardless of image shape.
RoPE supersedes this
Flux.1 replaces sinusoidal absolute embeddings with RoPE — positions encoded as rotations of Q/K vectors, so only relative positions enter the attention score. The canonical-grid + center-crop mechanism becomes unnecessary. RoPE generalizes to unseen resolutions without any coordinate bookkeeping.
5. Resolution-Dependent Timestep Shifting
Core observation: the same destroys different amounts of signal at different resolutions. A model trained at is miscalibrated at .
Derivation via uncertainty matching:
Consider a constant image (every pixel = ) at resolution . Forward process: . To recover , average the pixels:
Higher resolution → more pixels → lower uncertainty at the same . Matching uncertainty :
For : , so — shift toward later timesteps (more noise) at higher resolution. In log-SNR coordinates, this is simply a constant translation: .
In practice, for training (found via human preference study), applied at both training and sampling time.
Note
The derivation assumes a constant image, which is unrealistic. It gives the right functional form; the exact is tuned empirically.
6. Subsequent Work (Brief)
- SD3.5: QK-norm added (enabling stable 8B training), dual attention layers per MMDiT block (or image-only self-attention in Medium variant, MMDiT-X). Same text encoders and VAE.
- Flux.1: hybrid of 19 dual-stream (MMDiT) + 38 single-stream blocks with shared weights. Replaces sinusoidal positions with RoPE. Drops CLIP-G. Adds guidance distillation. Dual→single stream progression: early layers need modality-specialized experts; later layers share capacity once representations have aligned.