The paper mainly focus on the dataset / experiment setup, and show that “it can work” as a system, toward generalist robot.
End result: a model that takes in images and pose, and can one shot easy tasks. Complex, longer horizon tasks needs fine tuning.
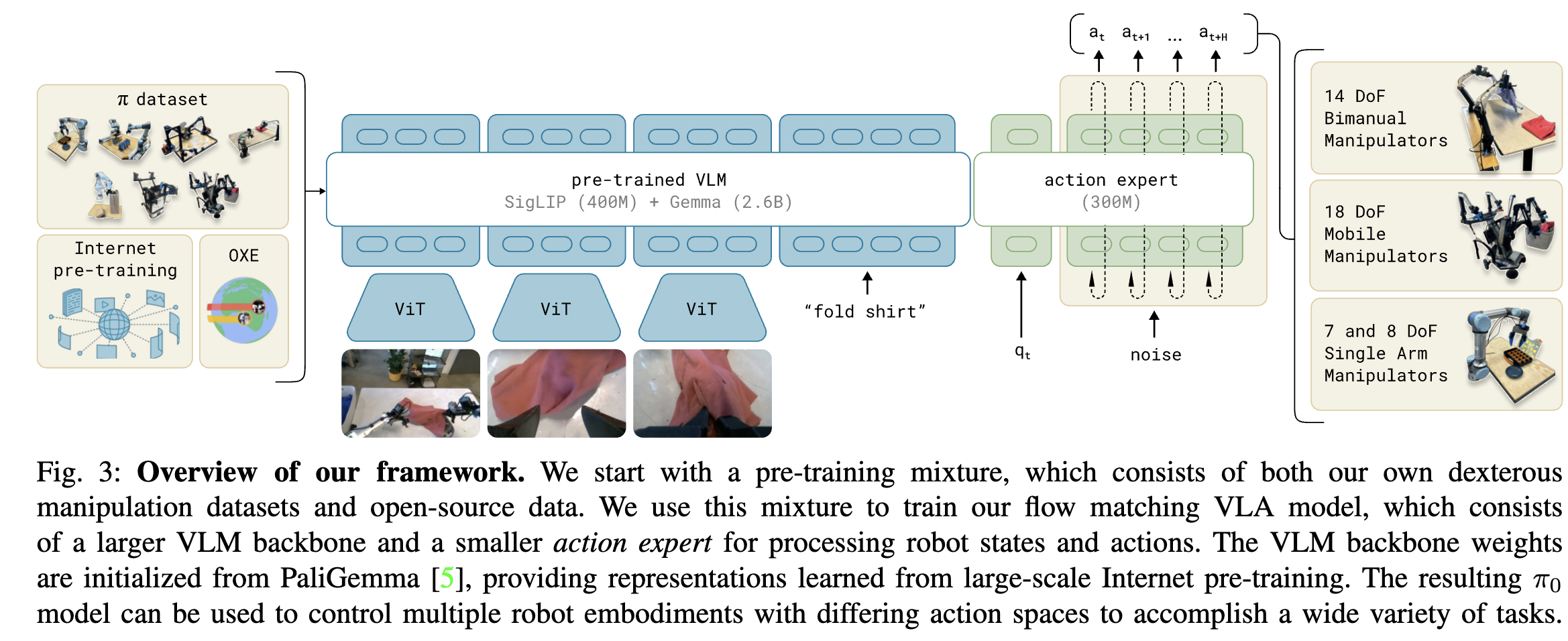
The model structure is heavily inspired by TransFusion for supervising continuous output with flow matching objective. Unlike that paper, a separate set of weights is used for robotics-specific (action and state) tokens. That’s why they called it the action expert: following MoE idea, but manual routing: all action input goes to that action expert.
Action expert. is implemented as a single transformer with two sets of weights (also known as experts), where each token is routed to one of the experts; the weights interact only through the transformer’s self-attention layers. The images and language prompt, , are routed to the larger VLM backbone, which we initialize from PaliGemma. The inputs not seen during VLM pre-training, , are routed to the action expert. PaliGemma is based on the Gemma 2B language model.
And then in inference the VLM output is just discarded.
As is shown in the image, they used a pre-trained VLM, PaliGemma. We then added an action expert, but note, it’s still on transformer.
Attention mask. π0 uses a blockwise causal attention mask with 3 blocks: , , and . Within each block, there is full bidirectional attention, whereas the tokens in each block cannot attend to the tokens in future blocks. The first block includes the input modalities from PaliGemma’s VLM pre-training, which are prevented from attending to future blocks (which include new inputs) to minimize distribution shift from said pre-training. The robot state qt is its own block because it does not change with each flow matching integration step; preventing it from attending to the final block allows its corresponding keys and values to be cached during sampling. The final block corresponds to the noisy actions , which can attend to the full input sequence.
Implementation: co-attending independent streams
The paper’s “blockwise causal mask” framing describes the access policy — which tokens can see which — not a separate architectural component. The actual mechanism, confirmed in openpi (src/openpi/models/gemma.py), is the same as MMDiT:
- Each expert computes Q, K, V with its own weights (VLM:
attn, action expert:attn_1) - Q, K, V are concatenated across both experts into a single sequence
- One standard attention computation runs over the full concatenated sequence
- The blockwise causal pattern is just a boolean attention mask on the logits
qkvs = []
for x, config in zip(xs, self.configs): # one iteration per expert
qkvs.append(qkv_einsum(config.weights, x))
q, k, v = (jnp.concatenate(y, axis=1) for y in zip(*qkvs))
# → standard attention with attn_mask appliedThe different hidden widths (VLM: 2048, action expert: 1024) are fine because both project to the same head_dim before the dot-product, then back to their own width for the FFN. The naming convention (attn vs attn_1) is what lets the PaliGemma checkpoint load without any remapping.
The blockwise causal mask itself encodes three practical choices:
- VLM tokens cannot attend to action tokens → preserves PaliGemma’s pretraining distribution
- State token
q_tcannot attend to action tokens → its K/V can be cached across flow-matching steps - Action tokens attend to everything → they have full context for denoising
We sample τ from a shifted beta distribution that emphasizes lower timesteps (corresponding to noisier actions), and does not sample timesteps at all above a cutoff value s. We use s = 0.999 in our experiments.
The model output is a “trajectory”, an action sequence of length 50, where each element is an action chunk. It’s unclear how the “chunk” is being defined. The loss is a conditional flow matching loss with a simple linear gaussian (or optimal transport) probability path.
In inference time, 10 integration steps are used with KV cache. Inference is open loop. Ensemble hurts performance.
Dataset
Intuitively, the diverse (but lower quality) pre-training data allows the model to recover from mistakes and handle highly varied situations, which might not otherwise occur in the high-quality post-training data, while the post-training data teaches the model to perform the task well.
Only 9.1% is from open-source datasets, while the rests are from their own datasets from various different robots of 68 tasks. The class imbalance is offset by weighing by . How suspicious that number is. They also use a subset from OXE, called “OXE Magic Soup”. Sus.
The experiment result shows that with pretraining, the model performs even better than the from-scratch version with fine tuning data. Using large VLM may be helpful, but it’s hard to tell if it’s because they use web scale data, or just because the model is large.