We’ll approach VAE with two prospective: one from intuition and engineering, which is based on this Blog post: all my images are from the blog. The other perspective is from Carl Doersch’s tutorial on variational autoencoders. Note how we did not approach the original paper as its framing can be hard to understand without prior knowledge.
The intuition
Auto encoder: easy, but may not produce what we want
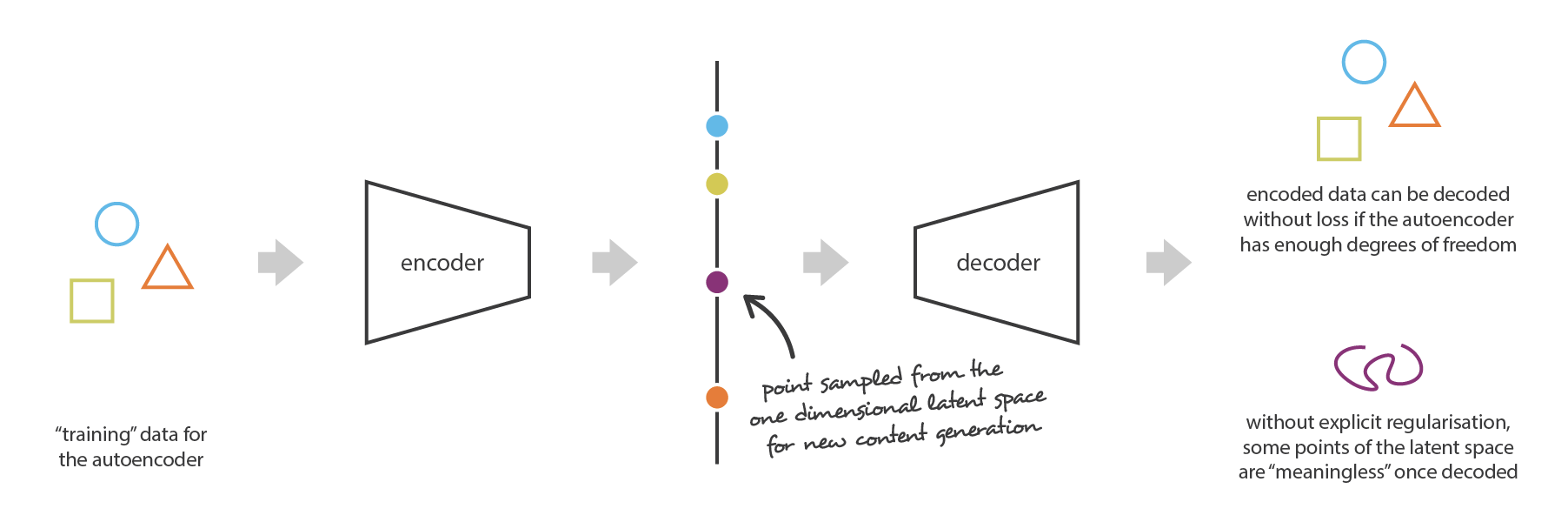
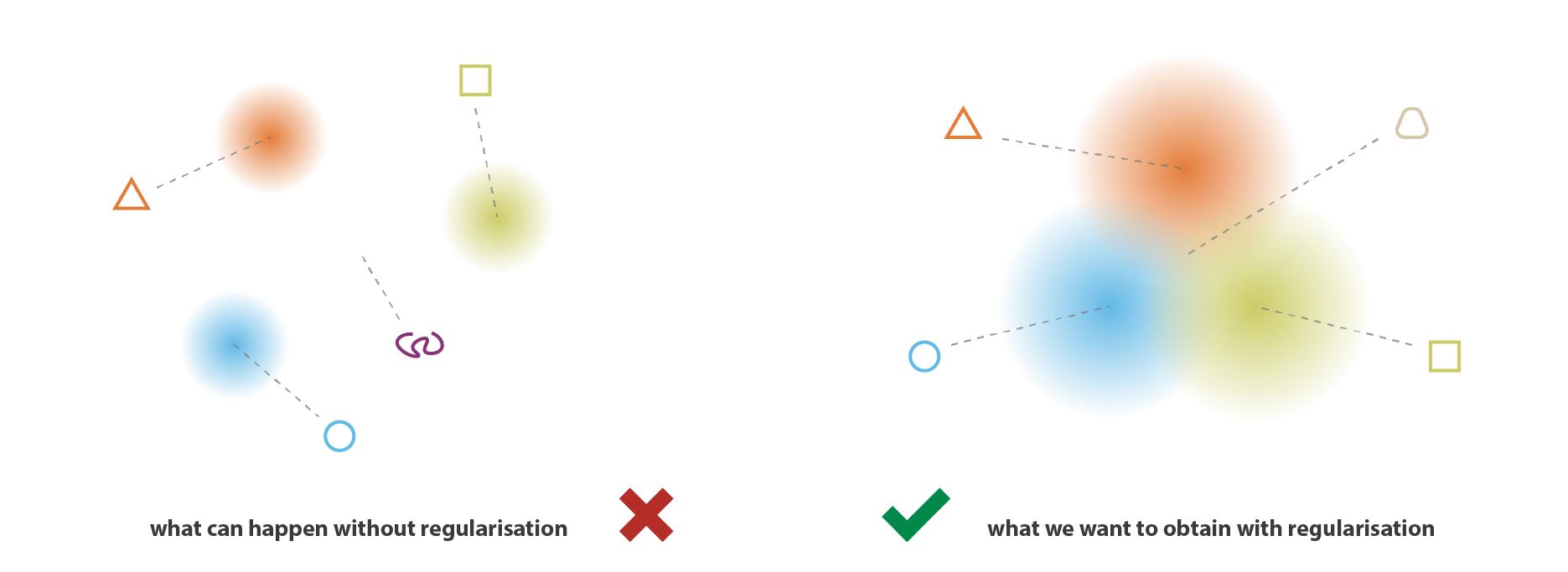
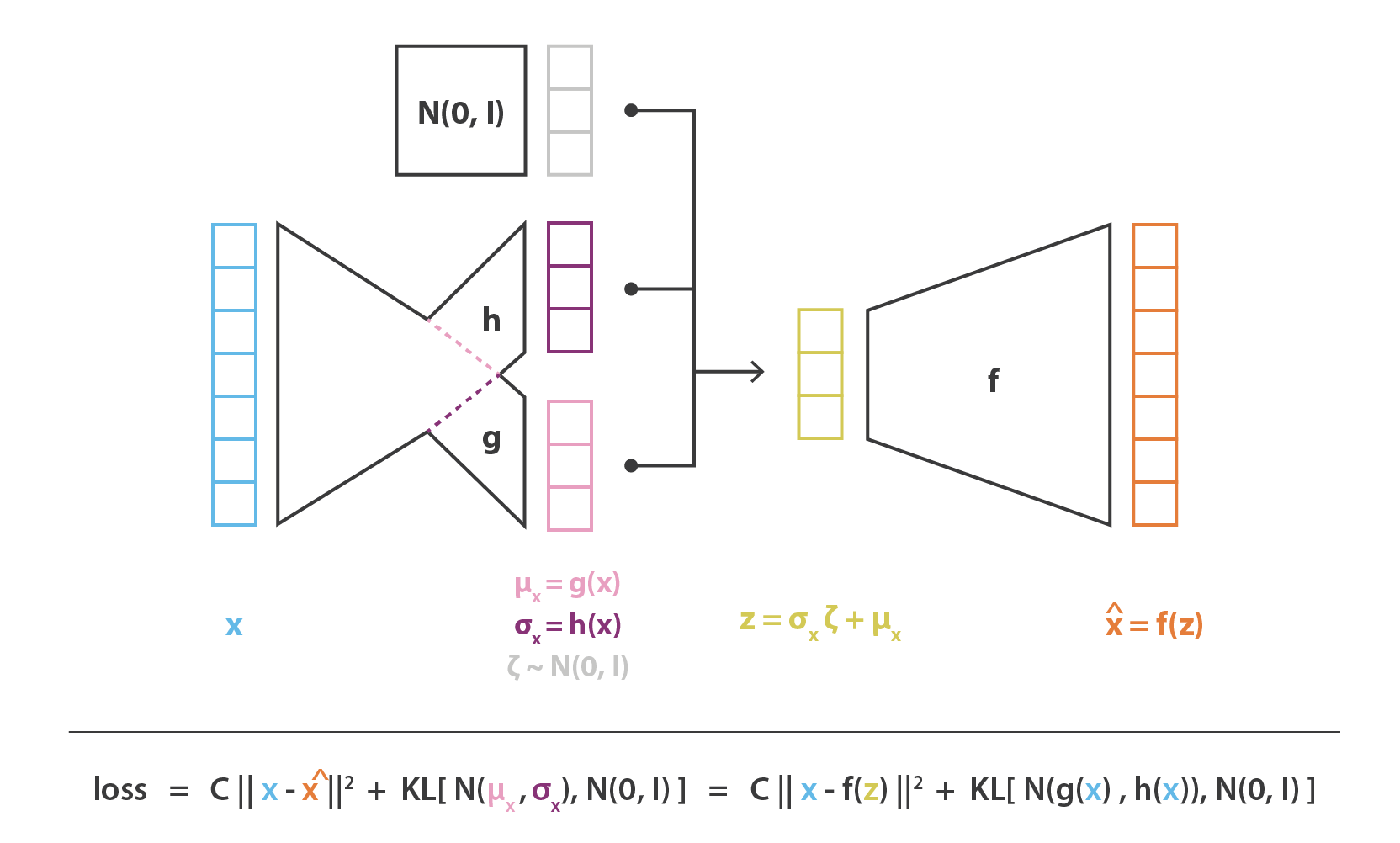
A variational autoencoder can be defined as being an autoencoder whose training is regularised to avoid overfitting and ensure that the latent space has good properties that enable generative process.
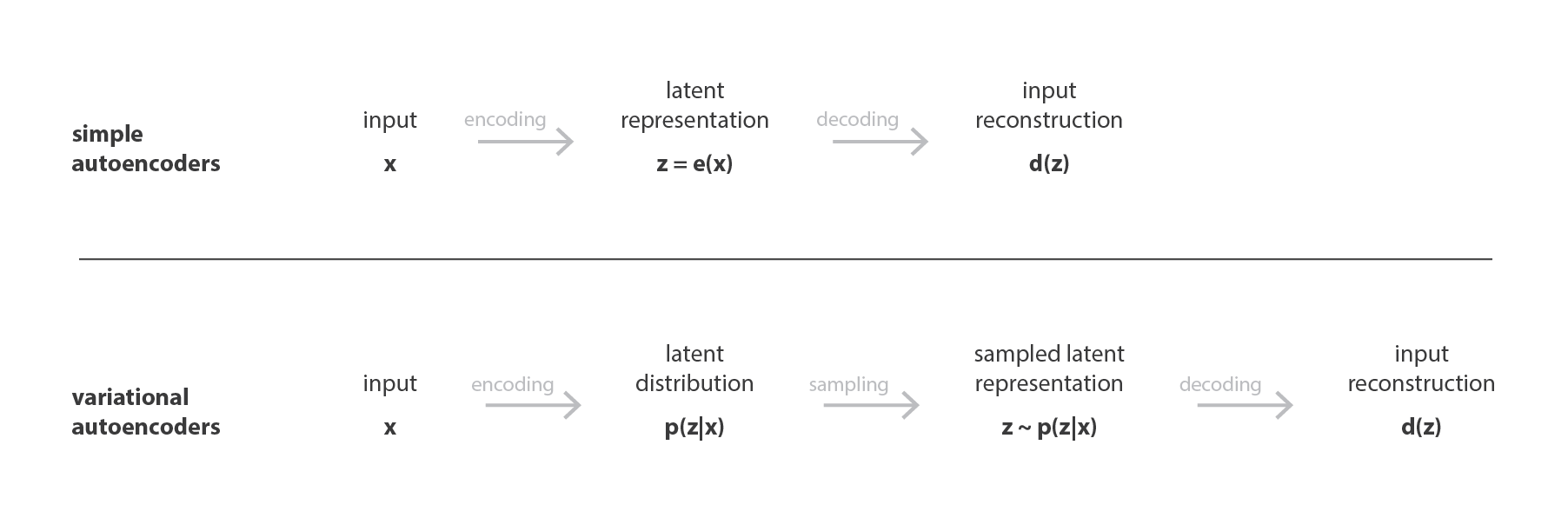
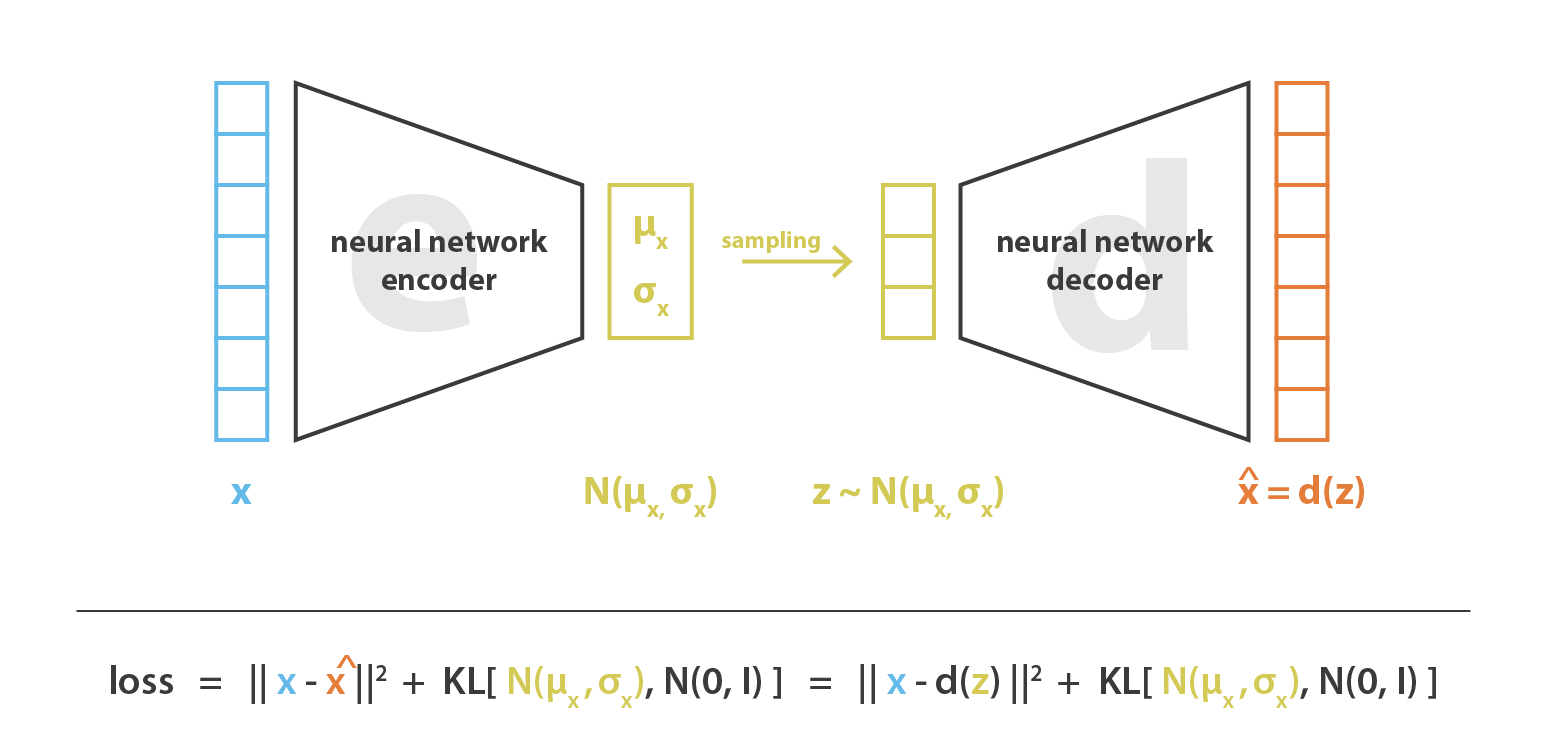
We want the distribution of encoder similar to a standard normal distribution (input → distribution → almost normal).
Note that and are both multi-dimension embeddings.
The rest of the note starts from me reading the tutorial, discuss with ChatGPT 5.5 Pro, and then feeding the history to Claude Opus 4.7 with a follow up discussion.
Why introduce at all
The intuitive AE→VAE story leaves a gap: why have a latent variable in the first place? The generative-model framing makes this clear.
VAE doesn’t model directly. It models data as the visible result of hidden causes:
Two reasons this matters:
- Modeling complex through a simpler latent space. — instead of fitting the data distribution directly, fit a decoder conditioned on a simple prior. Standard hierarchical modeling.
- Controlled generation. With a fixed prior , sampling new data is just: draw , decode. Plain autoencoders don’t have this — their latent space is unconstrained, so a random point in latent space may decode to nonsense.
The probabilistic framing immediately forces a question: given observed , what produced it? That’s , and it’s intractable because computing it via Bayes’ rule needs — the very integral we couldn’t do in the first place. This is the source of all the variational machinery below.
The probabilistic perspective (Doersch’s formula 5)
The central equation in Doersch’s tutorial:
The right-hand side is the ELBO — the VAE training objective. Decomposed:
- — reconstruction term. Sample from the encoder, decode, score how well it reconstructs .
- — regularizer. Keep the encoder’s output distribution close to the prior. This is what forces the latent space to be organized for generation.
Translation back to the architecture:
| Symbol | Meaning | Neural net role |
|---|---|---|
| datapoint | input | |
| latent | bottleneck code | |
| prior | usually | |
| decoder likelihood | decoder network | |
| true posterior | the intractable thing | |
| approximate posterior | encoder network output |
The left-hand side is the thing we wish we could optimize: minus the (unknown) gap between our approximation and the true posterior. The right-hand side is what we can optimize. Maximizing the right-hand side simultaneously:
- Pushes up (decoder + prior fit the data better),
- Tightens the bound by pulling toward — without ever computing the gap.
See ELBO for the full derivation, the “gap shrinks for free” argument (gradient w.r.t. encoder params is exactly minus the gradient of the gap), and why the KL is in the direction rather than . See Amortized variational inference for why one network handles all datapoints, and the cost — the amortization gap, which connects to posterior collapse.
Training: the Reparameterization trick
The encoder outputs and . To sample while keeping the operation differentiable:
Gradients flow through and into the encoder. Without this, you can’t backprop through the sampling step — see Reparameterization trick for why and what to do when is discrete (the case motivating VQ-VAE’s straight-through codebook lookup).
For diagonal Gaussian against an prior, the KL has a closed form:
so the training loss is a sum of reconstruction (typically MSE or BCE depending on the likelihood model) and this closed-form KL. No Monte Carlo estimate needed for the KL — only for the reconstruction term, which uses a single sample per datapoint in practice.
Positioning: VAE vs GAN vs Flow Matching
Three ways to set up a generative model. The clarifying axis: does the model need to invert ?
| Model | Latent randomness | Encoder / amortized posterior | Training objective |
|---|---|---|---|
| VAE | Yes, sampled at training and inference | Yes — | ELBO (lower bound on ) |
| GAN | Yes, initial noise only | No | Adversarial: |
| Flow Matching | Yes, initial noise only | No | Regression on velocity field |
VAE is alone in needing an encoder. The other two only map noise → data; they don’t ask “for this observed , what caused it?”
- GAN has a generator with no inverse. Training matches the distribution of generated samples to the data distribution via a discriminator. Avoids the ELBO entirely, but introduces adversarial-game instabilities and mode collapse — the GAN can produce sharp samples while ignoring chunks of the data distribution.
- Flow Matching reframes generation as an ODE: transports noise to data. Training regresses the velocity field against conditional target velocities. The marginal/conditional flow matching equivalence is what makes this tractable — see Flow Matching. No posterior, no encoder.
VAE’s tradeoff: you pay for the encoder with an amortization gap and a lower-bound gap, but you get something the others don’t — an inference network that maps observed data to latent codes. If you want representations directly, VAE-family models give them; GAN and flow matching require post-hoc inversion procedures (GAN inversion, flow inversion via solving the reverse ODE).
For positioning against diffusion specifically: DDPM’s training objective is itself a (reweighted) ELBO on a -step latent variable model with frozen forward and learned reverse . Structurally diffusion is closer to VAE than to flow matching — hierarchical latent variable model + variational inference. See Score matching for the equivalent score-regression view of the same training loss.
Next: VQ-VAE
VAE assumes continuous latents — sampling requires reparameterization, which assumes differentiability through the sampling step. For discrete latents (token-like codes), the reparameterization trick breaks. VQ-VAE replaces the Gaussian sampler with a nearest-neighbor lookup into a learned codebook + a straight-through gradient estimator for the non-differentiable step. The discrete codes also sidestep posterior collapse (the decoder can’t easily ignore a hard categorical input) and produce token sequences that downstream autoregressive or masked models can predict directly — the foundational pattern behind a lot of modern multimodal generation.