The following notes comes from my brief conversation with Claude Sonnet 4.6.
Core Idea
LDM (Latent Diffusion Models) with the UNet backbone swapped for a Vision Transformer. Patchify the VAE latent, run it through a ViT, predict noise. The architecture change is straightforward — the contribution is in the conditioning mechanism and the scaling analysis.
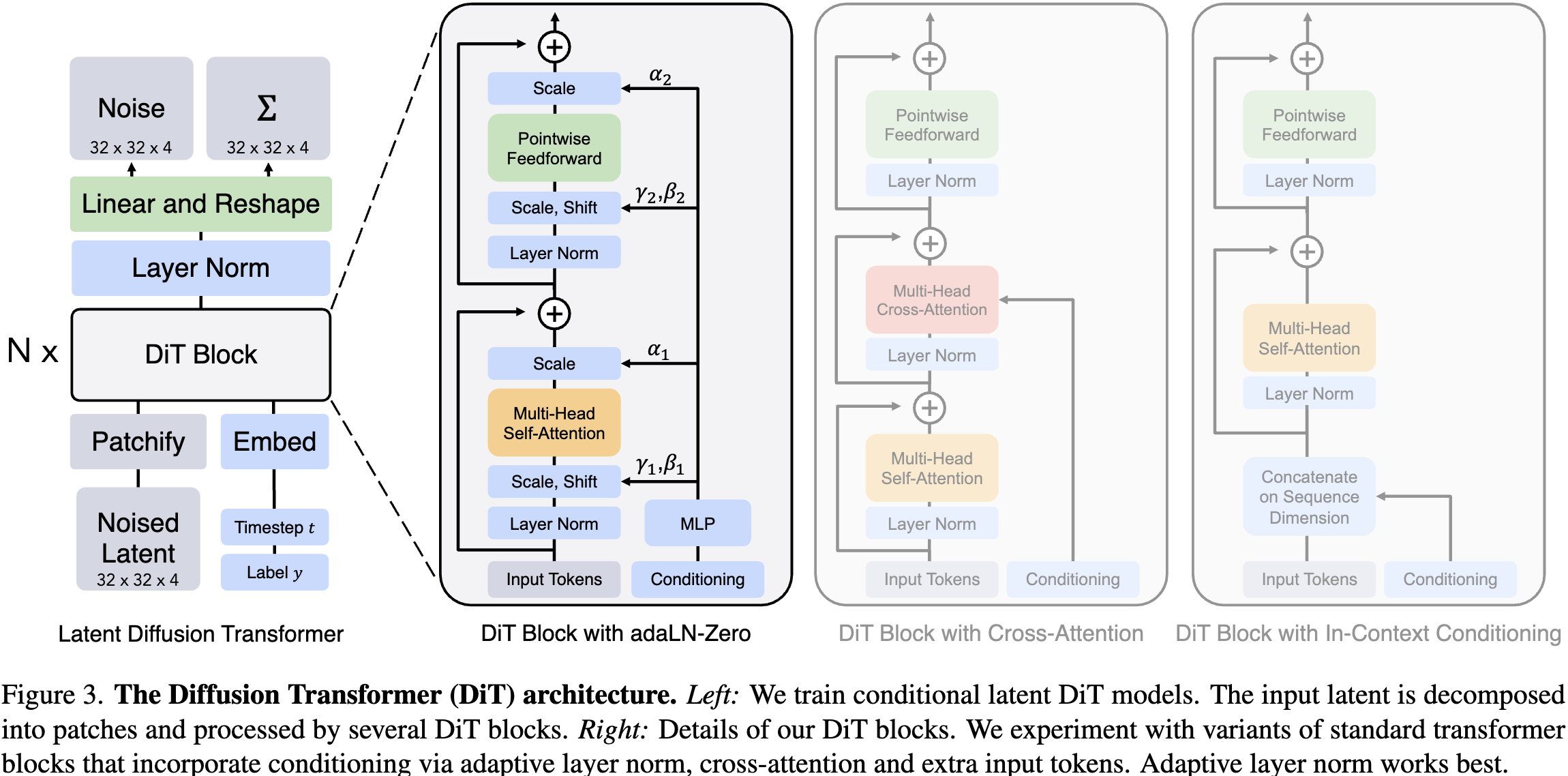
Conditioning: AdaLN-Zero
Standard LayerNorm
LayerNorm normalizes activations then applies static learned affine parameters:
and are fixed after training — the same for every sample and every timestep.
AdaLN
Adaptive LayerNorm makes and dynamic — predicted from the conditioning signal (timestep embedding + class embedding):
The network learns timestep-dependent scaling: “at , modulate activations this way; at , modulate differently.” Same idea as StyleGAN’s AdaIN — the style/conditioning vector controls the affine transform of every norm layer.
AdaLN-Zero
DiT adds a third MLP output that gates the residual connection:
The Zero part: the final linear projection in the MLP is zero-initialized. At init, , so every block is a pure identity map. Blocks “turn on” gradually during training as the MLP learns nonzero outputs.
Why this helps
Same intuition as ReZero / FixUp — zero-init residuals stabilize early training when conditioning signals are random. The model starts as a passthrough and learns to activate each block.
Why AdaLN beats the alternatives
DiT ablates four conditioning strategies:
| Strategy | Mechanism | Issue |
|---|---|---|
| In-context | Append timestep/class tokens to sequence | Wastes sequence capacity, no per-layer modulation |
| Cross-attention | Attend to conditioning tokens | Overkill for low-dim signal (just + class) |
| AdaLN | Dynamic per layer | ✓ |
| AdaLN-Zero | AdaLN + gating + zero-init | ✓✓ best FID |
AdaLN is cheap (one small MLP per layer), injects conditioning everywhere, and adds no sequence length overhead.
Actual Contribution
The architecture itself is not novel — anyone familiar with ViT and LDM could sketch it. The real contributions are:
1. Scaling law for diffusion. DiT follows a clean compute scaling law: Gflops (not parameter count) predict FID. Bigger model + more compute → monotonically better, predictably. The Chinchilla story applied to image diffusion.
2. Conditioning ablation. The comparison across in-context / cross-attention / adaLN / adaLN-Zero is the empirical work that earns the design choice.
3. Clean baseline. DiT-XL/2 was SoTA on class-conditional ImageNet 256×256 at the time, with a simple, reproducible setup. Essentially every serious diffusion model since — SD3, Flux, Sora (presumed) — is DiT-derived.
Genre
Same genre as ConvNeXT “obvious idea, done carefully at scale with the right ablation.” Not flashy science, but extremely influential because it provides a clean foundation the community can build on.