MLA — Multi-head Latent Attention
Disclaimer: I haven’t read the full paper.
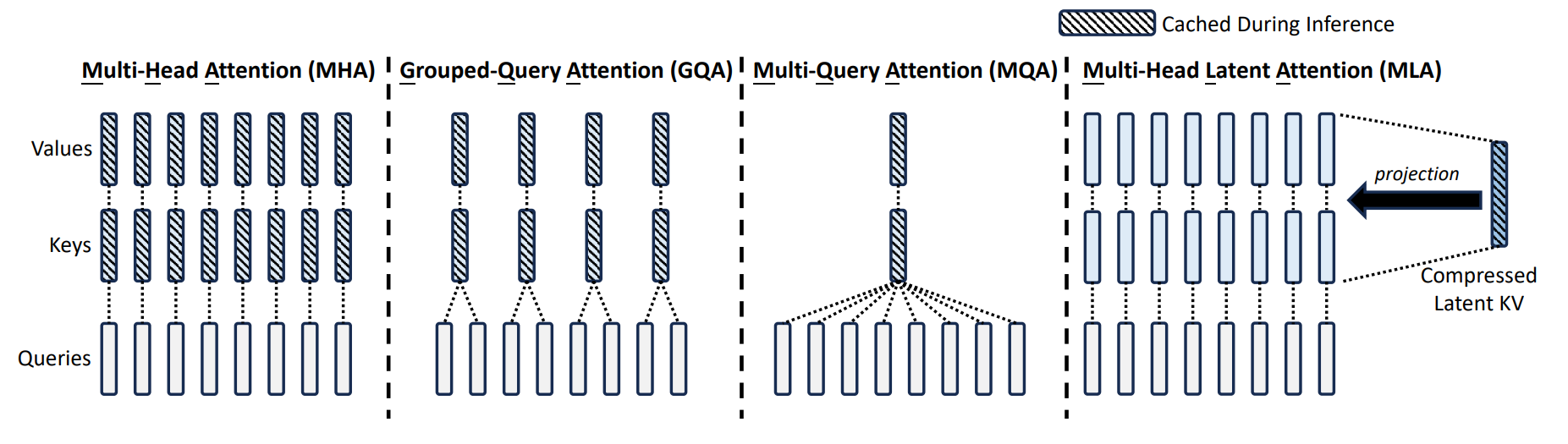
- Key idea: project down each key and value vector from dimensions to dimensions
- DeepSeek v2: reduce to
- Wrinkle: MLA is not compatible with RoPE, so need to add additional 64 dimensions for RoPE, so total dimensions
The rest of the note is based on my conversation with Claude Sonnet 4.6:
Core Idea: Bottleneck + Cache Shift
Standard MHA caches K and V at full dimension. MLA instead:
- Compress
x→ latentc_KV(small, cache this) - Decompress
c_KV→ K, V at inference time
Key insight
We shift where we cache. Instead of caching
K, V ∈ ℝ^d, we cachec_KV ∈ ℝ^{d_c}where . The decompression back to full rank happens on-the-fly and is not stored.

Dimensions
Let = d_model, = num heads, per-head dim.
| KV cache / token | Expressiveness | |
|---|---|---|
| Standard MHA | Full rank | |
| Shrink K/V heads | Reduced (small heads) | |
| MLA | Full rank (decompressed) |
Compression:
Decompression:
Is it equivalent to just shrinking K/V?
No. Shrinking K/V heads means each head genuinely has fewer dimensions — less expressive. MLA caches small but reconstructs full-rank K/V via learned up-projections. The bottleneck is in the cache, not in the attention computation.
The Absorption Trick (avoid materializing K/V)
Naive MLA does 2 BMMs to get K and V before attention — worse than standard MHA. The trick: absorb the up-projection weights into Q and output projection.
So redefine (merged into , done once), then attention runs directly against cached latents :
where is absorbed into the output projection .
Result
At inference, still 1 BMM against the cache — same as standard MHA, but the cache is wide instead of . Pure win on memory, no extra compute.
RoPE Caveat
RoPE is position-dependent, so it cannot be absorbed into a static weight matrix. MLA keeps a small separate (a few dims per head) that is materialized explicitly and cached separately. This bypasses the compression for positional info only.