Note from my discussion with Claude Opus 4.7, drafted by Sonnet 4.6
Paper: Deformable DETR (Zhu et al., 2020), §4.1.
Core insight
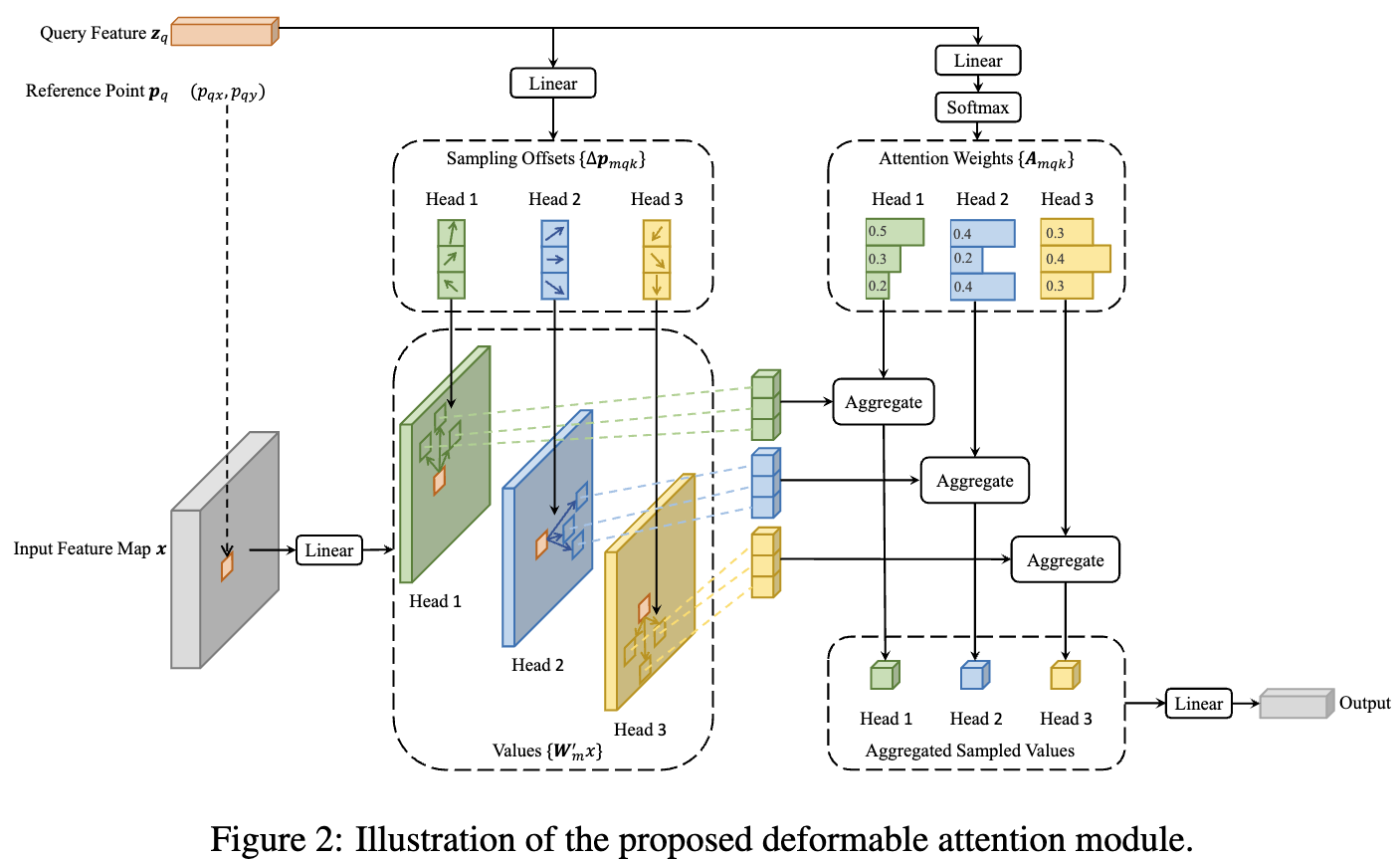
Instead of attending to every spatial location (cost ), each query learns K spatial offsets from a reference point and only attends to those K locations. Offsets and weights both come from the query alone — no query-key dot product.
The formula (single-scale)

| Symbol | Meaning |
|---|---|
| Query feature vector (-dim) | |
| Reference point (2D coordinate) | |
| Feature map () | |
| Head index ( heads, default 8) | |
| Sample index ( per head, default 4) | |
| Sampling offset (2D, unconstrained range) | |
| Attention weight; per head | |
| Value projection matrix (per head) | |
| Output projection matrix (per head) |
How offsets and weights are computed
Both and come from a single linear projection on with output channels:
- First channels → reshape to → the offsets . Unconstrained; can point anywhere in the image.
- Last channels → softmax over per head → the weights .

Both and branch from a single linear projection on . No feature map keys are consulted.
No keys involved
Unlike Multi-Head Attention, the weights are not computed from a query-key dot product. The query alone decides where to look and how much to weight each location. This is the defining departure from standard attention.
Sparse in count, not in reach
The constraint is on how many locations are sampled (K=4 per head), not how far the offsets can reach — is unconstrained in range. This is the key distinction from local-window attention (e.g. Swin Transformer) or CNNs, which restrict the radius. DeformAttn restricts the budget.
The sample locations are generally fractional coordinates, so the feature map is read via bilinear interpolation — same mechanism as Deformable Convolution.
Multi-scale extension
Changes from single-scale: feature levels, a normalized reference point rescaled per level by , and each head now sampling locations with one softmax across all of them.
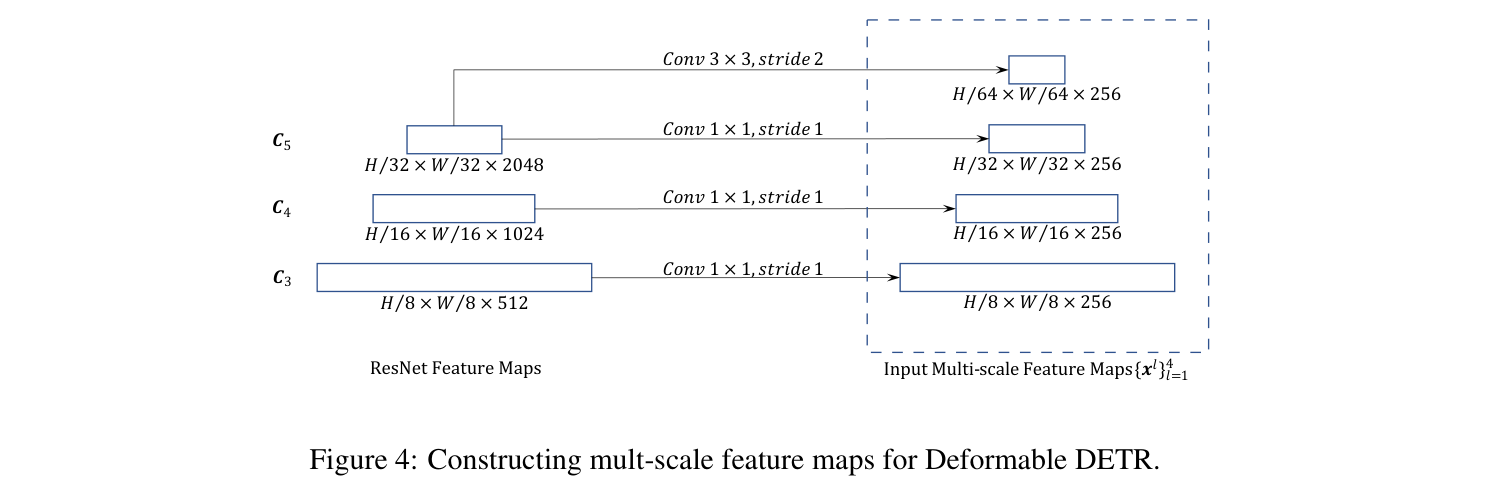
Building the pyramid (A.2)
No FPN. C3–C5 each go through a conv to , plus a fourth level () from a stride-2 conv on C5 (stride 64). The “multi-scale input” is just four channel-aligned projections of backbone stages:
Why the normalized reference point is the glue
A single query must address four feature maps of different resolutions with one coordinate — that’s the whole reason lives in and just unnormalizes it per level. Each head then predicts a separate set of offsets per level (in that level’s pixel units), and one softmax spans all weights:

The cross-level softmax is the FPN replacement
Because the softmax spans levels, scale selection is soft and learned per query — a small-object query can put nearly all its weight on the stride-8 level. Cross-scale routing lives in the attention weights, not in a fixed top-down pathway. Ablation: adding FPN on top gives nothing.
The token view (encoder)
The encoder input is literally the flattened pixels of all four levels concatenated into one sequence (~20k+ tokens — this is why linear complexity mattered). No patchification; the tokens are the conv feature vectors. Each pixel-token is its own query, with its own location as reference point, and gets two positional signals:
- a fixed sinusoidal 2D encoding of its normalized location, and
- a learned scale-level embedding (same vector for every token of level ).
Both are needed because the normalized coordinate is scale-blind: pixel at stride 8 and stride 32 would otherwise be positionally identical. And since DeformAttn has no query–key dot product, positional embeddings act only through the query side — they shape which offsets/weights a query predicts, never any key matching.
In the decoder, only cross-attention uses MSDeformAttn (queries → encoder tokens); self-attention among the object queries stays standard (cost is small).
Decoder object queries and the reference point
In DETR, the object queries carry no spatial information — specialization emerges implicitly through bipartite matching over hundreds of epochs. Deformable DETR keeps the same idea — learned, image-independent priors — but makes the spatial part explicit: the reference point is a deterministic function of the fixed query embedding, so after training each query has a fixed anchor point, identical for every image. The queries are effectively 300 learned anchor locations (later work — Anchor DETR, DAB-DETR — just parameterizes queries as anchors directly).
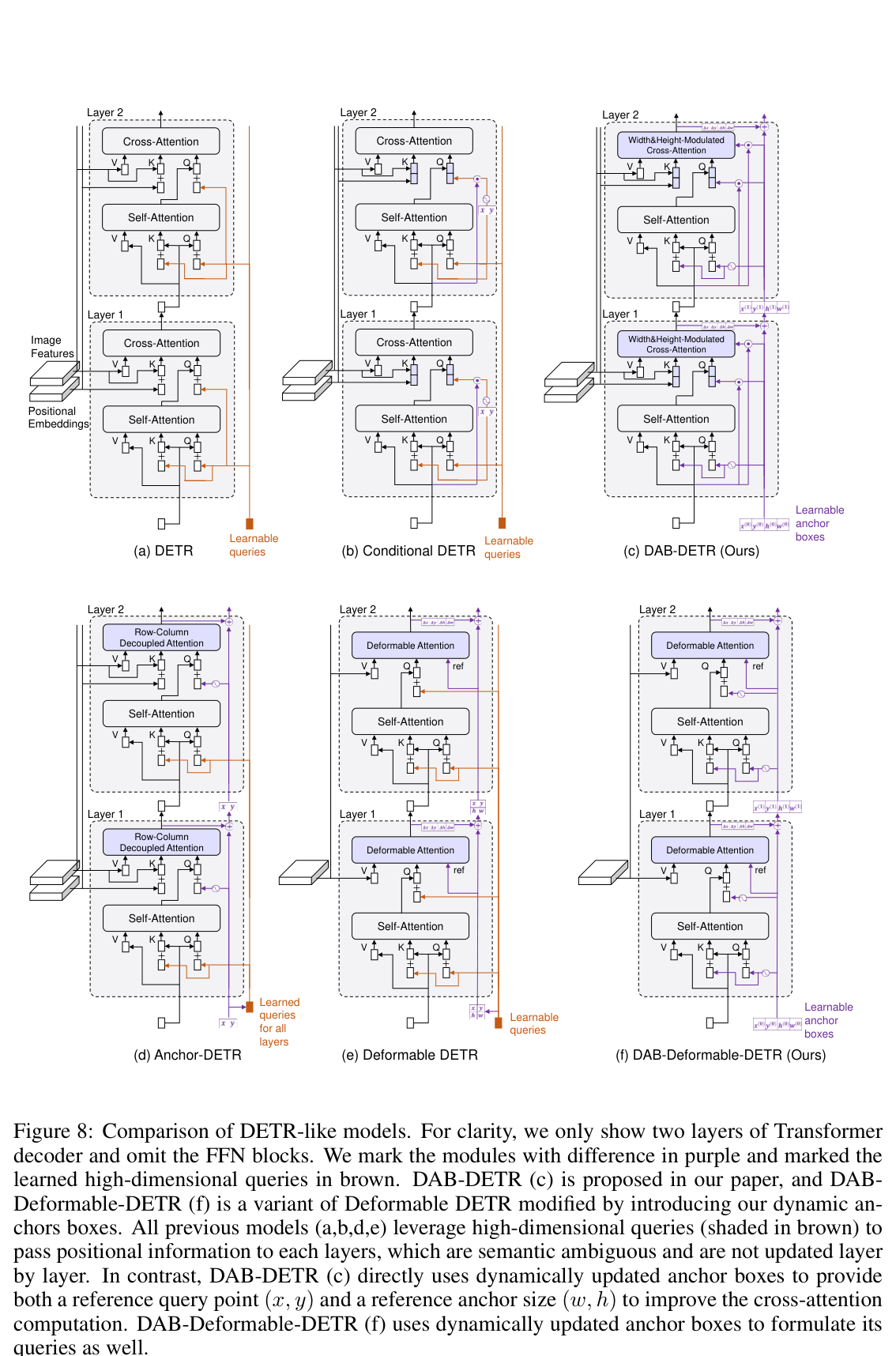
Where this sits in the DETR family — see DAB-DETR Fig. 8
DAB-DETR’s comparison figure lines up all six variants. Panel (e) is Deformable DETR — note it already carries an explicit reference point (
ref, in orange) into deformable cross-attention but still passes a high-dimensional learned query for content. Panel (f), DAB-Deformable-DETR, keeps the deformable sampling untouched and only swaps that query for a dynamic 4D anchor box (in purple), feeding both a reference point and a reference size — the two mechanisms are orthogonal, which is why they compose in ~10 lines of code.
Boxes are residuals on the reference point (A.3)
The detection head does not predict absolute coordinates. The box center is a residual in inverse-sigmoid space:
The reference point is literally the initial guess of the box center — the same point the query attends around is the point its box is anchored to, so “where I look” and “what I predict” are spatially locked together. The paper credits this correlation for faster convergence. (The linear layers predicting reference points and offsets train at 0.1× the base LR.)
Multiple objects at one location?
Nothing hard-assigns a query to a region: the box residual and sampling offsets are unconstrained, so a query can drift far from its anchor. De-duplication is DETR’s original mechanism — decoder self-attention (kept standard for exactly this) plus Hungarian matching pushing colliding queries onto different targets. No NMS anywhere.
Two-stage: an encoder-only detector proposes the queries
Motivation: one-stage anchors are content-blind — predicted from embeddings that have seen no image, they can only be well-spread priors. Two-stage lets the encoder propose them, RPN-style but end-to-end:
- Stage 1 = dense per-pixel detection on the encoder output. A detection head (3-layer FFN box regressor + binary foreground classifier) is applied to every encoder token — output is boxes, each anchored at its own pixel with a level-dependent base scale (the FPN-detector “level implies size” convention, smuggled back in). Trained with the same Hungarian loss, directly on the encoder — no decoder involved.
- Why not just make every pixel a decoder query? Decoder self-attention is quadratic in query count; tens of thousands of pixel-queries are infeasible. Hence: dense proposals → top-300 by score (no NMS — redundant proposals are deliberately let through for the decoder to sort out).
- Stage 2 initialization: the proposal box becomes the initial box for iterative refinement, and the query’s positional embedding is set to the positional encoding of the proposal coordinates — both anchor and query content derive from the encoder.
| Variant | Reference point source | Query source |
|---|---|---|
| DETR | none — fully implicit | learned embedding |
| Deformable DETR (1-stage) | — fixed per query | learned embedding |
| Deformable DETR (2-stage) | encoder proposal center | pos-enc of proposal coords |
The progression
DETR trusts queries to figure out space implicitly. One-stage gives them an explicit anchor. Two-stage doesn’t trust the queries at all — the “elegant slot” idea is quietly retired. Gains are additive (Table 1): 43.8 → 45.4 (+refinement) → 46.2 AP (+two-stage), concentrated in small objects.
Iterative bounding box refinement (§4.2)
Each of the decoder layers refines the box from the previous layer rather than predicting independently. The reference point for layer is the box center predicted by layer , and sampling offsets are modulated by that box’s predicted width/height — so the attention window shrinks as the box tightens. Detection heads are not shared across layers. Gradients are blocked through the inverse-sigmoid of the previous box (RAFT-style detach, for stability), and offset-prediction biases are initialized at scale so initial samples fall inside the previous layer’s box. See A.4 for the full formula.
Relation to deformable convolution
Setting , , recovers deformable convolution exactly. The lineage is Deformable Convolution → DeformAttn — not MHA with deformable sampling bolted on.
When does DeformAttn apply?
DeformAttn is a spatial-domain trick. It has three implicit assumptions that all depend on the feature map being a spatially coherent conv grid:
- Reference points are meaningful 2D coordinates in a continuous space.
- Offsets can point anywhere in that space with real-valued precision.
- Bilinear interpolation can retrieve features at fractional coordinates.
This is why it works when you combine attention with CNNs (conv feature maps are dense, spatially coherent, and continuously interpolable) and why it doesn’t directly translate to a ViT — a ViT token at position has no neighbor at ; there is nothing to interpolate between.
The paper’s 2020 publication date matters here: this is still the CNN+attention hybrid era. The implicit assumption that you have a real spatial feature map is never stated because it was universal.
Rule of thumb
Use DeformAttn when (a) your keys live in a spatially structured feature map, and (b) you know the relevant information is spatially local to the query but don’t know exactly where. If the feature map has no spatial meaning (flat ViT tokens, language sequences), the offset mechanism loses its grounding.