= Pi 0 + diverse manipulator data + web data + some Hi Robot idea + FAST. The result is a slightly more generalized system that can do similar tasks in new home. That’s it.
A person can draw on a lifetime of experience to synthesize appropriate solutions to each of these challenges. Not all of this experience is firsthand, and not all of it comes from rote practice – for example, we might use facts that we were told by others or read in a book, together with bits of insight from other tasks we have performed in different contexts, combined with direct experience in the target domain.
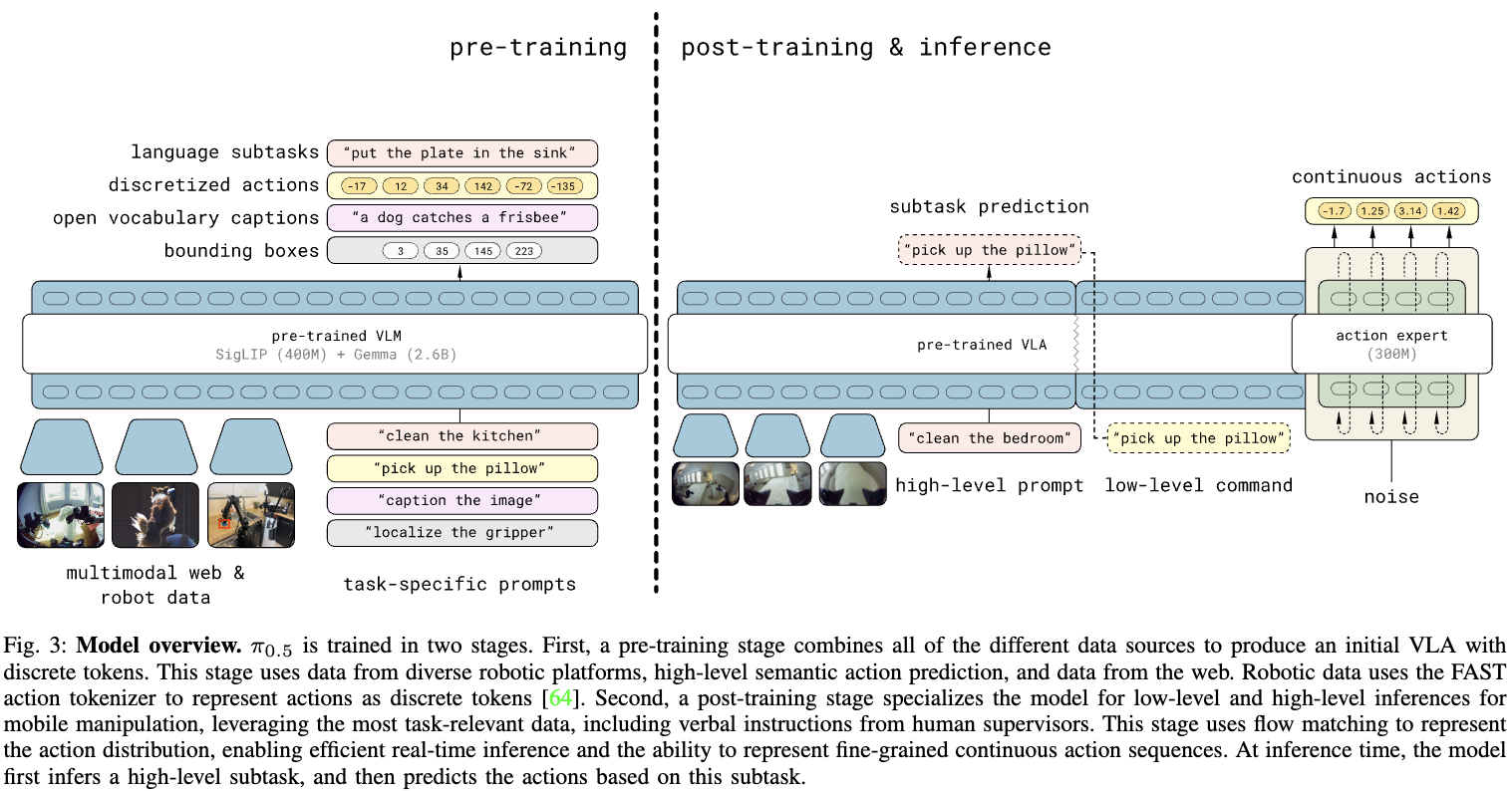
There are two phases in the training: pre-training and post-training. Pretraining is done on dataset A with autoregressive output using FAST. Post training is done on dataset B with flow matching output just like Pi 0. This makes training faster (since it’s FAST), and inference faster, since it’s flow matching.
The new loss:
where is the cross entropy loss between the text tokens and predicted logits (including the FAST encoded action tokens), is the output from the (smaller) action expert, and is a trade-off parameter.
In pre-training, that is , meaning it’s just training next token prediction, 280k steps. In second stage training, they set to , 80k steps, add in the action expert.

┌───────────────────────────────────────────────┐
│ PRE-TRAINING │
│ (mixed next-token training over modalities) │
└───────────────────────────────────────────────┘
│
│ data mixture ("pre-mix")
v
┌───────────────────────────────────────────────────────────────────┐
│ ROBOT ACTION DATA (imitation) │
│ - MM (home mobile manipulation) │
│ - ME (multi-environment home) │
│ - CE (cross-embodiment + OXE) │
│ │
│ + HL high-level subtask prediction supervision │
│ (subtask text labels + bboxes; predict subtask + actions) │
│ │
│ + WD multimodal web data │
│ (captioning + VQA + object localization; indoor/household) │
└───────────────────────────────────────────────────────────────────┘
│
│ Stage transition
v
┌──────────────────────────────────────────────┐
│ POST-TRAINING │
│ (specialize to home MM + action expert) │
└──────────────────────────────────────────────┘
│
│ data mixture ("post-mix")
v
┌────────────────────────────────────────────────────────────────────┐
│ ACTION DATA (Post) │
│ - MM FILTERED: keep successful episodes + length <= threshold │
│ - ME FILTERED: keep successful episodes + length <= threshold │
│ │
│ + WD continues (keep semantics/vision strong) │
│ │
│ + HL continues (subset slice; keep subtask reasoning) │
│ │
│ + VI added: verbal instruction demonstrations │
│ (step-by-step subtask commands collected via teleop) │
└────────────────────────────────────────────────────────────────────┘
Legend:
✓ used in stage
~ used but modified (filtered / subset)
+ newly added in that stage
✗ not used
───────────────────────────────────────────────────────────────────────────────
DATA SOURCE / TYPE PRE-TRAINING POST-TRAINING
───────────────────────────────────────────────────────────────────────────────
MM robot action data ✓ ~ filtered
ME robot action data ✓ ~ filtered
CE robot action data ✓ ✗ removed
OXE (inside CE) ✓ ✗ removed
HL: subtask supervision ✓ ~ subset slice
WD: multimodal web data ✓ ✓ continues
VI: verbal instruction demos ✗ + added
───────────────────────────────────────────────────────────────────────────────
───────────────────────────────────────────────────────────────────────────────
OBJECTIVE PRE-TRAINING POST-TRAINING
───────────────────────────────────────────────────────────────────────────────
Next-token prediction ✓ ✓ continues
Flow matching action expert ✗ + added
───────────────────────────────────────────────────────────────────────────────
Pay close attention to how the data is filtered and added in post training. Ablation shows all sources are important, with WD contribute to mostly generalization.
Also not that we do not use the synthetic prompt generation used in Hi Robot.
Interesting things about HL:
We also label relevant bounding boxes shown in the current observation and train π0.5 to predict them before predicting the subtask
Findings in evaluation
- The final model is as good as (pi_0_5, page 9) training the whole thing on test set.
- If train directly on the env but not with other co-training task, the model is worse, regardless of using train or test set. pi_0_5, page 9
- What about comparing with - FAST + Flow?
The differences then are: (1) π0.5 additionally uses HL and WD data; (2) π0.5 uses a hybrid training procedure, with discrete tokenized training in the pre-training phase, and training with a flow matching action expert only in the posttraining phase, while π0 always uses the action expert.
The result is the is better, but not by a large margin.