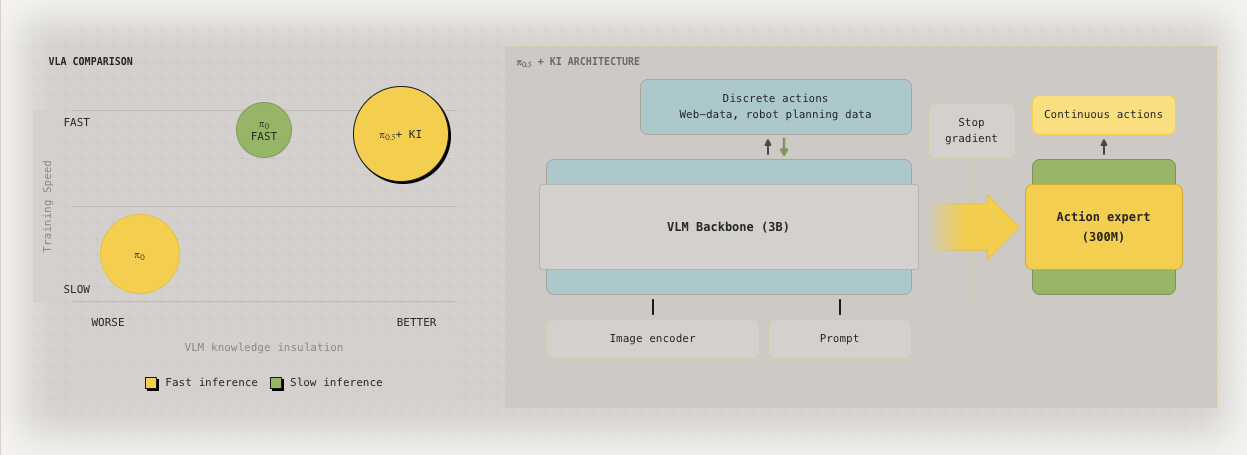
This paper basically eliminate that two stage training in Pi 0.5. Remember we need to add action expert / switch loss target in the training process? With this thing you don’t need to do that anymore.
Naively co-training both would lead to worse performance:
prior approaches for finetuning VLMs with continuous outputs can, perhaps unsurprisingly, lead to significantly worse training dynamics, as they rely on gradients from continuous adapters (e.g. diffusion heads) for the training signal. This can degrade both their ability to interpret language commands and the overall performance of the resulting VLA policy.
And freezing the VLM is also a good idea:
However, current VLMs are not pre-trained with robotics data. As a result, their representations, when frozen, are insufficient for training highly performant policies, as we show in our experiments
Solution
Therefore, we propose to stop the gradient flow from the action expert to the pre-trained weights in the model. This is a sensible restriction if and only if the backbone is additionally trained to predict actions directly as part of its language outputs.
The new loss:
where is a loss multiplier, trading off action prediction via flow-matching with the standard language modeling loss. is a language loss mask (indicating locations in the token stream at which the language loss should be applied) and is an action mask indicator specifying whether or not actions should be predicted for the given example.
Compare with Pi 0.5, we can see the main difference is that mask.
This loss construction allows us to flexibly mix-and-match co-training with data from different modalities. In particular, we combine VLM data (which has only images and text annotations) with action-only data (where the task is action prediction conditioned on images and text) as well as combined language and action prediction tasks (where we take action only data and additionally annotate it with a language description of what the robot should do next)
Pi 0.5 has this two stage training that in the second stage, it weights by setting and train both action expert and the VLA backbone. This value is set to focus more on the action expert and avoid it corrupting the VLA too much. Here we use a better method, so we can still let VLA adapt to robot data, without corrupting it. (If we freeze it after pretraining, it learns less)
For the single head attention case, we can write the attention operation as where are the inputs to the attention layer, are the attention query and key projections, respectively, is the attention mask as described above, and softmax is the row-wise softmax. The result are attention probabilities over token features which decompose into probabilities where features from the VLM backbone attend to features from the backbone , probabilities for action expert features attending to backbone features and probabilities for action expert features attending other action expert features . Given this we can restrict information flow as desired by implementing the softmax computation as
where sg denotes the stop-gradient operator that restricts gradient-flow through this part of the computation. corresponds to all processed with the backbone weights, to the tokens processed with the action expert weights. The value embeddings are then computed by
and the final attention is . One additional advantage of this design is that we can simply set in (4), since now the diffusion loss term applies to an independent set of weights.
In other words, as we cut the gradient on backbone features used in key calculation for action expert attending, action expert’s loss term would not affect backbone (kinda). The action loss can still update backbone parameters, but stop-gradient prevents updates flowing through the action→backbone cross-attention K/V pathway.