This is for discrete action output for autoregressive models (so not applying to flow models like Pi 0).
Existing solution
- Semantic action representations like language sub-tasks, or keypoints. This requires lower-level controllers to actually do the action
- Per dimension, per-timestamp binning. This does not adapt well with high-frequency tasks.
One key takeaway of our work is that any sufficiently effective compression approach, when applied to the action targets, is suited to improve the training speed of VLA models. In practice, there are a few considerations that may still lead us to favor some compression algorithms over others, e.g., the complexity of training the tokenizer, and how efficient is it at tokenizing and detokenizing actions.
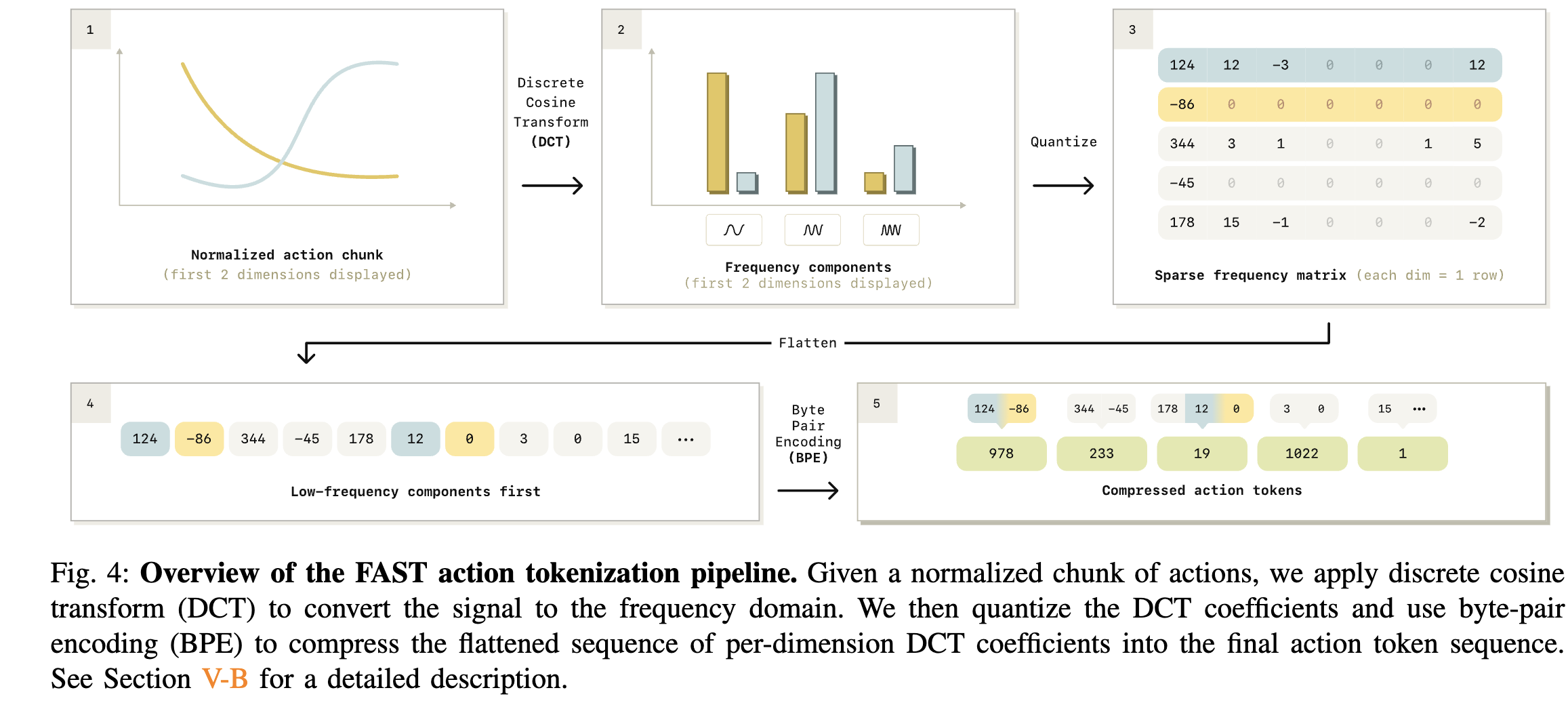
I have to say it’s pretty obvious binning is not a good idea and we would want to look at the frequency domain.
They then train a FAST+, a tokenizer based on a lot of data for the BPE, and it is able to achieve the same performance of from-scratch training.
Overall, we find that the autoregressive π0-FAST model matches the performance of the diffusion π0 model, including on the most challenging laundry folding task, while requiring signifi- cantly less compute for training.
One current limitation of the autoregressive VLA is its inference speed: while π0 with diffusion typically predicts one second action chunks within 100ms on an NVIDIA 4090 GPU, the π0 model with FAST tokenization needs approximately 750ms of inference time per chunk, since it must perform more autoregressive decoding steps (typically 30-60 action tokens need to be decoded, vs. 10 diffusion steps for diffusion π0) and use the full 2B parameter language model backbone for autoregressive decoding (vs. a 300M parameter “action expert” for diffusion π0).