I wrote about 20% of the note with template of {{Claude: you fill this}}. Generated with a conversation with Claude Sonnet 4.6 followed by Opus 4.7.
Basically this paper claims “I’m the real WAM (World Action Model)“! I think their claim of “why we made certain design choices” is bogus. Still the result is very strong and seems promising.
TLDR
On a high level: use an image-to-video foundation model as base. Slap some extra encoder/decoder on top of it, let it output actions too. Compared with VLA, just replace the VLM with the video generation model. And… that seems to be 80% of the whole story.
What the team claims as novel beyond “use video gen”:
- The same model for video gen and action. “Naively combining separate video and action heads can lead to misalignment.”
- Autoregressive video decoding with teacher forcing (replace predicted frames with ground-truth observations in the KV cache after each chunk executes).
- A bunch of inference optimizations.
One model vs separate heads — is that actually non-naive?
The “naive” version they’re contrasting against is having a separate video prediction model and a separate inverse dynamics model — see Equation 1 in the paper:
So the “naive” baseline is two separate networks: one predicts future video, the other extracts actions from the predicted video. DreamZero collapses both into one transformer with shared backbone weights and joint flow matching, claiming this gives better video-action alignment because gradients from action prediction flow into the video representations and vice versa.
Is this actually non-naive though?
Honestly, no — running both flow matching losses on the same transformer is the most obvious thing to try. Calling separate networks “naive” feels like a strawman. The genuinely interesting design choice is not the joint training — it’s the chunk-wise autoregressive video structure with observation injection (next section). Saying “joint training of video and action via flow matching” is interesting research framing but isn’t really the architectural innovation.
Training objective
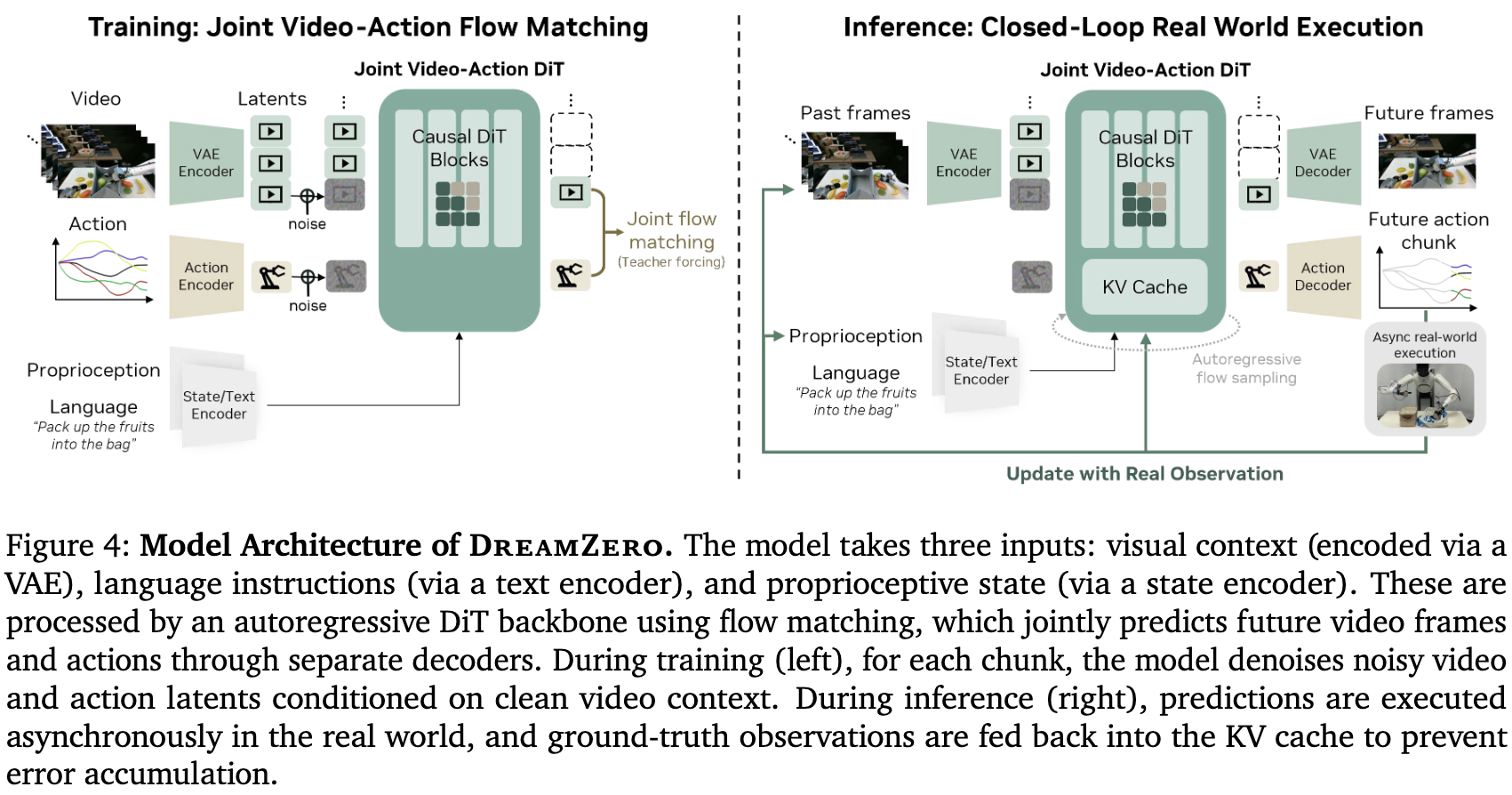
As seen in the figure, the two heads are both flow matching. The total loss is two flow matching losses added together — regression on the velocity:
where is the joint velocity for both modalities concatenated, and is the clean context from previous chunks (teacher forcing).
A subtle but important point: video is autoregressive across chunks, but actions are not. Each chunk’s actions are predicted fresh from the current video context via flow matching — there’s no AR dependency from chunk N’s actions to chunk N+1’s actions. The paper says this is “to avoid error propagation coming from closed-loop action prediction” — see Why is the action model not autoregressive across time.
Disambiguating “autoregressive”
This was confusing because the Pi 0 / Pi 0.5 / Knowledge Insulating VLA papers use “autoregressive” to mean something completely different from DreamZero. Three nested levels in any VLA:
- Episode level: full task, hundreds of chunks.
- Chunk level: 50 actions × ~1.6 seconds, the unit one forward pass produces.
- Token level: individual action dimensions or FAST tokens within a chunk.
Two orthogonal AR axes
- DreamZero’s AR: across chunks (level 1→2). Each chunk attends causally to past chunks via KV cache. Contrasts with bidirectional fixed-window models.
- Pi’s AR: across tokens within a chunk (level 2→3). Each FAST token decoded sequentially through the 3B backbone. Contrasts with parallel flow matching of the whole chunk.
The two AR axes don’t even apply to the same systems. The across-chunk axis only exists when the model maintains state between inference calls:
- Pi 0 / Pi 0.5 / Knowledge Insulating VLA are stateless across chunks. Each inference call is independent — predict one chunk, execute ~half of it, then call the model fresh with a new observation. No KV cache, no temporal dependency. The across-chunk axis simply doesn’t exist for these models. Their AR-vs-flow-matching debate happens entirely at the within-chunk level.
- DreamZero is stateful across chunks via the KV cache of past video frames (up to 6.6s of visual history per Appendix C). That statefulness is what creates the across-chunk axis, and it’s also what makes observation injection necessary (to prevent compounding errors in the maintained state). Within each chunk, DreamZero uses parallel flow matching for both video and actions.
So the matrix:
- DreamZero: AR across chunks (causal video context with KV cache), parallel within chunks (joint flow matching).
- Pi 0: no across-chunk axis, parallel within chunks (flow matching).
- Knowledge Insulating VLA: no across-chunk axis, both representations within chunks (FAST tokens sequential for training-time representation learning + flow matching parallel for inference).
The “AR is fast” claim in DreamZero and the “AR is slow” claim in Pi 0.5/Knowledge Insulating VLA are not contradictory because they’re about different axes that don’t even coexist in the same systems:
- DreamZero: AR across time (chunks) is faster than bidirectional across time for long contexts, because KV cache works for causal but not for sliding bidirectional windows.
- Pi: AR across tokens within a chunk is slower than parallel flow matching across tokens at inference (50 sequential big-backbone passes vs ~10 small-expert passes), but faster at training convergence because discrete tokens give a stronger learning signal than pure flow matching (Figure 6b of Knowledge Insulating VLA).
Why is the action model not autoregressive across time?
The paper says: “We introduce autoregressive modeling only for the video modality to avoid error propagation coming from closed-loop action prediction.”
This justification is weak
LLMs are autoregressive across tokens and live with error compounding fine. The real reason action AR-across-chunks isn’t useful is probably more like:
- Once a chunk executes on the robot, you replace predicted video with the actual observation in the KV cache. So the next chunk conditions on real visual reality, not predicted video. With this mechanism, predicted actions from past chunks don’t need to feed into future chunks at all — the robot’s actual state (encoded in the new observation) already captures the result of past actions.
- In other words: AR-across-chunks for actions would be redundant with the observation injection. The visual feedback loop already breaks error propagation.
So the architecture is: video AR across chunks (with observation replacement), actions parallel-per-chunk via flow matching, conditioned on the autoregressively unrolled video context.
Why AR across chunks at all, if they don’t even use memory?
The paper sells AR-across-chunks partly with future-memory framing, but footnote 2 admits they don’t evaluate memory-dependent tasks. So if memory isn’t the reason, what is? My best guess is that the video diffusion backbone needs temporal context to function, and AR is the cheapest way to provide unbounded temporal context.
Wan2.1-I2V was pretrained on video sequences, not single frames. Running it statelessly on one frame at a time would put it way out of distribution — the model’s priors are over temporal patches, not static images. Once you commit to “the backbone needs a temporal window,” the architectural question becomes “bidirectional fixed window vs causal growing window with KV cache.” The latter wins because:
- You can cheaply extend visual context (just append to the cache).
- Variable-length training works naturally — episodes don’t have to be padded/truncated to a fixed window. This is mentioned in the paper as analogous to how LLMs train on variable-length text.
- Memory tasks are a natural extension if you want them later.
There’s also a softer benefit even without “memory” in the long-term sense: a single observation doesn’t tell you which way objects are moving or whether the gripper is opening/closing. The last few frames disambiguate motion and intent. Pi handles this with proprioceptive state and long action chunks; DreamZero gets it for free from video context.
My read
The “memory” framing in the paper’s discussion section is mostly forward-looking. The actual immediate reason for AR-across-chunks is that they’re using a video diffusion backbone, and video diffusion backbones expect temporal windows. Given that constraint, AR-with-KV-cache is the efficient way to satisfy it. The architecture would also work statelessly with a fixed window of past frames + bidirectional attention, but that loses the “extend context cheaply” property and forces awkward fixed-shape training.
KV Cache: what’s actually being cached?
General principle
KV cache works whenever some tokens’ K and V stay fixed across the operations you’re doing. You cache those, recompute only what changed.
Three concrete examples:
- Standard LLM: past tokens are fixed once generated. Cache their K, V; only compute Q, K, V for the new token.
- Pi 0 flow matching: prefix
[images, lang, state]is fixed across all 10 denoising steps. Cache prefix K, V once; only recompute the noisy action tokens whose values change every step. See appendix Table I — the prefix forward pass costs 32ms once, then 10× action forward passes total just 27ms. - DreamZero across chunks: past clean chunks (after observation replacement) are fixed while denoising the current chunk. Cache them; only recompute the noisy current-chunk tokens.
Pi 0’s action expert uses full bidirectional attention within the action block and still benefits from caching because the prefix it attends to is fixed. What kills KV cache is when adding new context invalidates past tokens’ K and V — i.e., when sliding a bidirectional window forward, past frames’ attention partners change so their K, V need recomputing.
That’s the real architectural reason DreamZero is causal across chunks: they want to grow context as the robot acts, and bidirectional growth would force recomputation of all past frames every step.

Why this likely outperforms VLAs (zero-shot generalization)
Key empirical results from the paper:
- 2× task progress over Pi 0.5 and GR00T N1.6 on seen tasks in unseen environments.
- 39.5% vs 16.3% on unseen tasks (verbs/motions absent from training).
- 42% relative improvement on unseen tasks from just 10–20 minutes of cross-embodiment video data.
The paper’s hypothesis (which I find compelling): VLAs need lots of action data to learn the observation→action mapping directly, because they’re learning from sparse state-action pairs. WAMs offload most of that learning to video prediction, which is pretrained at internet scale on physics-rich data. Action prediction collapses to a much easier inverse dynamics problem: “given this predicted visual future, what motor commands produce it?” This is sample-efficient because the IDM can be small and the heavy lifting (physics, semantics, scene understanding) is done by the video backbone.
Anecdotally consistent with the failure mode they report: most DreamZero failures are video prediction errors, not action extraction errors. The robot faithfully executes whatever the video says, so improvements to video generation directly translate to better policies.
Connection to Pi knowledge insulation
Knowledge Insulating VLA argues that flow matching gradients from a randomly-initialized action expert damage the pretrained VLM backbone, so they stop the gradient. DreamZero sidesteps this entirely — the video flow matching loss is the primary training signal, aligned with what the pretrained backbone was already trained for. There’s no “knowledge to insulate” because the model is essentially still doing video generation, just with an action side-channel.
Optimizations
DreamZero’s baseline 14B model takes ~5.7 seconds per chunk. They get to ~150ms (38× speedup) for real-time control at 7Hz. Three layers:
System-level:
- CFG parallelism — split conditional and unconditional forward passes across two GPUs (~1.9× on H100).
- DiT caching — when cosine similarity between successive velocity predictions exceeds a threshold, reuse cached velocities. Effective DiT steps drop from 16 to 4. Conceptually similar to TeaCache/TaylorSeer.
- Asynchronous execution — decouple inference from action execution. Motion controller executes the most recent action chunk while inference runs concurrently on the latest observation.
Implementation-level:
torch.compile+ CUDA Graphs (huge CPU overhead reduction).- NVFP4 quantization with FP8 for sensitive ops (QKV, Softmax) and FP16 for non-linear ops on Blackwell.
- cuDNN attention backend, GPU-side scheduler ops.
Model-level — DreamZero-Flash:
- Decouple video and action denoising schedules during training. Video timestep biased toward high noise via where , so . Action timestep stays uniform.
- Trains the model to predict clean actions from noisy visual context — directly matching the few-step inference regime where video is still noisy when actions need to be final.
- Cuts denoising steps from 4 to 1 with minimal performance loss (74% vs 83% task progress on table bussing).
Action chunk smoothing: upsample 2×, Savitzky-Golay filter (window 21, polynomial 3), downsample.
Open questions / things the paper handwaves
- Why chunk-at-a-time and not MPC-style N-chunk lookahead? They never address why predicting multiple chunks ahead and replanning isn’t done. The closed-loop observation injection only requires one chunk between observations, not strictly one at a time.
- Chunk size ablation absent. They use latent frames per chunk, actions, 1.6 seconds. They claim beats but don’t show numbers or compare longer chunks.
- Scaling laws. They note 14B beats 5B but don’t characterize the curve. Their own discussion calls this out as future work.