Note: this is not an easy-to-understand paper. I get the basic idea of it by first going over a YouTube video.
Overview
The most novel idea in this paper is that: it use a trained neural network to represent a scene. If you want to describe a new scene, you need a set of new weights for that scene. To train such a network (function), you just need some images.
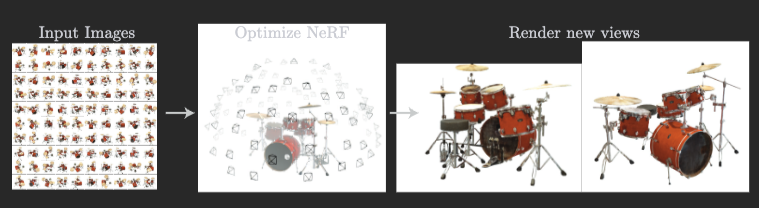
Another idea is to represent 3d surfaces by Neural Radiance Fields (that’s in the title), in contrast to Signed Distance Function used in DeepSDF (recall that’s converting surface samples to a “surface function”), or grid based methods.
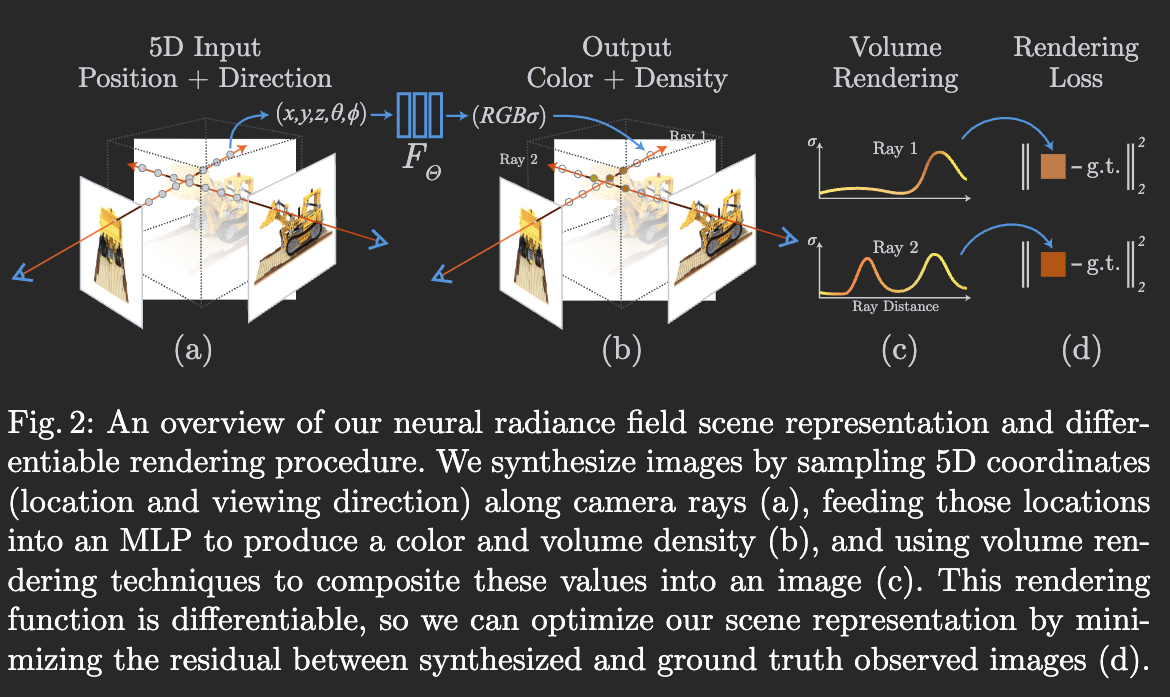 The core part of this image is “differentiable”. Training input and inference inputs are the same, so the process is basically “try rendering a bunch of images based on network weight, and see if the image look like the real images”.
The core part of this image is “differentiable”. Training input and inference inputs are the same, so the process is basically “try rendering a bunch of images based on network weight, and see if the image look like the real images”.
What’s volume density? Obviously it’s classic thing in volume rendering.
The volume density can be interpreted as the differential probability of a ray terminating at an infinitesimal particle at location . The expected color of camera ray with near and far bounds and is:
here is basically the probability that the ray travels from to without hitting any other particle (it’s not occluded). So here the formula means “if the ray ends here you would see this, if it ends there you’ll see that, add them together”.
Details
- In practice, the volume rendering is done by something called quadrature, with stratified sampling.
- Density only takes in location as input, while color also takes viewing angles into account.
In training (optimizing):
Positional encoding
Directly using cause the model to perform poorly. This can be caused by the networks are biased towards learning lower frequency functions. So we need to map them to higher dimension space. A position encoding similar to the OG Transformer is used. It’s also multiplied with a learned encoding.
Hierarchical volume rendering
Spend the network power on where it’s needed. Train two networks: one “coarse” and one “fine”. First sample a set of locations, then get a PDF of where it think is dense, and then use inverse transform sampling to sample fine points . The loss is the simple summation of both networks.
Here is the rendered RGB color.
Training takes about 1-2 days on a V100.