Notes written by Claude (Opus 4.8) from a reading discussion.
VGGT’s central bet is that the entire classical visual-geometry pipeline can be replaced by a single feed-forward transformer — one network that takes a set of images and directly emits cameras, depth, 3D points, and correspondences, with no iterative optimization at inference. The result that makes the bet pay off: it beats the prior learning-based methods that do rely on post-hoc optimization, while running ~50× faster.
The problem: 3D from a pile of images
Given several photos of the same scene, recover the 3D structure and where each camera was. Classically this is Structure-from-Motion + Multi-View Stereo: detect keypoints, match them across images, triangulate 3D points, then run bundle adjustment (BA) — a big nonlinear least-squares optimization that jointly nudges all camera poses and 3D points to minimize reprojection error. It works well but is slow, fiddly, and a pipeline of separately-engineered stages.
The recent learning-based line (DUSt3R, MASt3R — the methods VGGT positions itself against) made this much more end-to-end, but kept one foot in the classical world. They operate on image pairs: a network ingests two views and predicts a point map (a 3D point per pixel) for each. To handle images you run the network on many pairs, each producing 3D points in its own local coordinate frame, then stitch everything into one global frame with an iterative global alignment step — essentially a lightweight BA. The pairwise restriction is architectural (their cross-attention only relates two images at a time), and the alignment step is the optimization VGGT wants to eliminate.
What VGGT changes
Ingest all images at once in a single forward pass and predict everything jointly, so multi-view consistency is baked into the network’s output rather than recovered afterward by optimization. No pairwise decomposition, no global alignment. (You can still bolt BA on top for a further bump, but the un-optimized output is already state of the art.)
What makes this notable is how little it does. A lot of prior research effort went into making bundle adjustment differentiable — BA is a nested nonlinear optimization, and backpropagating through it so it can live inside an end-to-end network is genuinely hard. VGGT just declines to do that. It drops BA from the forward path entirely and lets large-scale supervision teach the network the consistency BA used to enforce. The move is almost anticlimactic — “take all the images and run a transformer over them” is the first thing you’d naively try — and the contribution is largely the demonstration that, with enough data and the right multi-task supervision, the naive thing actually works and beats the carefully-engineered pipelines.
How it works
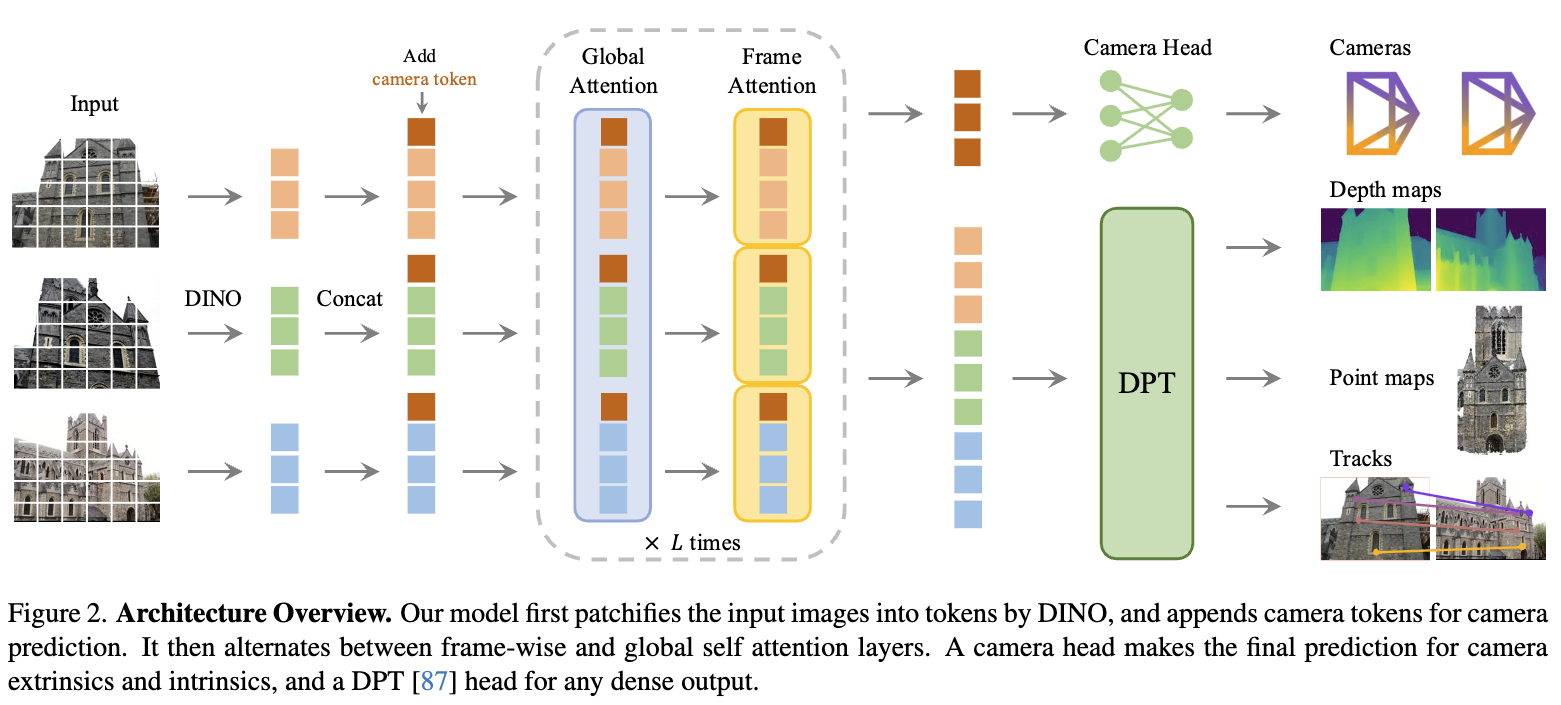
Tokenize and attend. Each image is patchified into tokens by a DINO backbone, with a learnable camera token and a few register tokens appended per frame. The stack of all frames’ tokens then goes through the transformer.
Alternating attention is the key architectural choice that makes “all frames at once” tractable. Each layer alternates two kinds of self-attention:
- Frame-wise: tokens attend only within their own image ( for tokens/frame) — cheap, and normalizes per-image.
- Global: all tokens attend jointly — this is where cross-frame reasoning happens.
Interleaving the two gives global multi-view reasoning without paying full global attention at every layer, and uses no cross-attention at all. Because every frame can see every other frame in one pass, the network can learn to triangulate implicitly instead of assembling pairwise guesses.
Prediction heads read off the shared tokens (detailed below): a small head maps the camera token to extrinsics + intrinsics, and a DPT head produces the dense outputs (depth, point maps, per-pixel tracking features).
Over-complete prediction: the most interesting design choice
The non-obvious idea, and where I’d put most of the weight: the network predicts cameras + depth maps + point maps even though any two of them mathematically determine the third. Conventional intuition says supervise only independent quantities; VGGT supervises all of them and all three improve (their ablation, Table 6).
The reason isn’t “more tasks = better.” Cameras/depth/points form a closed geometric system — each constrains the others through known equations. Forcing the network to emit all three drives the shared representation toward internal geometric consistency, which is the very thing BA enforces by optimization. In effect, the consistency that BA computes at inference time is instead learned at training time. (A nice consequence: at inference, combining the independently-predicted depth + camera yields better 3D points than reading the point-map head directly.)
Components and background
The model leans on several ideas worth knowing if they’re unfamiliar — the DINO register trick, the DPT dense head, and the CoTracker-style tracking head. Here’s what each is and why it’s here.
Register tokens
From “ViTs Need Registers” (Darcet et al. 2024). DINOv2 (and other self-supervised ViTs) hijack a few low-information patch tokens to stash global info, corrupting the spatial feature map. Fix: append a handful of meaning-free learnable tokens as scratch space, then discard them. VGGT appends 4 per frame alongside the camera token. The pathology is worst in self-supervised ViTs; milder in supervised CLIP/SigLIP. DINOv2 ships -reg variants; DINOv3 bakes registers in and fixes a second outlier type (feature-dimension outliers, via Gram anchoring) that registers don’t touch.
DPT head
FPN-style logic grafted onto a ViT. ViT layers all sit at the same resolution with no hierarchy, so DPT fakes the pyramid by tapping different-depth layers (VGGT taps layers 4/11/17/23 of 24), reshaping each into a 2D grid, and fusing UNet-style. The conceptual move: transformer layer depth as a proxy for CNN spatial scale. Pragmatic, not deep.
CoTracker2 (the tracking head)
Tracking-by-correlation. For a query point in frame , bilinearly sample its -dim feature from the dense tracking features , then dot it against every spatial location in every other to get a correlation map (“how much does each location look like my query?”). The peak is roughly the correspondence; attention across frames refines it and handles occlusion. So VGGT’s backbone never says “this point goes there” — it produces features, and this head does the matching. It’s SIFT’s job (detect → describe → match) done densely, end-to-end, with 3D-aware features — which is why it beats LoFTR/RoMa on ScanNet without being trained for matching.
Two distinct tracking modes — don't conflate them
Mode 1 (rigid, the built-in head): unordered images of one static scene; finds 3D-consistent correspondences across viewpoints. Not temporal.
Mode 2 (dynamic video, §4.6 fine-tuning): plug VGGT’s backbone into CoTracker2 as the feature extractor and fine-tune on Kubric. Here frames really are video with moving objects; VGGT is used purely as a strong feature backbone and has no idea the frames form a video — CoTracker’s temporal attention handles the dynamics. You need Mode 2 because the built-in head assumes a rigid world: a walking person’s leg is at a different 3D point each frame, breaking the “same 3D point across views” assumption outright.
How the tracking labels are made (no human annotation)
Pure reprojection geometry on datasets that already have depth + poses: unproject pixel in frame to a 3D point via and , reproject into frame via to get , and validate by checking the reprojected depth matches (mismatch ⇒ occluded). The track loss is then just L1 between predicted and reprojected-GT 2D locations.
Training objective
The full loss is a plain sum over the four predicted quantities, jointly end-to-end:
- — Huber loss between predicted and ground-truth camera parameters (quaternion, translation, field-of-view).
- and — the same uncertainty-weighted form (below), applied to depth maps and to point maps respectively; each has its own predicted uncertainty map (, ).
- — L1 between predicted and reprojected-ground-truth 2D correspondences (see tracking labels above), down-weighted by since it’s auxiliary.
The camera/depth/point-map terms are weighted equally — this equal-weight joint supervision over the closed geometric system is exactly the over-complete prediction mechanism in action. The depth term is worth unpacking because it carries two ideas (aleatoric uncertainty + a gradient term) that recur in the point-map loss too:
Aleatoric uncertainty term (Kendall & Gal 2017; see also Uncertainty based learnable weighting). The DPT head emits two maps per frame: depth and a positive uncertainty (softplus). The first term scales down the penalty where the model claims high uncertainty (forgiving genuinely ambiguous regions like textureless walls); the term stops it from declaring infinite uncertainty everywhere. The two balance, and falls out as a free confidence map. Aleatoric = irreducible data noise, vs. epistemic = model ignorance (the latter handled by deep ensembles, MC dropout, BNNs, or evidential/Dirichlet methods). Aleatoric dominates in regression because it’s one extra head with no extra forward passes.
Gradient term. is just a Sobel/finite-difference of the depth map (a stack of x/y gradients) — a fixed target, not learned. Absolute depth loss is shift-invariant-blind: a globally smeared depth map can score the same as a crisp one. Penalizing forces depth discontinuities to land in the right place. The deeper reason it matters: depth gradients encode surface normals. For a pinhole camera each pixel maps to ; tangents , depend on , and the normal is . So penalizing gradient error is implicitly penalizing normal error — which is why it sharpens object boundaries where normals flip. (Same operator as Harris/Canny, but those run on RGB to find edges; here it runs on predicted depth to enforce surface geometry.)
On : “channel-broadcast element-wise product.” Only matters for the point-map loss, where is (XYZ) and the scalar uncertainty gets broadcast across the 3 channels.
One open question
The paper convincingly demonstrates that joint attention + over-complete supervision removes the need for BA, but it doesn’t really explain what the network learns: genuine implicit triangulation, or very good geometric statistics memorized from training data? A telling clue is that swapping the DINOv2 backbone for a stronger one (DINOv3) yields further gains — i.e. feature quality is still a bottleneck, which suggests the results aren’t near a ceiling and that the “minimal inductive bias” framing rests more on representation quality than the architecture alone. Worth keeping in mind, not a strike against the paper.
The implementation is a snapshot — see the Ω follow-up
Several specifics here are already superseded by VGGT-Ω (2026)
- DPT’s expensive high-res conv stages are replaceable by MLP + pixel-shuffle (−70% GPU memory, no quantitative drop); only the shallow low-res conv layers carry their weight.
- The CoTracker head is gone at inference — matching is folded into the shared representation via a contrastive loss on last-layer tokens (pull same-3D-point tokens together, push negatives apart).
- Multi-task losses help even without the heads at inference — keep the point-map/matching losses at train time, drop the heads. Stronger than VGGT’s original claim.
- Registers got promoted from artifact-prevention to real scene-level carriers: 16/frame, trained as global aggregators via register attention, and useful enough to plug (frozen) into OpenVLA-OFT as extra tokens (+1.4% avg on LIBERO, biggest on spatial/long-horizon) and to align to language (76.8% top-1). A geometric-perception module dropped into a VLA’s input, not a world model.
- Scale dominates: clean power-law gains from 0.2B→10B params and 2K→2M sequences. Self-supervised pretraining on 18M videos barely moves the needle (0.073→0.070 point error) — a hint that it’s not pure statistical pattern matching, since more unlabeled data should then help much more. Still “an open problem.”