See also Deep Q Recall dynamic programming algorithms Policy & value iteration
We have the analogous model -free TD algorithms:
Of course the value iteration on state cannot be sampled, so there’s no TD algorithm.
Q learning is an Off-Policy algorithm. It estimates the value of the greedy policy
Acting greedy all the time would not explore sufficiently.
It’s soundness depend on a new theorem:
Q-learning control converges to the optimal action-value function, , as long as we take each action in each state infinitely often.
This is different from GLIE: the policy doesn’t need to converge to greedy. Works for any policy that eventually selects all actions sufficiently often (Requires appropriately decaying step sizes , , E.g., , with )
A comparison of SARSA and Q learning
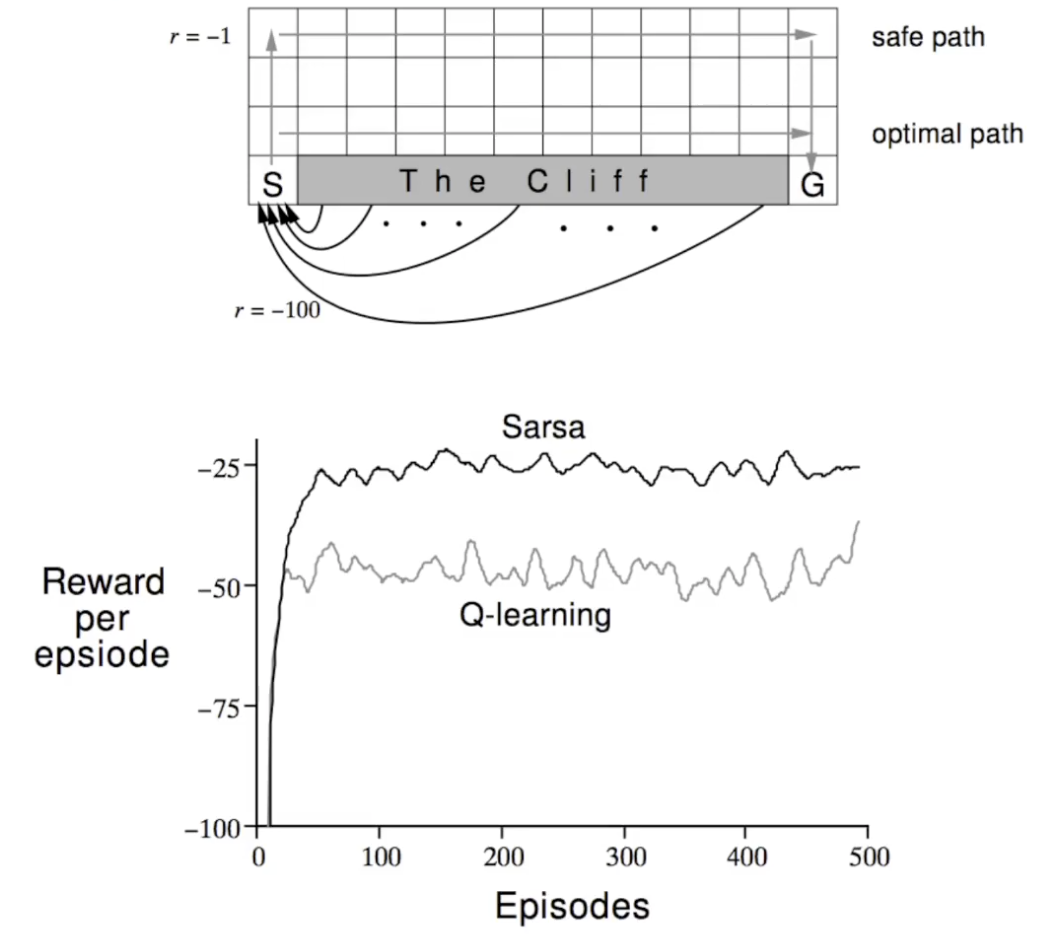 In training time, SARSA gets higher reward since it learns that walking on the edge is dangerous, and it learns a safer path. Recall it’s using -greedy for both prediction and control.
On the other hand, Q learning would stick to the optimal path, since according to its value estimation the optimal path is just the better one, since it has a larger . So it would explore that path more often and got down more often. Note the final policy may be a more optimal one.
In training time, SARSA gets higher reward since it learns that walking on the edge is dangerous, and it learns a safer path. Recall it’s using -greedy for both prediction and control.
On the other hand, Q learning would stick to the optimal path, since according to its value estimation the optimal path is just the better one, since it has a larger . So it would explore that path more often and got down more often. Note the final policy may be a more optimal one.
Overestimation
Recall
Uses same values to select and to evaluate. … but values are approximate
- more likely to select overestimated values
- less likely to select underestimated values
That “max” is persisting. Imagine you are in a state with 100 actions with stochastic outcome. If one of the action by chance got jackpot, then you would keep exploring that state. That leads to super slow convergence: blinded by overestimated values.
Another way to think about it: say we have two random variables: and ,
our q estimation is a noisy estimation, and we are using the left one to estimate the right.
Double Q-learning
Store two action-value functions: and
Each , pick or (e.g., randomly) and update using (1) for or (2) for .
This solves the issue because now the noise is decorrelated. The “max” when selecting the action may not actually leads to the “max” when actually getting the estimated Q value.
We can also extend this to SARSA.