Coming from Fitted Value Iteration, we don’t have transition dynamics. is good (we can see the same idea in Off-policy actor-critic) as the reward now does not depend on your policy, just , not .
Recall previously we had 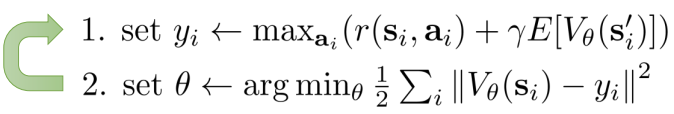 Now it’s
Now it’s 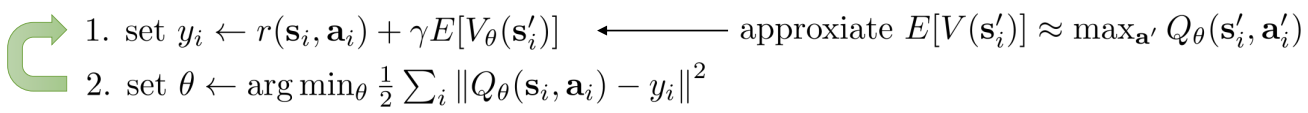
Note how the disappears, so this works even for off-policy samples.
Why fitted value iteration needs the environment but fitted Q doesn’t: In fitted value iteration, we compute . Our dataset only has one tuple — we took one action and saw one outcome. To evaluate the other actions inside that max, we’d need to know what reward and next state each action leads to, which is exactly the transition model . These are two sides of the same coin: we’re missing data for actions we didn’t take, because we lack transition knowledge.
In fitted Q iteration, there’s no max over actions at . We just use our one tuple as-is: . The max happens at and only requires forward passes through our own network — no environment interaction, no missing data.
The is "free"
This max only queries our own function approximator at different action inputs. Compare with the max in fitted value iteration, where the quantity inside the max () depends on the environment’s dynamics. That’s the fundamental asymmetry.
This is off policy, and the only show up implicitly in that , since we know it’s max by asking the policy to estimate at . (Our policy is greedy, so policy and Q are basically the same).

We can make it online:
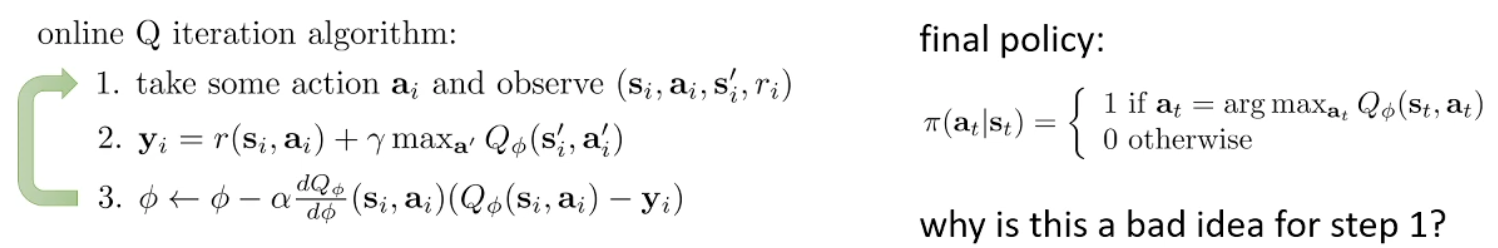 And for exploring in step one we can use Greedy and epsilon greedy. You can see more exploration way there too.o
And for exploring in step one we can use Greedy and epsilon greedy. You can see more exploration way there too.o
Also see the traditional Q learning. The change are basically if we use batch / function approximation.
Now we have correlated samples, on to the Deep Q.