Note taken with Claude Opus 4.8, from a reading discussion with Claude Sonnet 4.6.
UMI is a data-collection system masquerading as a robot-learning paper. Almost nothing in it is algorithmically new — the policy is an off-the-shelf Diffusion Policy, the latency handling is textbook MPC, the “stereo” is a decades-old optical trick. What’s actually good is the interface: a handheld gripper rig that lets a human collect demonstrations in the wild whose observation and action streams match what a robot will later see and do. The whole paper is an exercise in closing the train/deploy gap by construction, and most of its named “contributions” (the HD / PD taxonomy) are post-hoc rationalizations bolted onto that one idea. That’s a legitimate kind of contribution — but it’s worth reading the note knowing which 10% is the bet and which 90% is careful plumbing.
The bottleneck it attacks: where does manipulation data come from?
Imitation learning needs demonstrations, and there are two established ways to get them, each broken in its own way:
- Teleoperation (puppeteering a real robot, à la ALOHA/GELLO) gives perfectly aligned observations and actions — but it needs the robot present during collection, is slow and expensive, and confines you to wherever the robot lives. No “in the wild.”
- Human video (YouTube, egocentric footage) is abundant and diverse — but it has no action labels and a large embodiment gap (human hand ≠ robot gripper), so getting executable robot actions out of it is a research problem in itself.
Handheld grippers are the middle ground: a human holds an actual robot-style gripper with a camera on it, so you get the human’s flexibility and near-robot observations. The catch that prior handheld work never beat: recovering precise 6-DoF actions from these rigs (monocular SfM, scale ambiguity, motion blur) was unreliable, so they were stuck on quasi-static pick-and-place and couldn’t transfer dynamic, bimanual, or precise skills. UMI’s bet is that with the right sensing (fisheye + mirrors + IMU-aided SLAM) and the right interface (latency matching + relative-trajectory actions), the handheld approach can finally capture and transfer those harder skills — zero-shot, by only swapping training data per task.

The actual idea: close the observation gap by construction
The core move is to fix a fisheye camera (a GoPro) rigidly to a handheld gripper, in the same physical configuration that the camera will occupy when the gripper is mounted on a real robot. Collect human demos with this rig; the robot later sees essentially the same pixels and executes essentially the same end-effector motions. No teleoperation, no robot needed during collection, no observation distribution shift.
That single design decision is the paper. Everything the authors list as separate “Hardware Design” (HD) and “Policy Interface Design” (PD) principles flows from it or pads it:
- Wrist/gripper-mounted camera (HD). The paper gives a laundry list — mechanical robustness, no extrinsic calibration, camera motion as augmentation — but the real and only reason is the one above: the camera travels with the gripper so the human’s view is the robot’s view. The rest is filler to fill a subsection.
- Fisheye lens. Wide FOV to keep the scene and both mirrors in frame; cheap and gets IMU + synchronized timestamps for free from the GoPro.
The GoPro choice is the quiet hero
Using a consumer action cam gives synchronized IMU, GPS-clock timestamps, and rolling-shutter metadata essentially for free. The whole “in-the-wild” story only works because the sensing hardware is commoditized. This is a hacker’s paper, not an optics-lab paper.
The mirror trick is catadioptric stereo they decline to name
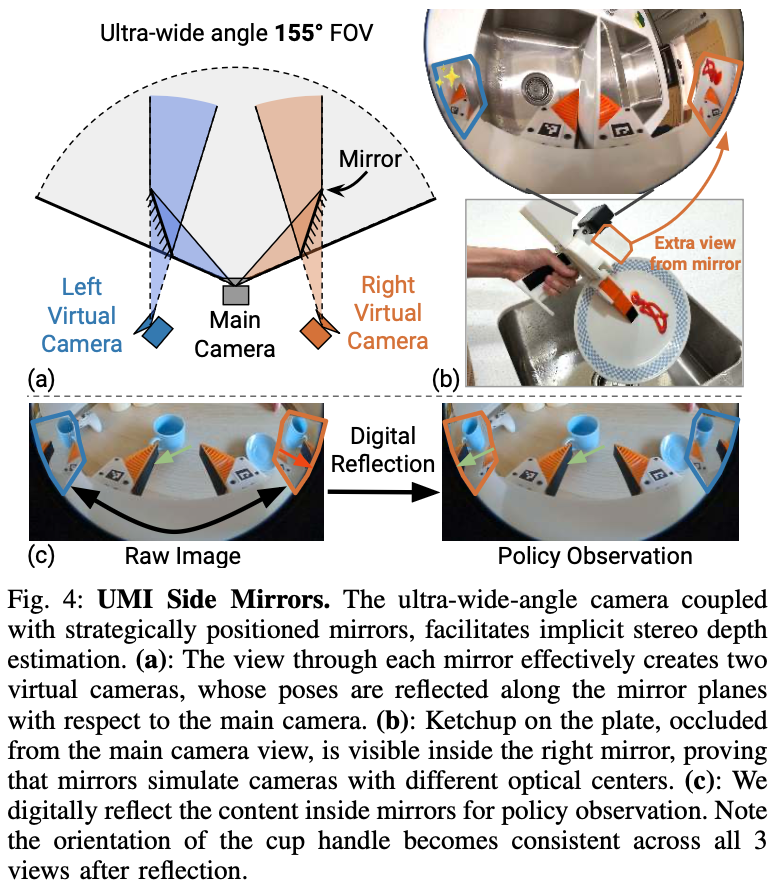
Flat mirrors taped to the sides of the gripper give the single fisheye camera two extra virtual viewpoints — implicit stereo for depth, from one cheap camera.
This is catadioptric stereo, an optics idea going back to the early 2000s (single-camera stereo via prisms/mirrors). The paper never uses the term. Charitable read: they rediscovered it from first principles as practitioners. Less charitable read: naming it invites “so what’s new?” — and forces them to explain why they don’t do explicit disparity estimation, why flat vs. curved mirrors, etc. “Implicit stereo” sidesteps all of it. What is genuinely new is the application: physical mirrors on a handheld gripper, feeding raw views into a learned policy that consumes the depth cue implicitly rather than reconstructing a depth map. Old optics, new domain.
Why does digitally flipping the mirror images help — and why won't they say?
Empirically, reflecting the mirror regions before feeding them in improves performance, and the paper waves this away. Their implied reason is vision-encoder equivariance, but that doesn’t hold up:
- CNNs are translation-equivariant (conv) and translation-invariant (pooling), but not reflection-equivariant. A mirrored region produces genuinely different activations, so a CNN should be able to learn “this patch is a mirror” and treat it accordingly.
- So the honest explanation is probably not equivariance at all — it’s inductive bias / sample efficiency. With only hundreds of demos, handing the model three geometrically consistent views is easier to learn than asking it to discover the mirror geometry itself. ViT/CLIP pretraining priors about “normal” orientation may make this worse, but the core point is the data is small.
A powerful model with enough data should learn it implicitly; they just don’t have enough data, so the flip is a free win they don’t bother to justify.
”Latency handling” is just MPC, done carefully
The framing oversells this. Mechanically it’s receding-horizon control: the policy predicts an action chunk starting at the observation time, the first actions are already stale by the time inference + observation latency has elapsed, so they’re discarded and only actions timestamped at/after execution time are run. Plan, shift, execute the fresh part, replan. Standard.
What’s actually defensible here:
- The problem framing. Prior handheld-gripper work collected data with zero latency (a GoPro captures obs and action synchronously) but deployed onto robots with real latency — and never accounted for the resulting train/test mismatch. UMI’s point is “here’s the distribution shift you’ve been ignoring,” not “here’s a new latency algorithm.”
- The measurement methodology. The real engineering contribution is measuring per-hardware latencies rigorously rather than guessing — a rolling QR-code trick for inter-stream alignment and cross-convolution for gripper-actuation latency calibration. Hardware-agnostic and reproducible.
The ablation (dynamic tossing: 87.5% → 57.5% without latency matching) exists to prove the problem is real, not that the solution is clever. The solution is obvious; the discipline of measuring is the point.
Action representation: relative trajectory, not delta, not absolute
A genuinely sensible (if not novel) choice. Three options for representing the action sequence:
- Delta actions (each step relative to the previous step) — bad; error accumulates. It remains embarrassingly common in the literature and shouldn’t be.
- Absolute actions (global/SLAM frame) — bad; needs precise calibration between the SLAM coordinate system and the robot base, which is fragile.
- Relative trajectory (the whole chunk expressed relative to the end-effector pose at the moment inference begins) — their choice. The reference frame travels with the gripper and resets every inference step, so drift never accumulates and the policy is robust to base movement and camera displacement.
It’s a local frame that’s allowed to drift slowly between resets — fine — as opposed to a global (GPS/SLAM-anchored) frame.
Cross-embodiment transfer is overstated
There’s a real tension the paper soft-pedals. HD6 filters training data by kinematic feasibility — if a demonstrated pose can’t be reached by the target robot’s inverse kinematics, it’s dropped. But that filtering is per robot, while the paper also claims checkpoints transfer across embodiments (UR5 → Franka). A policy trained only on UR5-feasible demos has never seen Franka’s reachable space.
What rescues them in practice:
- Actions are in relative end-effector space, which is largely embodiment-agnostic.
- Their tasks (cup arrangement, etc.) don’t stress kinematic limits, so filtered vs. unfiltered data is nearly identical for both arms.
- The 90% (Franka) vs. 100% (UR5) gap is exactly two joint-limit-violation failures — the contradiction quietly showing up.
Push this to a humanoid arm or a mobile manipulator with a very different reach envelope and I’d expect transfer to degrade. The practical fix is the π0-style path the authors acknowledge in limitations: treat the base policy as a prior and fine-tune per embodiment.
What it doesn’t do: per-task, from scratch
Worth being blunt because the “universal / generalizable” branding obscures it. Every task — cup arrangement, dynamic tossing, cloth folding, dish washing, in-the-wild cup arrangement — is a separate from-scratch training run (Table A1: different encoders, batch sizes, epochs, even camera counts). The generalization on offer is:
- Visual (novel objects/environments), and
- Embodiment (UR5 ↔ Franka, with the caveats above).
It is emphatically not task generalization. No shared backbone, no multitask training. UMI solves the data-collection problem and punts entirely on the task-generalization problem — which is what separates it from the generalist-policy (π0) direction despite sharing the in-the-wild data philosophy.
Implementation snapshot (ephemeral)
- Policy: Diffusion Policy — actions generated by iterative denoising conditioned on observations, chosen over regression because it represents multimodal human demonstrations (e.g. rotate-cup-CW vs. CCW) without averaging the modes into something wrong for both. Same motivation as Flow Matching-based π0; ACT-style action chunking addresses temporal consistency, a related-but-different problem.
- Diffusion details: DDIM, ~50 training steps, 16 inference steps — standard efficiency tuning to hit robot control rates.
- Latency calibration: rolling QR code for inter-stream alignment; cross-convolution for gripper actuation latency.
- Key ablation: dynamic tossing 87.5% → 57.5% with latency matching disabled.