A mixture of multiple related paper, blog post and lecture.
- The first MoE paper: Mixture of Experts
- The one that make it work at scale, with Transformers: Switch Transformers
- HuggingFace’s overview: blog post
- Mixtral: Stanford cs25 lecture
MoE routing strategies
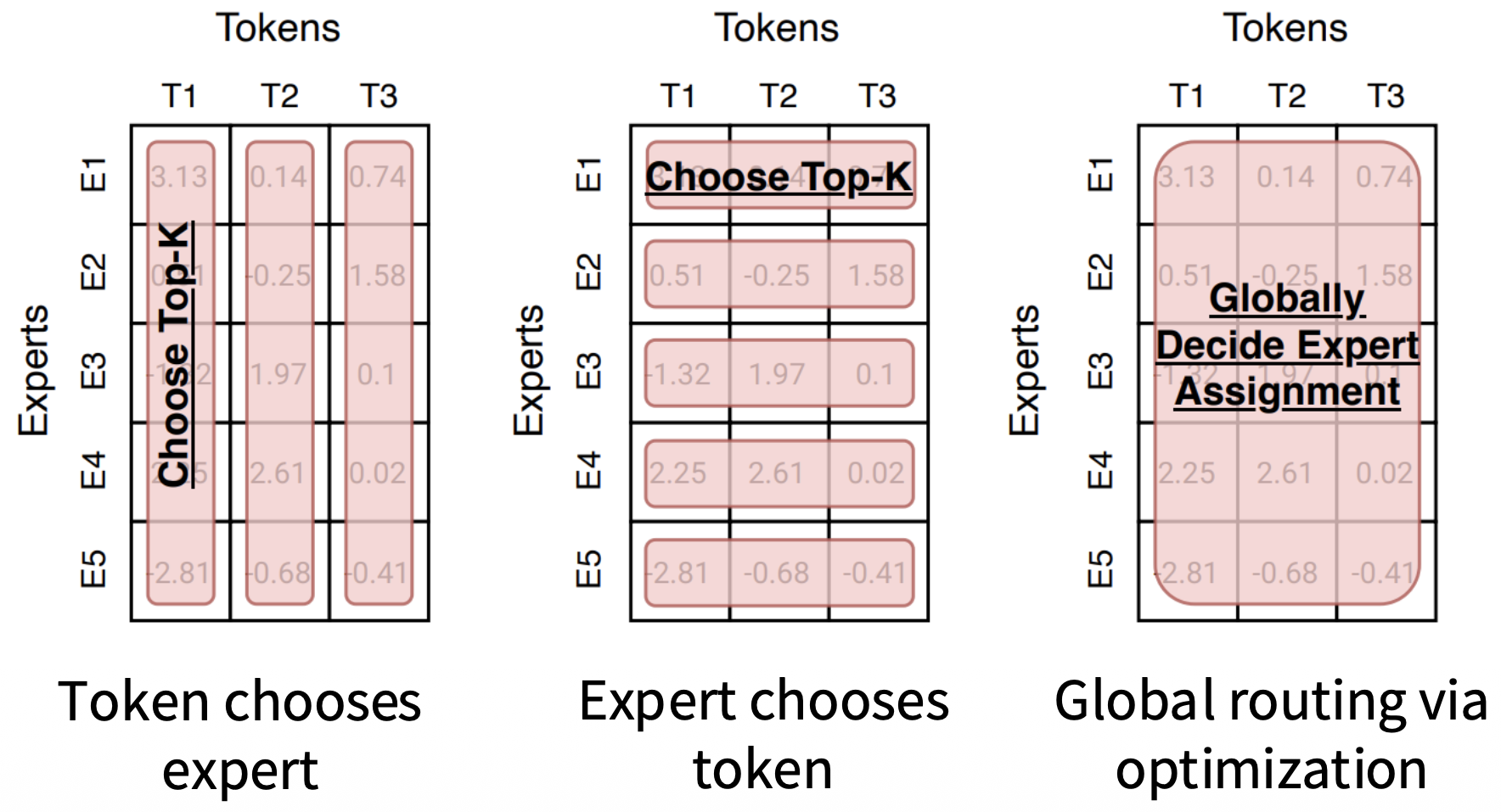
Three main paradigms, all reduce to “choose top-k” over an affinity matrix :
Token chooses expert (standard)
Each token selects top- experts from its row of . Guarantees every token is processed by exactly experts. Downside: requires auxiliary load-balancing loss or capacity buffers to avoid expert collapse.
Expert chooses token
Each expert selects top- tokens from its column of . Load balance is free by construction — every expert processes exactly tokens, no auxiliary loss needed.
Critical flaw for autoregressive LMs: token dropping is intrinsic, not a side-effect. A token ignored by all experts gets no gradient flow through any expert. In attention, low-weight tokens still participate softly; here the dispatch is hard. Fine for encoder/MLM settings (BERT-style), problematic for decoder-only models where every position must produce a valid hidden state for the next token.
Global via optimization
Treats assignment as a bipartite matching problem, jointly optimizing across all tokens and experts globally (e.g. BASE layers).
| Token → expert | Expert → token | Global | |
|---|---|---|---|
| Load balance | needs aux loss | free | depends |
| Token coverage | guaranteed | not guaranteed | depends |
| Practical use | most LLMs | encoders | rare |