Note written by Claude Sonnet 4.6 from a reading discussion on 2026-05-25.
Fast-WAM
The paper’s actual contribution is an empirical argument dressed up as an architecture paper. The architecture change is trivial — one masking decision at training time. What the paper really delivers is a controlled ablation that separates two factors everyone has been conflating: the benefit of video co-training during training, versus the benefit of explicitly imagining the future at test time. The answer is that nearly all of the WAM advantage comes from the training objective, and test-time future imagination is doing almost nothing.
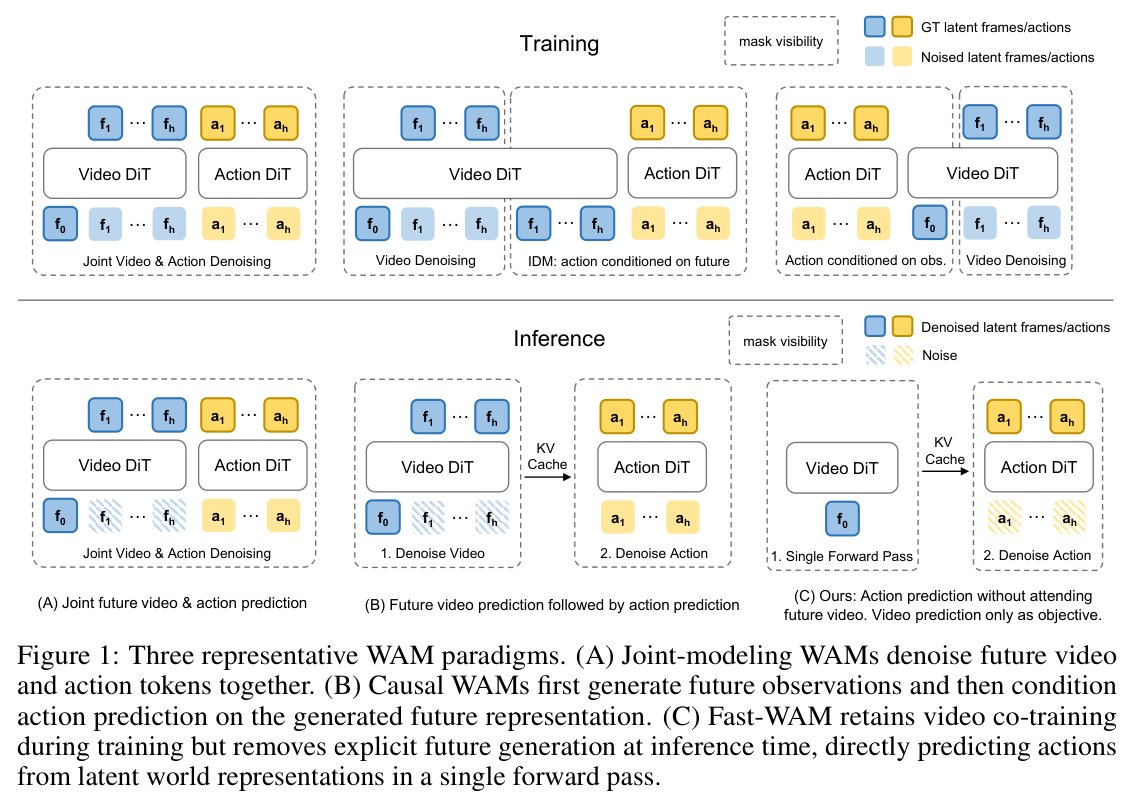
The one-trick architecture
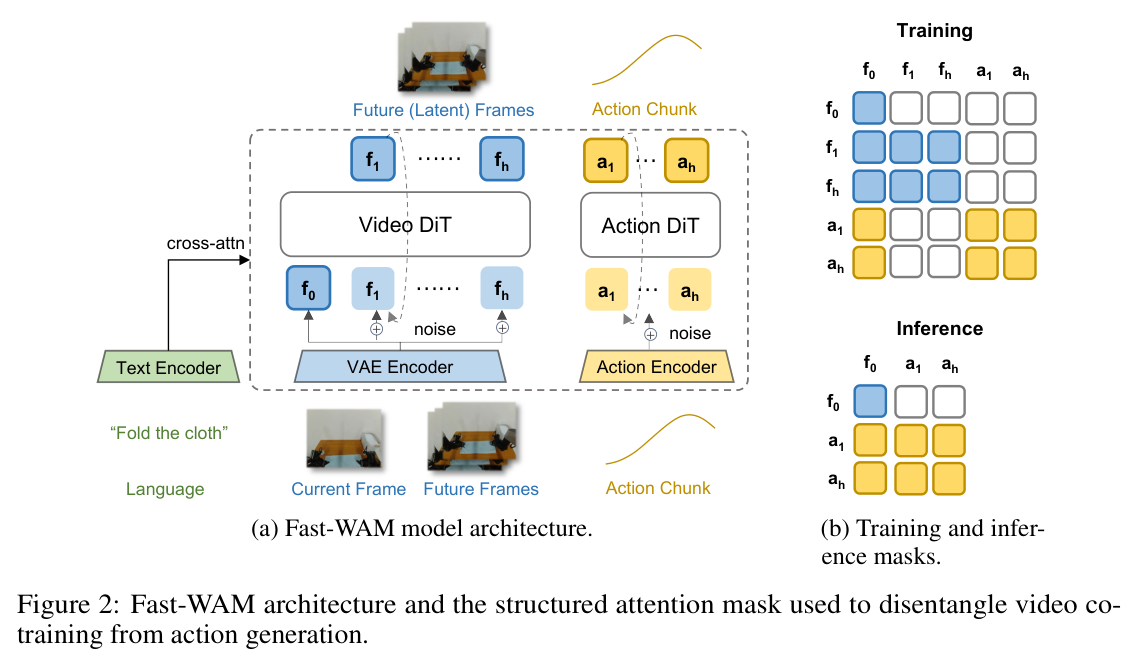
The masking insight is genuinely simple. During training, Fast-WAM runs joint video and action denoising — but with a structured attention mask that blocks action tokens from attending to future video tokens. The video branch sees future frames (and learns to denoise them). The action branch sees only the clean first frame. These two objectives share a backbone, so the world-modeling gradients still shape the representations that actions are generated from — but action tokens never become functionally dependent on predicted future video.
At inference time, this mask is what makes dropping the video branch legal. Since action tokens were never trained to attend to future video tokens, you can remove the future video branch entirely. Pass the first frame through the video DiT in a single forward pass, get a latent world representation, denoise actions conditioned on that. No iterative video denoising, no joint sampling. 190ms vs 580–810ms for the imagine-then-execute variants.
What the ablation actually says
The controlled variants:
- Fast-WAM — masked training, no future video at inference (ours)
- Fast-WAM-Joint — unmasked training, joint denoising at inference (mirrors paradigm A, e.g. DreamZero)
- Fast-WAM-IDM — video-then-action pipeline at inference (paradigm B)
- Fast-WAM w.o. video co-train — mask removed, video objective also removed; same architecture and inference as Fast-WAM
On RoboTwin: Fast-WAM (91.8%), Fast-WAM-Joint (90.6%), Fast-WAM-IDM (91.3%), no video co-training (83.8%). The gap between Fast-WAM and the imagine-then-execute variants is ~1pp. The gap from removing video co-training is ~8pp. On LIBERO the pattern holds. On the real-world towel-folding task, removing video co-training collapses success rate to 10% — more dramatic than any test-time variation.
The practical implication: the community has been building increasingly elaborate test-time imagination pipelines assuming that’s what’s working. This paper says: the representations shaped by video prediction during training are doing the heavy lifting. Whether you actually generate future frames at inference is nearly a rounding error.
What the paper doesn’t spell out: text conditioning
The paper notes that text conditioning uses cross-attention, inherited from the Wan2.2-5B backbone. It doesn’t explain the Q/K/V breakdown. Worth being explicit since this came up:
- Queries (Q) come from the video/action tokens
- Keys (K) and Values (V) come from frozen T5 text encoder outputs
Information flow is strictly one-directional: visual and action tokens query into the fixed T5 embeddings; text never reads back. The T5 output is a static lookup table that every token group queries in parallel, each weighting which parts of the instruction matter to its own computation.
The contrast with MMDiT is instructive. MMDiT treats text tokens as full peers — they emit queries and attend back to image tokens, enabling tight bidirectional alignment. That’s valuable for image generation where spatial text-image correspondence matters. Here, the task instruction (“fold the cloth”) is a global broadcast signal that all token groups read from uniformly; it doesn’t need to dynamically update based on what the visual tokens are doing. Cross-attention is the right tool. It also keeps text out of the self-attention sequence entirely, which matters when sequence length grows with video frames and action tokens.
What’s not addressed
The paper doesn’t say much about what happens when the first-frame latent is a poor anchor — highly dynamic scenes, occlusion-heavy tasks, or anything where the initial observation genuinely undersells what’s about to happen. Fast-WAM-IDM (which does generate future video and conditions actions on it) edges out Fast-WAM on LIBERO-Long (98.0 vs 95.2), suggesting there may be task categories where future imagination still earns its cost. The paper notes this but doesn’t characterize when.
The authors call out larger-scale pretraining and model scaling as the next direction. Fast-WAM currently runs without embodied pretraining and still matches pretrained baselines — which is itself a strong data-efficiency argument for WAM-style training objectives — but the scaling question is genuinely open.