Referenced material:
Scaling law basically try to answer “How do the performance changes as we vary one or more inputs”?
Data scaling laws
The Kaplan one. Loss and dataset size is linear on a log-log plot. This can be understood as say, given a bunch of data, estimate the mean. The error
Chinchilla Scaling Laws
Based on my conversations with Claude Sonnet 4.6, summarized by Claude Opus 4.6.
The Chinchilla paper (Hoffmann et al., 2022) uses three independent approaches to estimate compute-optimal training configurations. All three converge on the same result:
meaning compute should scale model size and data roughly equally
Approach 1: Envelope Method
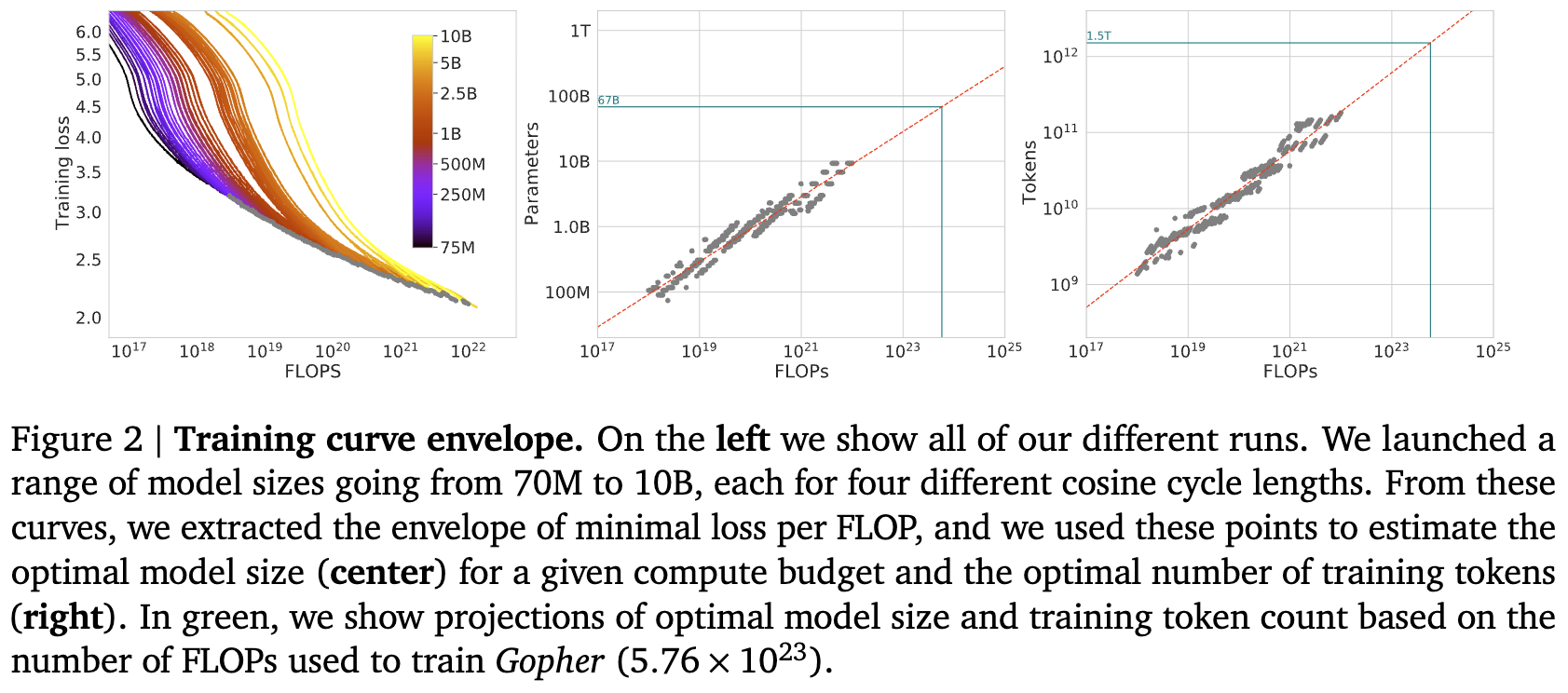
Fix a set of model sizes (70M to 10B) and for each model size, train with multiple LR decay horizons (4 per model size, spanning a 16× range). The decay horizon controls total training tokens — longer horizon means more tokens. This gives roughly ~9 model sizes × 4 horizons ≈ 36 runs.
Procedure:
- For each run, smooth the training loss curve (Gaussian smoothing, 10-step window) and interpolate to get a continuous loss-vs-FLOPs mapping.
- At each of 1500 log-spaced FLOP values, find which run (model size + token count combo) achieves the lowest smoothed loss — this traces the lower envelope.
- Each envelope point gives a triplet .
- Plot vs and vs , then fit power laws.
Why smooth?
Training loss is noisy step-to-step due to mini-batch variance. Without smoothing, the envelope would cherry-pick noise troughs rather than reflect the true underlying loss. The 10-step Gaussian window is narrow enough to denoise without distorting the trend.
Key trick
A single training run traces a trajectory through FLOP space. A 1B model trained for 100B tokens passes through on its way to . Method 1 reuses these intermediate checkpoints as data points at multiple FLOP budgets. The complication is that a model “passing through” a FLOP budget mid-training has an LR schedule tuned for a different endpoint — hence the 4 different decay schedules per model size to partially address this.
Approach 2: IsoFLOP Profiles
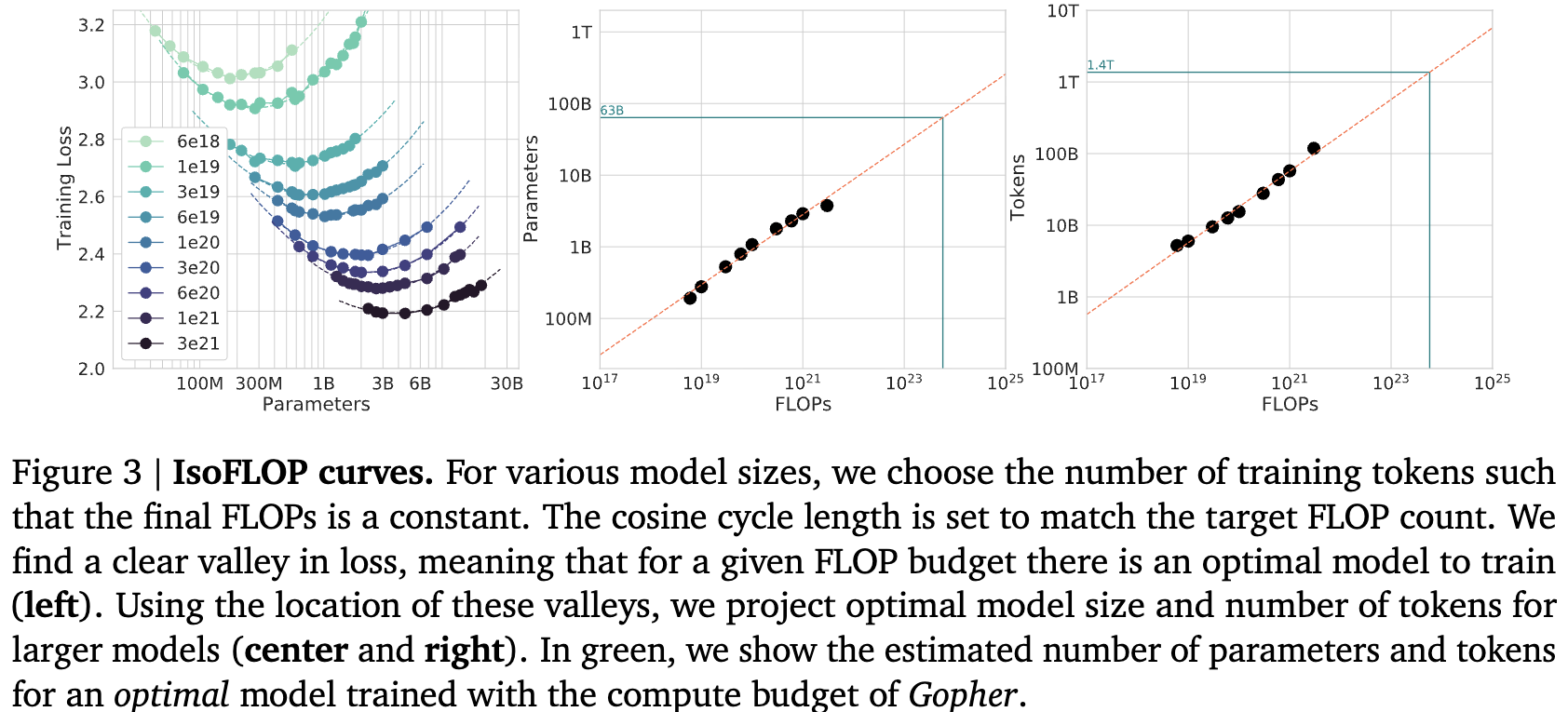
Fix a compute budget , then sweep across model sizes. Since , each choice of determines . Train models at several points along this tradeoff and record the final loss.
Plotting loss vs at fixed gives a U-shaped curve (concave in log-log space): too-small models waste compute on excess data, too-large models starve on too little data. The minimum gives .
Repeat for several FLOP budgets to get a family of IsoFLOP profiles. Read off the optimal from each, then fit .
Approach 1 vs Approach 2
These are nearly identical — both empirical, both find optimal for a given from the same data. The difference is the slice: Approach 1 takes the lower envelope across runs (IsoFLOP slices are implicit), Approach 2 explicitly groups runs by FLOP budget and finds the minimum of each U-shaped profile.
The only practical distinction is that Approach 1 reuses intermediate checkpoints across FLOP budgets via interpolation, while Approach 2 treats each run as one point — though nothing prevents doing checkpoint interpolation in Approach 2 as well.
Both assume very little (power law fit only at the end), unlike Approach 3 which posits a global parametric form . The convergence of all three on is what gives the result its credibility.
Approach 3: Just fit it
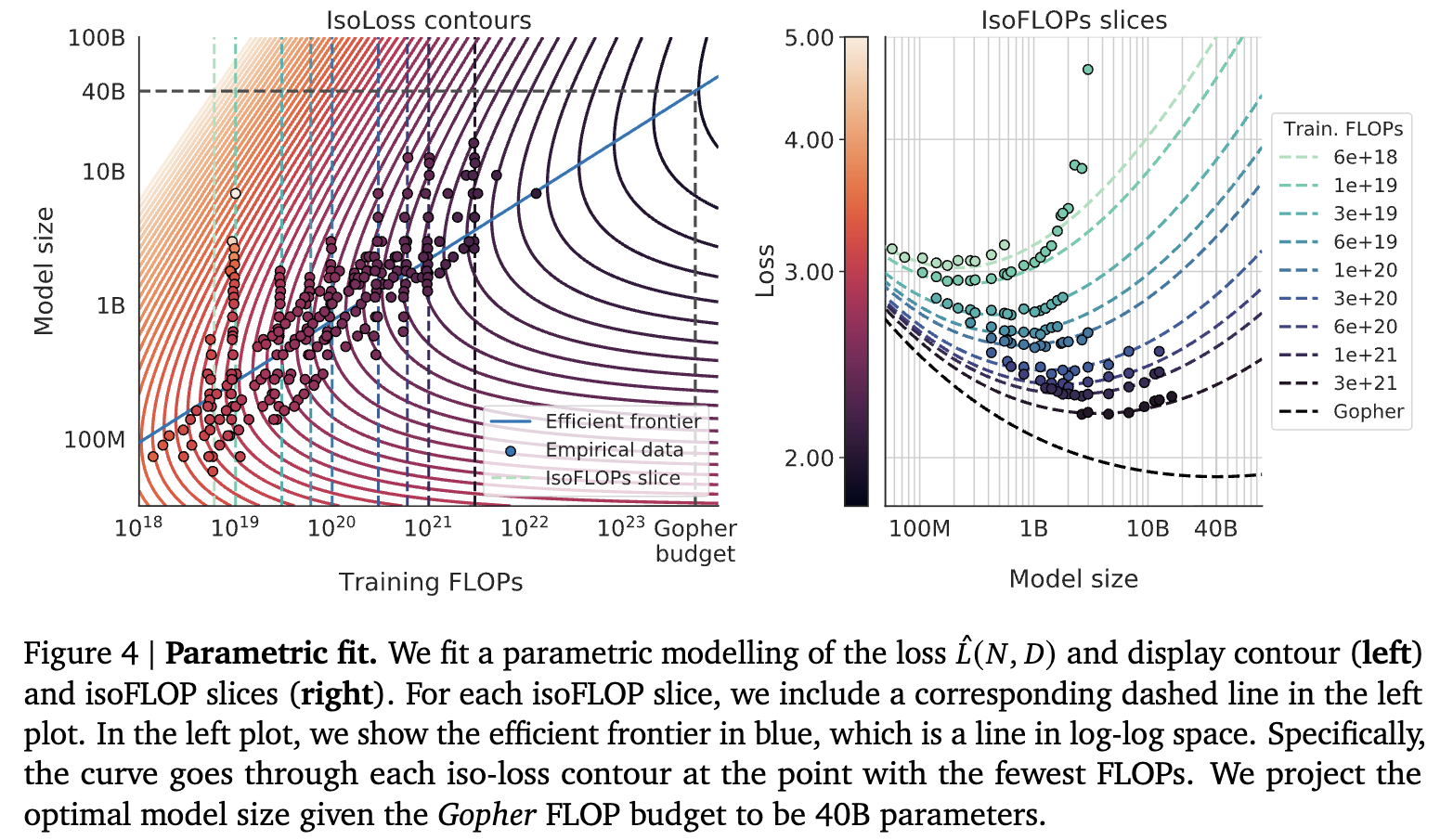
Just fit this:
They use Huber loss + L-BFGS. According to hitchhiker guide these does not matter. It’s just fitting anyway.
Now if we say we want to find the most compute efficient model, then we’re basically fixing .
WSD Schedules and Scaling Law Experiments
A major limitation of Approach 1 with cosine schedules: the LR decay horizon must match the intended training length, so you need separate runs for each token budget. WSD (Warmup-Stable-Decay) schedules fix this.
With WSD, you train one long run in the stable phase and branch short cooldowns from intermediate checkpoints. Each cooldown yields a properly-trained model for that FLOP budget. This makes Approach 1 much cleaner and more compute-efficient — the LR schedule mismatch problem disappears.