Source: CS285, 2023, Lecture 6.
This is normally briefly covered in The real overview of basics, but it’s worth considering why do we actually introduce it.
Without the discount factor, for infinite length episode, can get infinitely large. One simple trick is to say better get reward sooner than later, and introduce the , which really is changing the MDP.
changes the MDP:
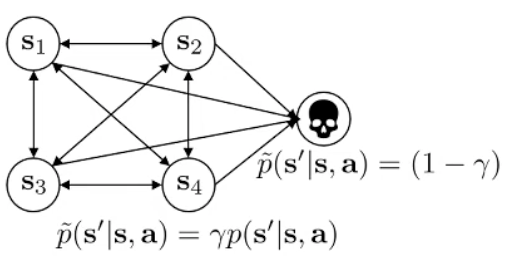
Note that how we handle the does makes a difference. See the paper Bias in Natural Actor-Critic Algorithms for more.
Consider how do we add for Policy Gradient with causality optimization.
option 1:
option 2:
If you work out the math and expand it, option 2 is the more correct one since it also penalize previous decisions, not only reward. In practice, we use option 1 though, since we want our policy to run infinitely long and we want average reward really, so option 1 may be a be a better choice.