TuSimple’s approach for lidar point map object detection that have good result and faster than previous approaches.
[Introduction](sst, page 1)
Why the author thinks the usual feature pyramid style detection does not work well in 3D object detection:
- The objects are small, like pedestrian in a large perception field. Detection on this tiny scale is hard.
- At least for autonomous driving, we don’t care about multiple scales, like a vehicle is always this size. If we don’t need multiple scales, then we don’t really need the downsampling operators and feature maps at different scales etc. That’s where the name Single Stride comes from. That leads to two issues though:
- Increase of computation cost.
- Decrease of reception fields (if we are using traditional CNN) Both problems are solved by sparse transformer. In this paper, they call it Sparse Regional Attention (SRA), and the network Single-stride Sparse Transformer (SST). This is heavily inspired by Swin Transformer, more on that later.
BTW, they [conducted studies](sst, page 3) of “what if we don’t worry about latency and just change the existing model to use single stride”. The baseline of course is PointPillars.
[Architecture](sst, page 4)
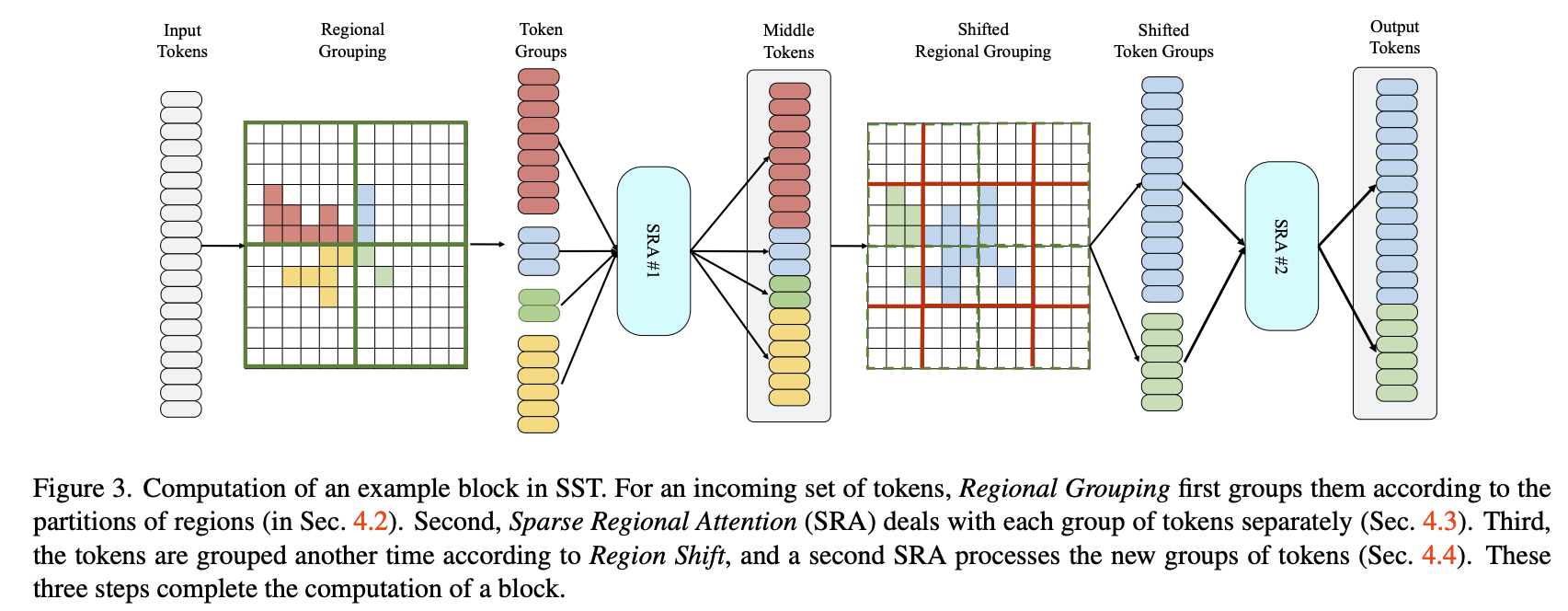
- Voxelize the point cloud following PointPillars. so we got 2d pseudo-image. Recall PointPillars then uses a PointNet to get global info. We don’t do it here.
- Divide the space into non-overlapping regions (the green boxes) according to physical location.
- In each of the region, do sparse attention, which basically means only pass in the non-empty voxel as token. In training time each region contain different number of tokens. So region batching is applied here:
To utilize the parallel computation of modern devices, we batch regions with similar number of tokens together. In practice, if a region contains the tokens with number , satisfying:
then we pad the number of tokens to . With padded tokens, we can divide all the regions into several batches, and then process all regions in the same batch in parallel.
sst, page 4. Optimizing this part is the main motivation of Flatformer.
4. Now inspired by Swin Transformer, do region shift between layers.
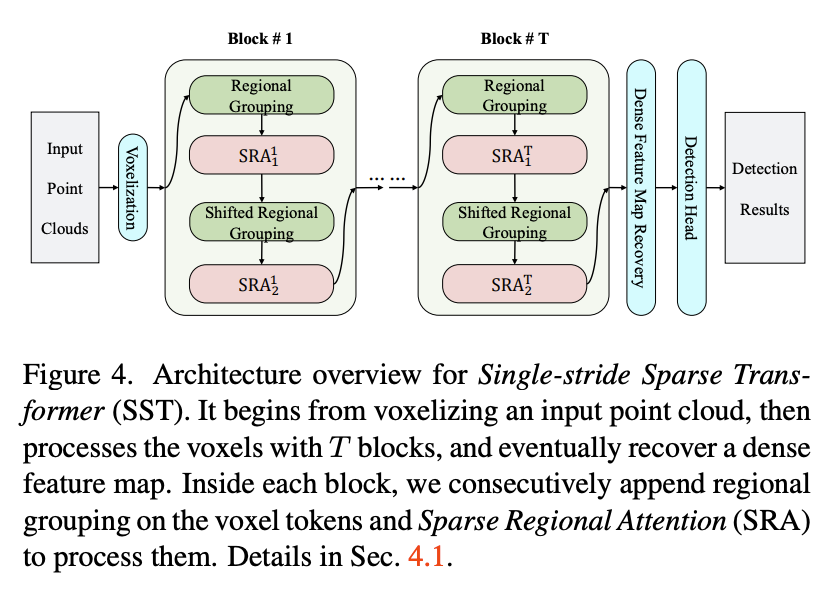 In short, this is single stride + Swin Transformer + PointPillars.
In short, this is single stride + Swin Transformer + PointPillars.