Makes SST faster. If they are from the same lab, the name would just be FastSST.
Note they claim they are 5 times faster than SST , don’t trust that. They count in speed boost by FlashAttention and Triton kernel in FFN.
Some background: why were point cloud transformers slow? Global attention is of course slow. Local attention suffer from neighbor preparation overhead. Window attention have different number of points in a window so they need to do batch padding.
Well wait, what if we fore them to have the same number of points in the window? That’s basically this paper.
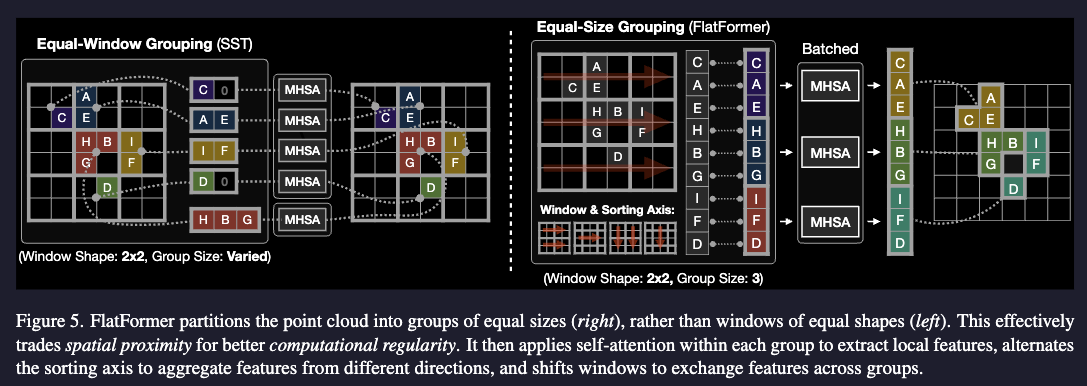 Let’s just make a way of having an equal number of points per group, and make the group preserve locality as much as possible.
Let’s just make a way of having an equal number of points per group, and make the group preserve locality as much as possible.
With a point cloud ,we first quantize the coordinate of each point to
where is the window shape. Next, we sort all points first by window coordinates and then by local coordinates within the window. This step turns the unordered point cloud into an ordered one, where points within the same window will be next to each other. flatformer, page 4
Then we just do equal size grouping. The image shows a “good case”. You can also imagine the is around the left boundary. In that case it’s not close to and at all. Surprisingly this doesn’t matter much to the network.
There is a trade-off: equal-window grouping maintains perfect spatial proximity (i.e., each group has the same radius) but breaks the computational regularity, while equal-size grouping ensures balanced computation workload (i.e., each group has the same number of points) but cannot guarantee the geometric locality. We show in Section 5.3 that computation regularity is more important since spatial irregularity can be partially addressed by our algorithm design: i.e., window-based sorting offers a fairly good spatial ordering, and self-attention is robust to outliers (i.e., distant point pairs).
In different attention block, we alternate between sort by or axis first, just like how in other works we decompose convolution to and blocks.
There’s also Swin Transformer style window shift, where the window got shifted.y
Interestingly, despite the fact that our sorting strategy does not guarantee the windows to be geometrically regular as in SST, FlatFormer still consistently outperforms SST in all three classes.
flatformer, page 7. So the author doesn’t understand why either. There’s also an ablation study shows using group size with of window size provide the better result.
Lineage
I feel it also shares the same idea with MLP Mixer: two complementary cheap operations compose into global coverage, without needing explicit long-range attention or hierarchical pooling.