The majority of the content of this note comes from a nice blog from PyTorch team. It covers mainstream method up to Sep 2025.
So for LLMs we have “pre-training”, which is large scale training with the objective being “next word prediction”. The “post-training” let it learn the rules (for example, in conversation settings), or do some RL.

First there’s SFT.
 Then there’s DPO.
Finally we can do online RL, which nowadays is often tied to PPO.
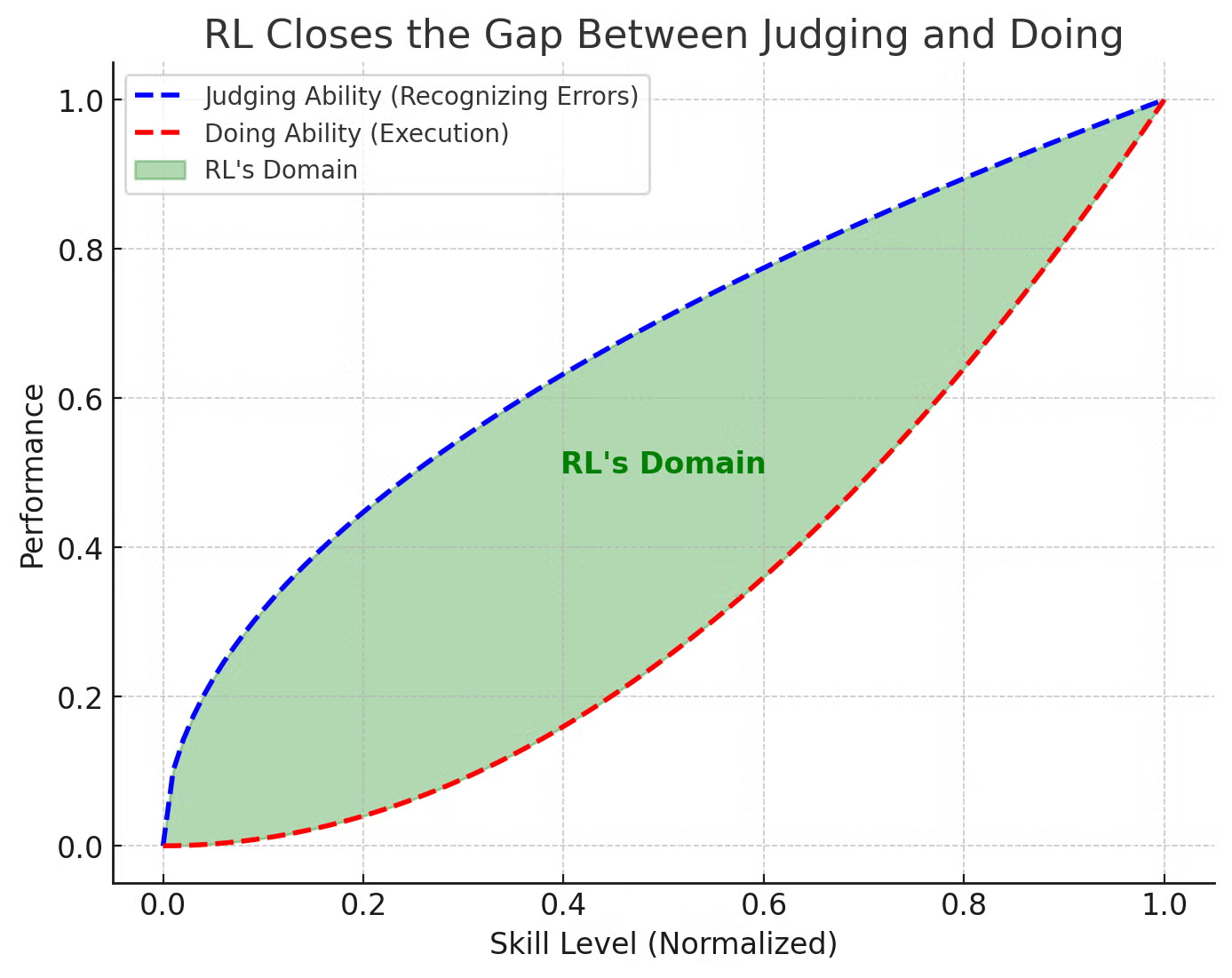
Other than RLHF, we can do more RL, since it’s basically building reward pipeline by mixing Software 1.0 and 2.0. You can imagine we have a sophisticated reward shaping pipeline. Just judge it, rule based or LLM judge.
Then there’s DPO.
Finally we can do online RL, which nowadays is often tied to PPO.
Other than RLHF, we can do more RL, since it’s basically building reward pipeline by mixing Software 1.0 and 2.0. You can imagine we have a sophisticated reward shaping pipeline. Just judge it, rule based or LLM judge.
Test-time compute and reasoning
We don’t know how OpenAI does it, but we know how DeepSeek R1 does it. Basically just let it think and that’s it.
the most surprising finding of the DeepSeek R1 paper was that you don’t need a super clever setup to induce this learning. In fact, they show that simply providing the model the space to think (by simply instructing it to fill text between a
<think>token and a</think>token, and for that text not to be empty.
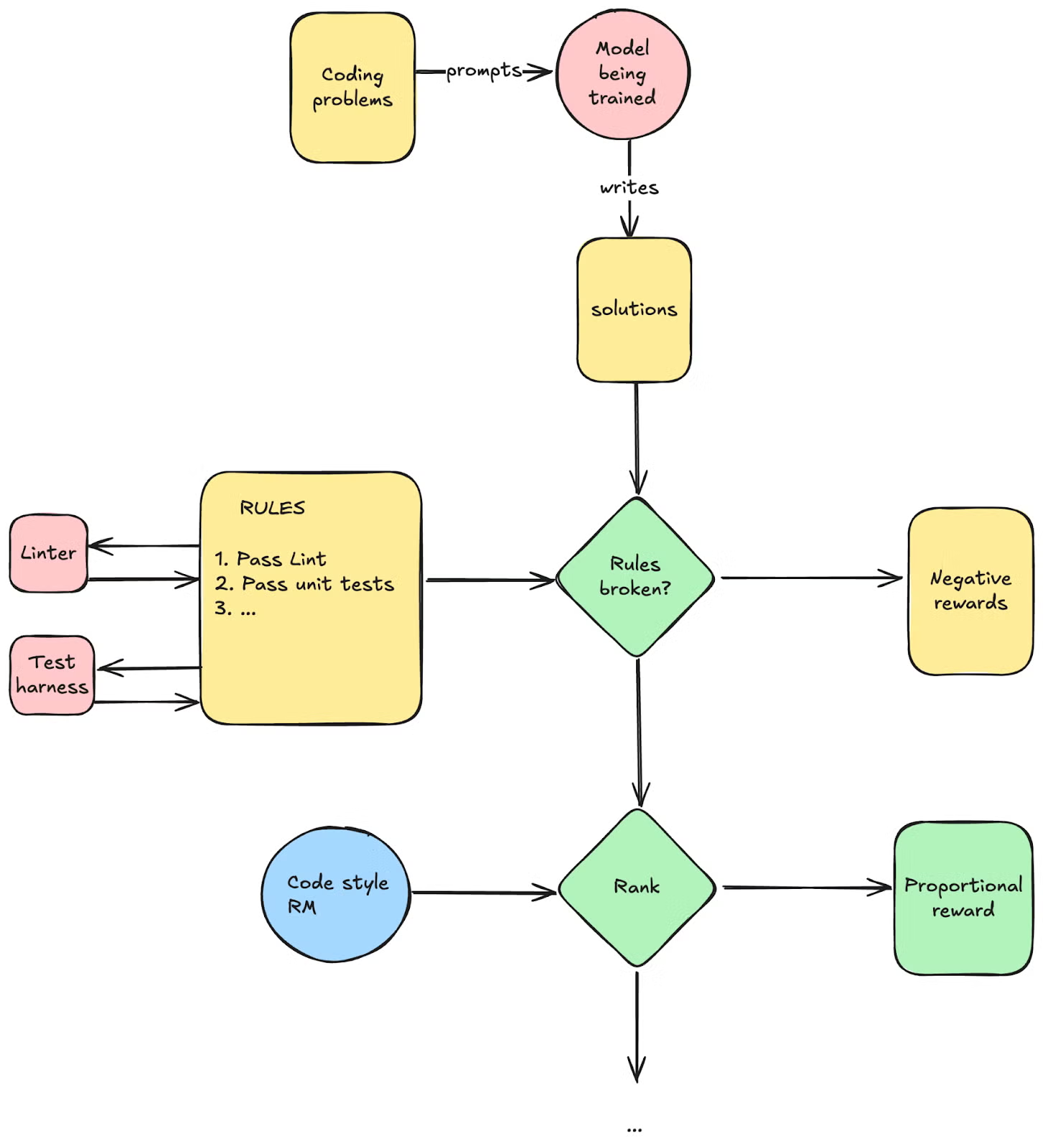
The reward modeling:
Accuracy rewards: The accuracy reward model evaluates whether the response is correct. For example, in the case of math problems with deterministic results, the model is required to provide the final answer in a specified format (e.g., within a box), enabling reliable rule-based verification of correctness. Similarly, for LeetCode problems, a compiler can be used to generate feedback based on predefined test cases. Format rewards: In addition to the accuracy reward model, we employ a format reward model that enforces the model to put its thinking process between ‘
’ and ‘ ’ tags.|