Distill CLIP embeddings to 3D space for querying, by training a NeRF with extra embeddings.
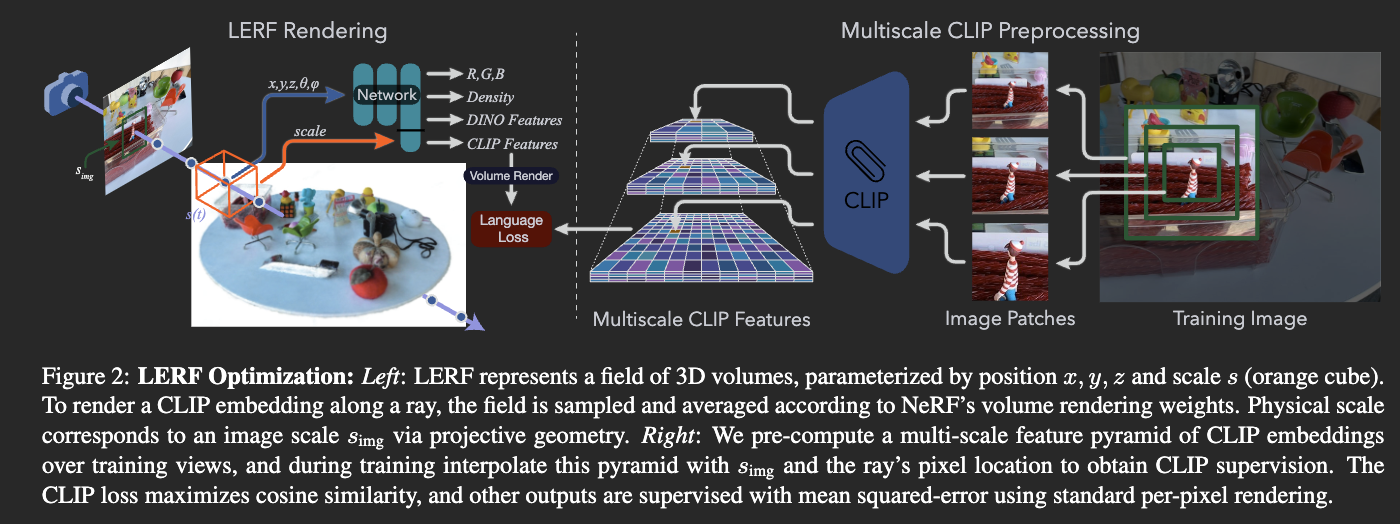
Volumetric rendering and training
Recall in NeRF the input is position and view direction . For text embedding, in addition to that along the ray, we also take scale as an input. It’s basically a frustum along the ray. The integration works just as before: we not only can integrate color, we can also integrate whatever embedding we want. So in this case, for each sampled point, we just come up with some embedding, volume render it, then compare with the ground truth.
For the ground truth, computing CLIP feature for each point on the ray in different scale on the fly is slow. (Recall in Hierarchical volume rendering the sampled point may change dynamically) . So we just precompute a bunch of them and then do trilinear interpolation.
DINO is also involved here, without it the relevancy map does not look good. That’s understandable as as long as there’s something there, CLIP would get some embedding, with no guarantee of edge sharpness for segmentation. So we also try predict DINO features for each pixel and compare with the ground truth one when rendered.
Querying LERF
When the user provide a query, we return the sampled point and scale that highest relevancy score.
To assign each rendered language embedding a score, we compute the CLIP embedding of the text query , along with a set of canonical phrases .
The score is computed as
All renderings use the same canonical phrases: “object”, “things”, “stuff”, and “texture”. We chose these as qualitatively “average” words for queries users might mak
So this essentially pick “how much closer is rendered embedding towards the query, compared with to the canonical one”.
The scale is selected by testing all the score and pick the one with highest score.