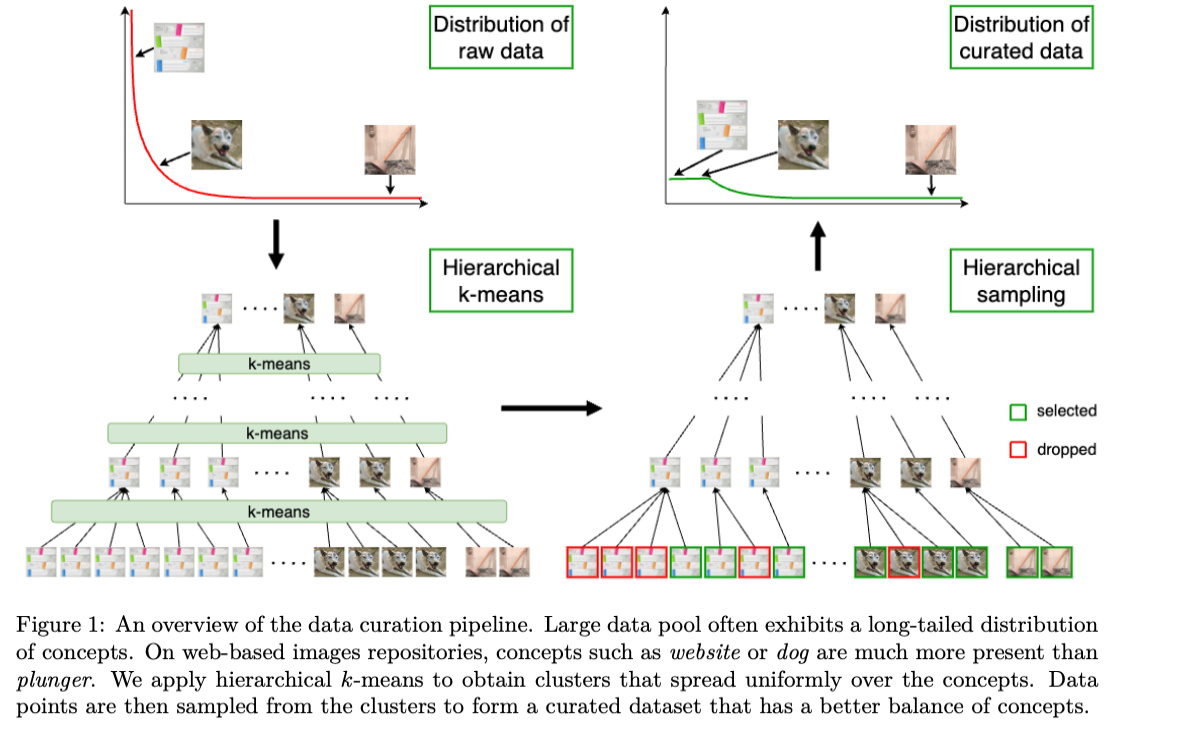
We want to curate data. More specifically, for self supervised learning.
Here’s the poorly plotted overview.
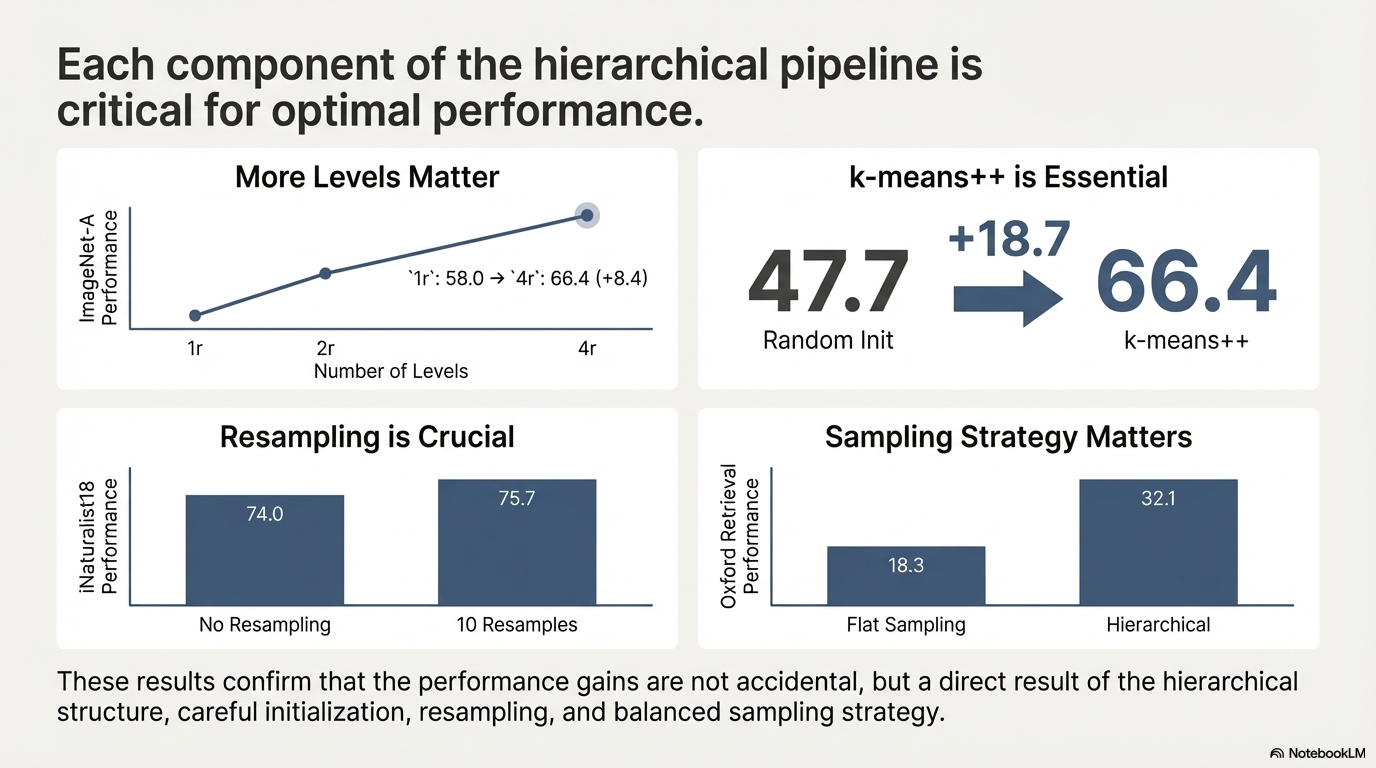
First, it seems like a good dataset not only should be large and divers, it should also be balanced. This is shown by training on artificially unbalanced ImageNet.
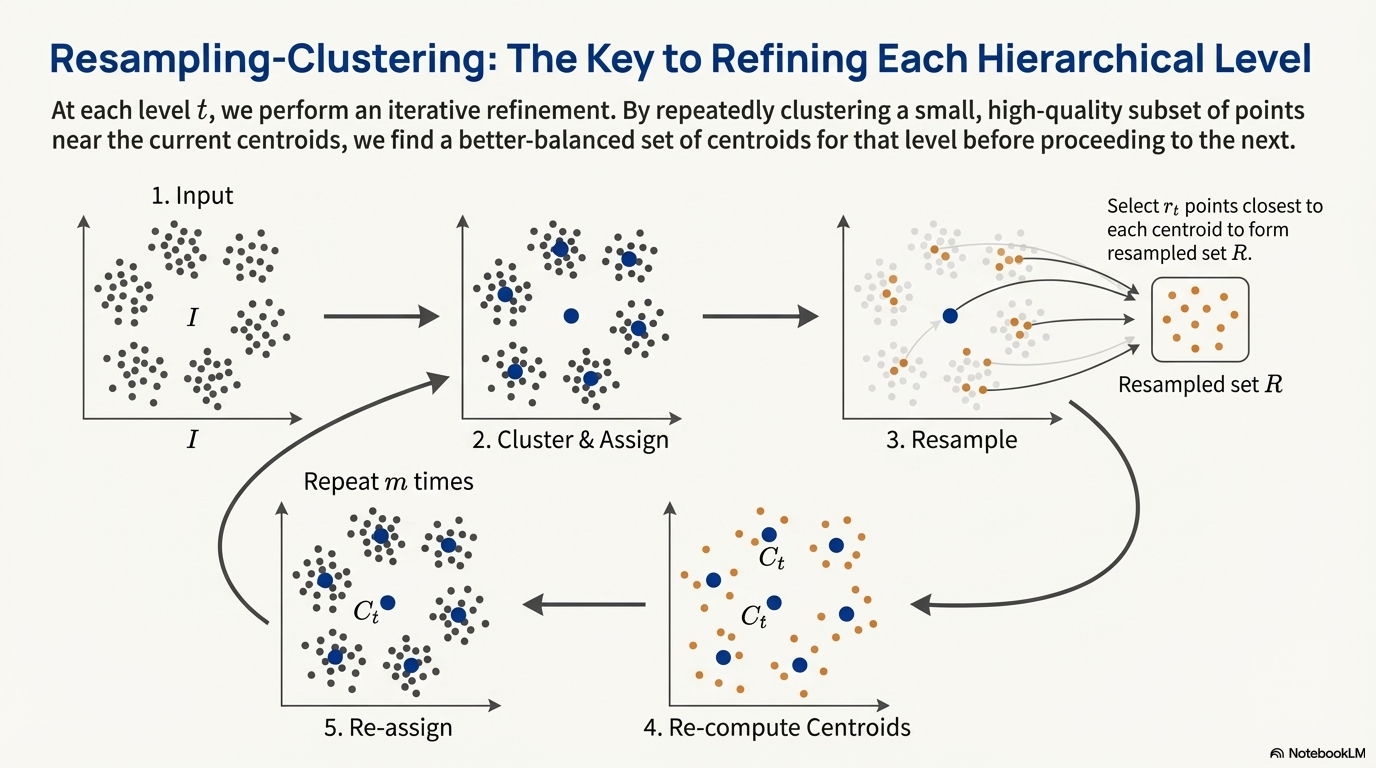
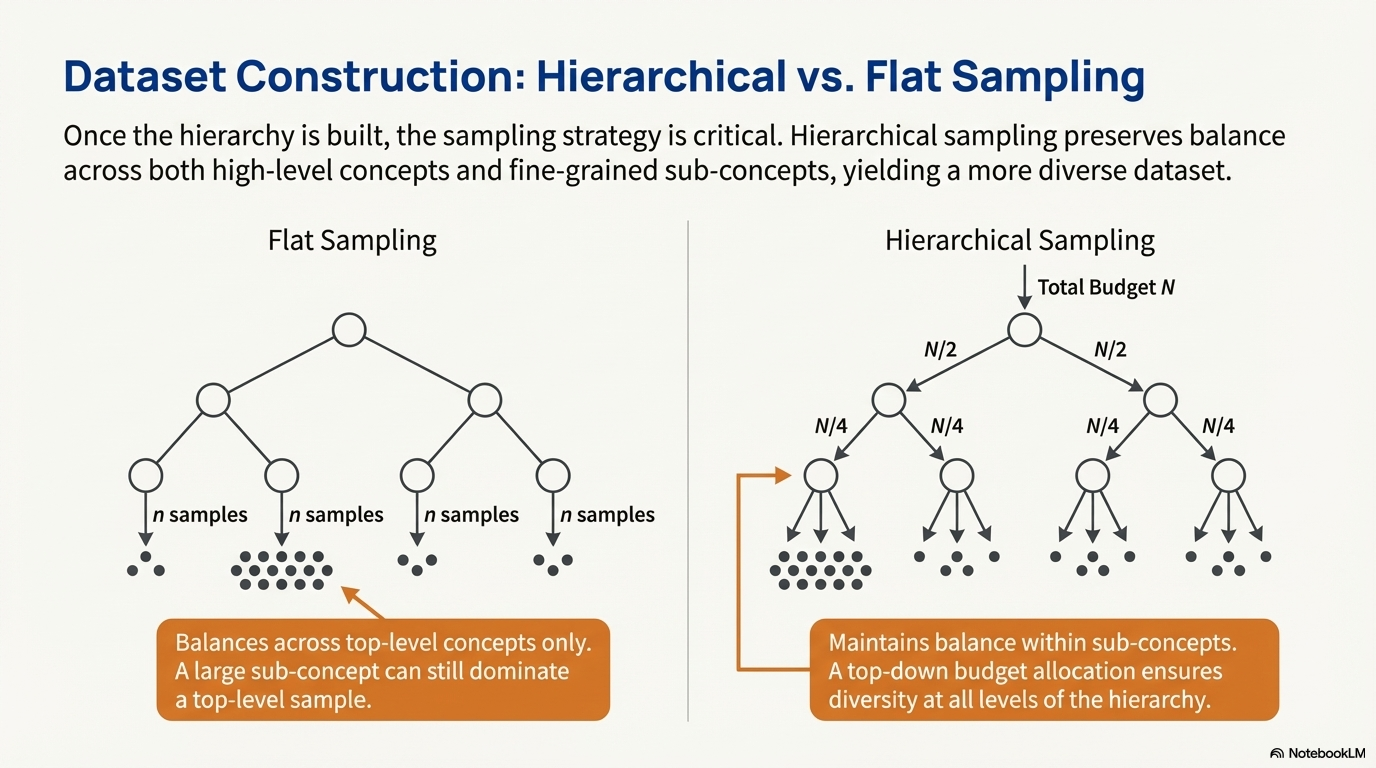
One way to do that is to assign “concept” to each sample and uniformly sample that. We can approximate that by clustering based on embeddings (In this paper they use DINOv2). Do notice that a sample may have multiple concepts, and this cluster approach seems like an approximation.
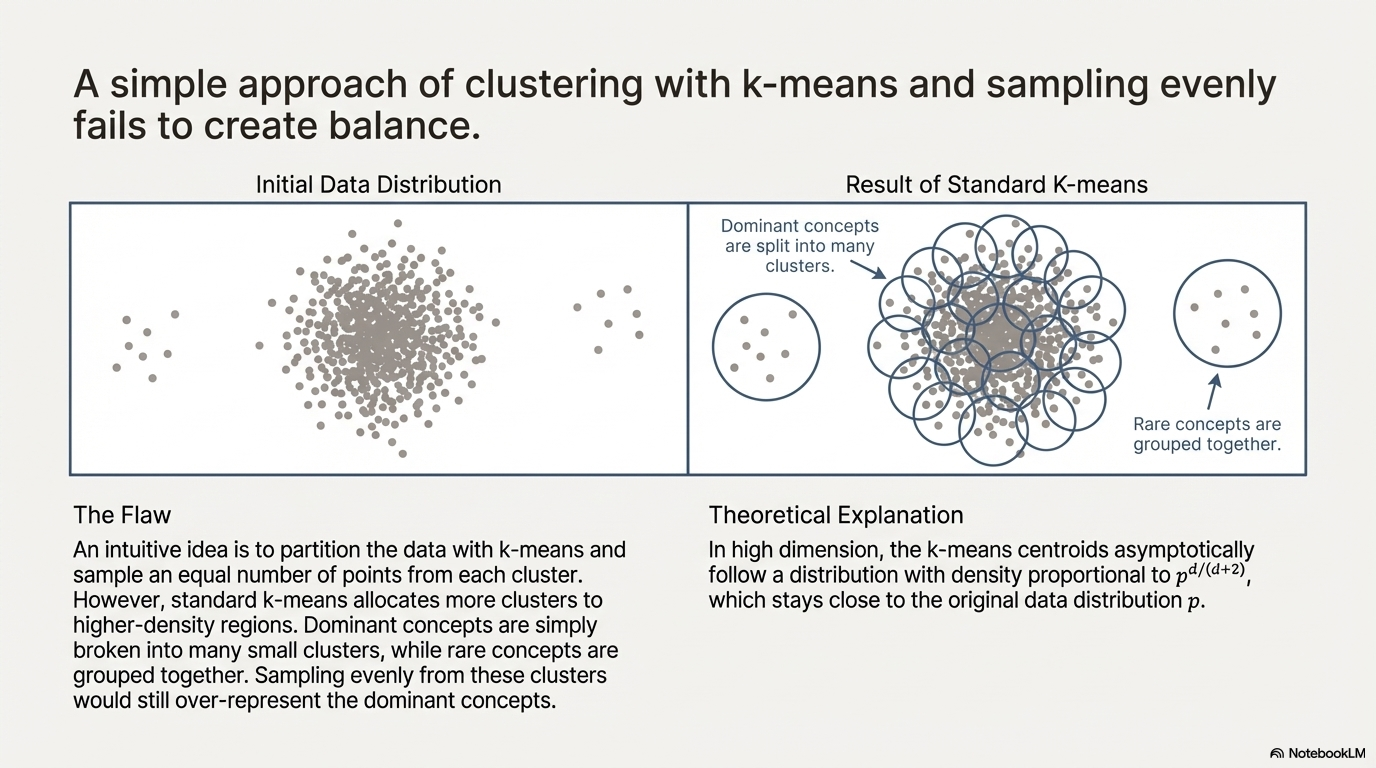
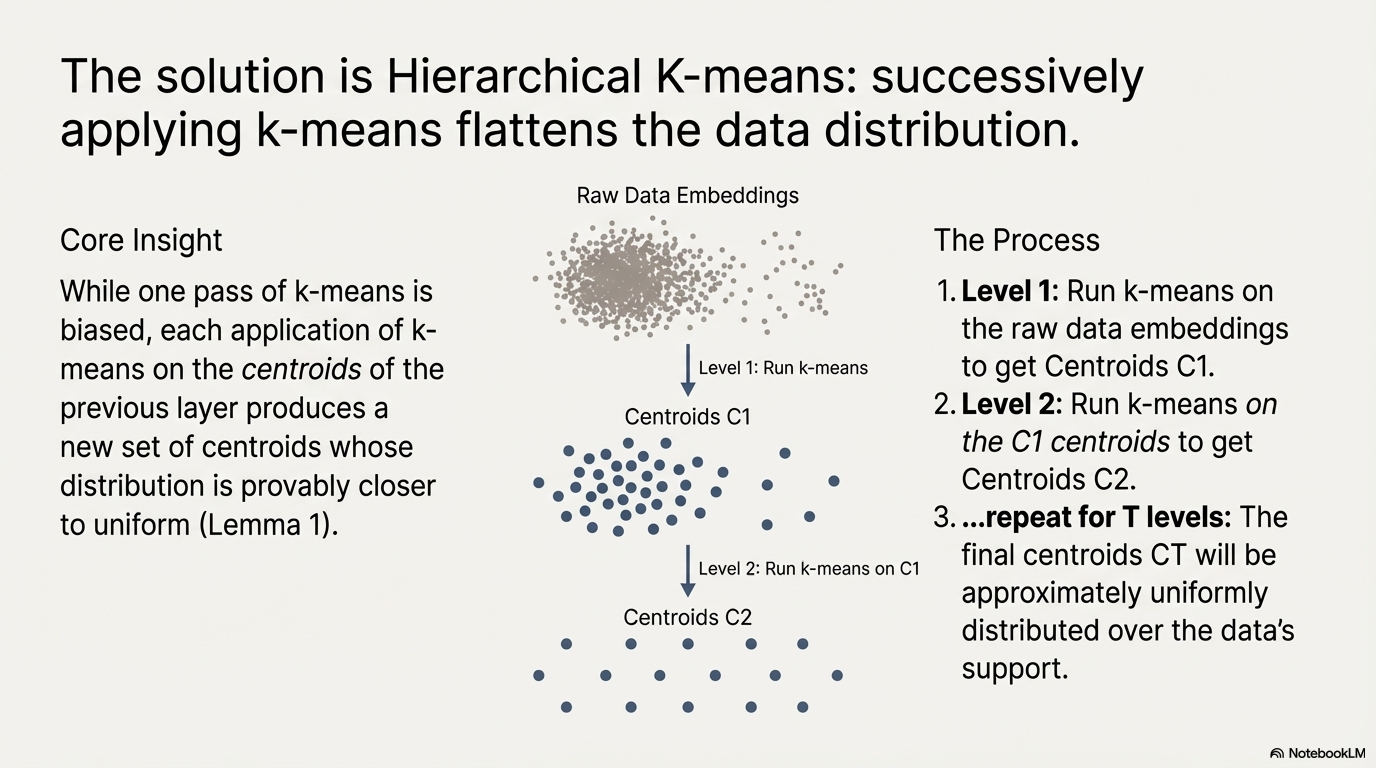 It can be proved that with the application of K-means, the new distribution is closer to the uniform data representation (where it is defined on space with data support) compared with the original distribution.
It can be proved that with the application of K-means, the new distribution is closer to the uniform data representation (where it is defined on space with data support) compared with the original distribution.
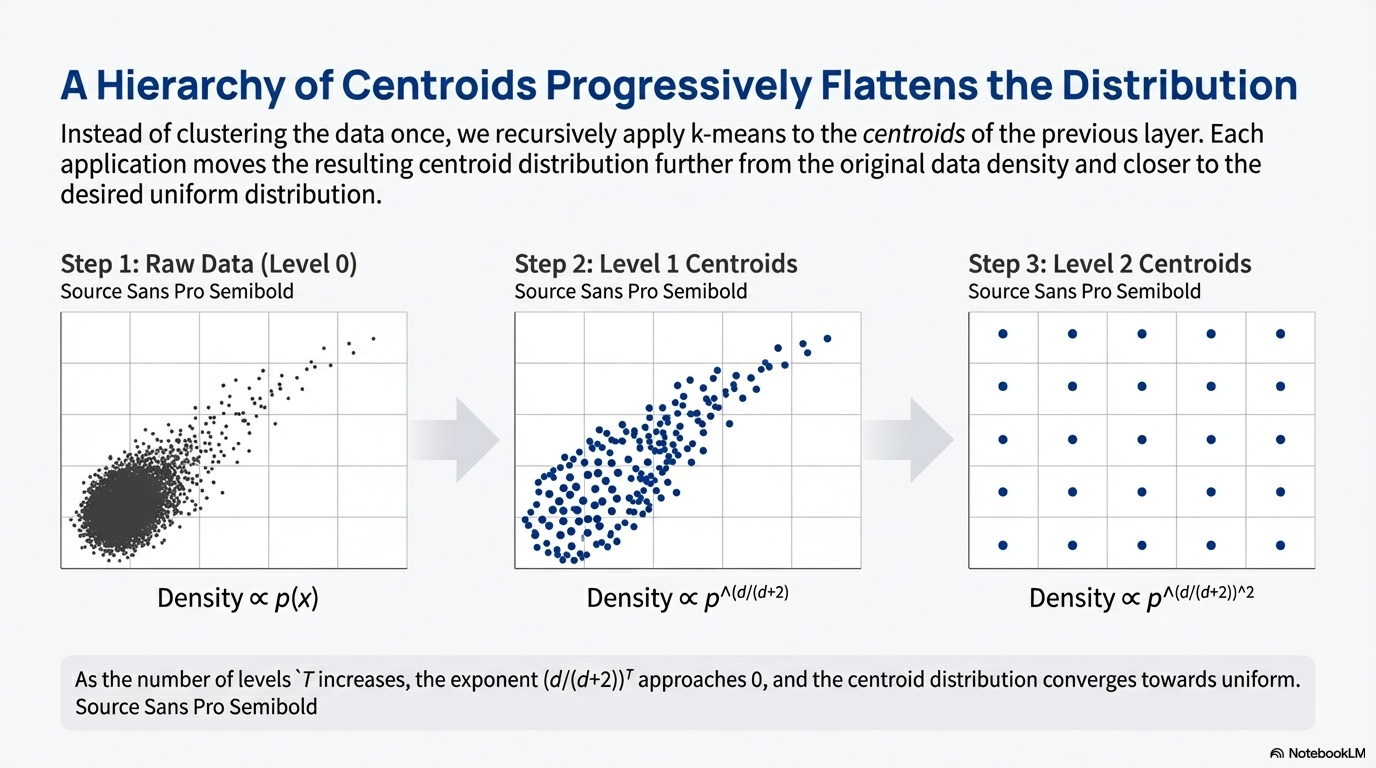
But after each layer we have exponentially less points.