Flash Attention speed up attention computation by
- Incrementally compute softmax without fully materialize the full matmul result. (tiling)
- Recompute intermediate result instead of storing them in backward pass by storing some extra info.
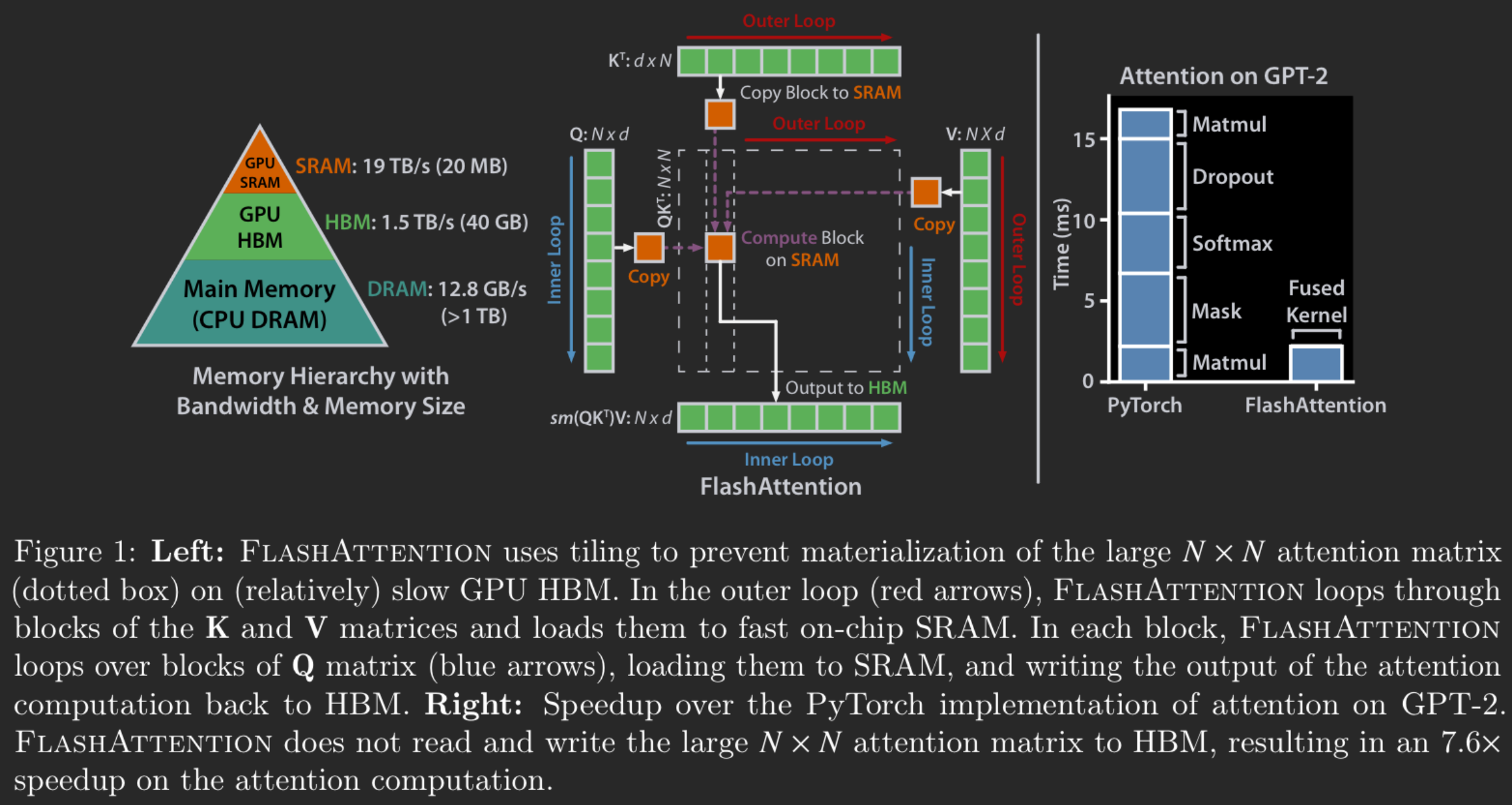 What’s not covered in the paper is “how do you know it’s HBM access making it slow” in the first place.
What’s not covered in the paper is “how do you know it’s HBM access making it slow” in the first place.
Standard attention
is sequence length and is the head dimension

Flash Attention
TODO: Add the Latex formula here.
The backward pass typically requires the matrices to compute the gradients with respect to Q, K, V. However, by storing the output O and the softmax normalization statistics (𝑚, ℓ), we can recompute the attention matrix S and P easily in the backward pass from blocks of Q, K, V in SRAM.
