Depthwise conv has been popular- ized by MobileNet and Xception. We note that depthwise convolution is similar to the weighted sum op- eration in self-attention, which operates on a per-channel basis, i.e., only mixing information in the spatial dimension convnext, page 4
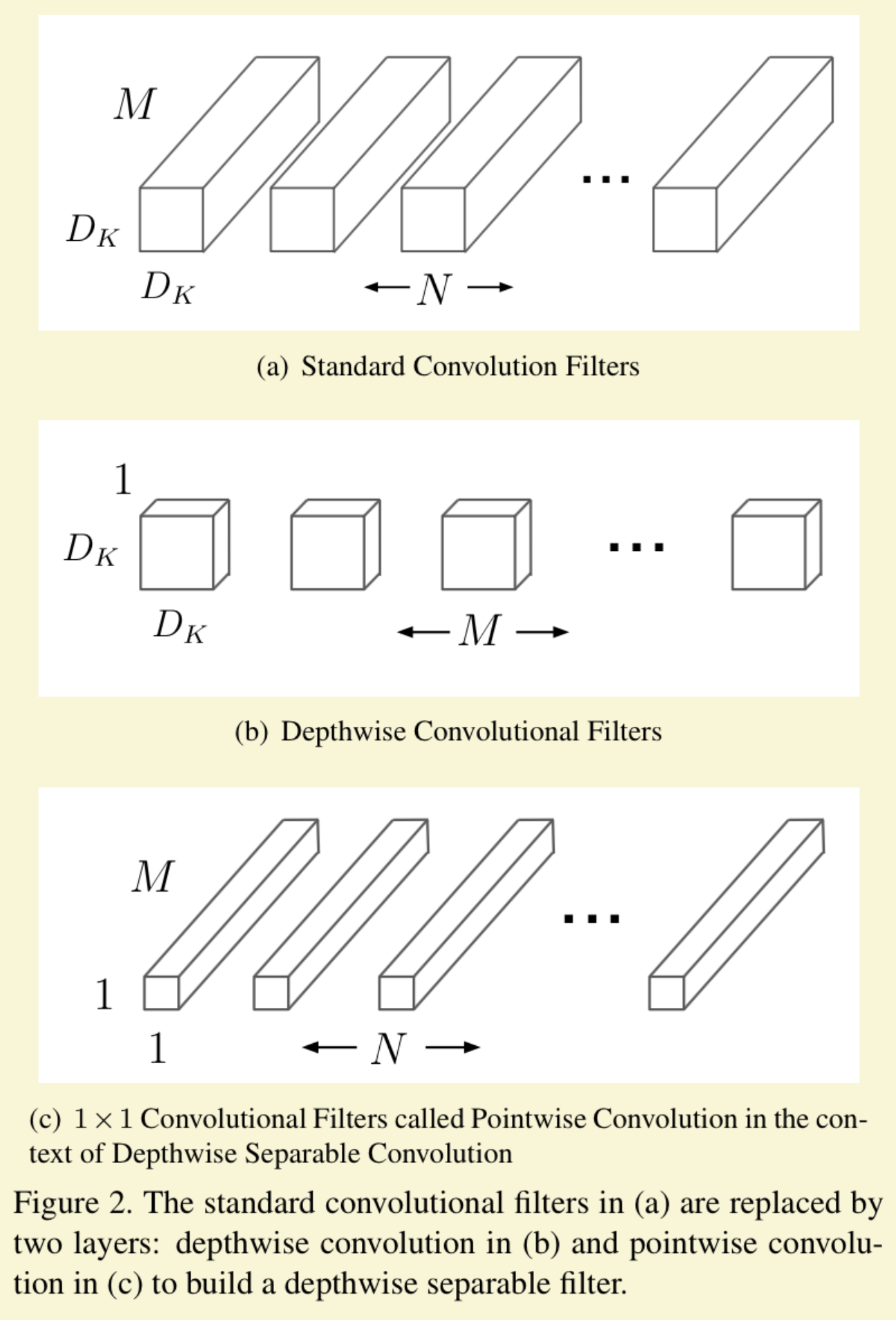 Instead of having , where stands for kernel and stands for feature map, depth wise conv makes it two step, each step handling less capacity:
Instead of having , where stands for kernel and stands for feature map, depth wise conv makes it two step, each step handling less capacity: