The note is based on the videos tutorials linked in the website.
Motivation
Conformal predictions is a way to “calibrate” any model so that model’s empirical probability output (e.g. softmax scores for a classification model) can be converted to a rigorous uncertainty.
Some examples:
- For classification tasks asking for multiple category outputs, we provide a calibration set containing samples, and we want the model to output a set such that , and
. To put in other words, Output a set so we can say with confidence that the probability that the output set contains the ground truth set with probability .

- For regression, we want the model to give a confidence interval for the regressed values.
The general algorithm
-
Identify a heuristic notion of uncertainty using the pre-trained model.
-
Define the score function . (Larger scores encode worse agreement between and .)
-
Compute as the quantile of the calibration scores .
-
Use this quantile to form the prediction sets for new examples:
Example time:
 The score function here is “the softmax logits of the correct class”. And then we see in the calibration set: what’s the percentile of that score? Then we can tell for a new sample: if any class score is larger than that percentile, then we include that in the output set. It can be proved that
The score function here is “the softmax logits of the correct class”. And then we see in the calibration set: what’s the percentile of that score? Then we can tell for a new sample: if any class score is larger than that percentile, then we include that in the output set. It can be proved that
, where is the calibration set size.
Why does it work
There seem to be some bayesian process in play here: we estimate here, given . But no, it’s actually based off the concept of exchangeability, so that it’s not depending on actual data distribution.
Not the score is , not .
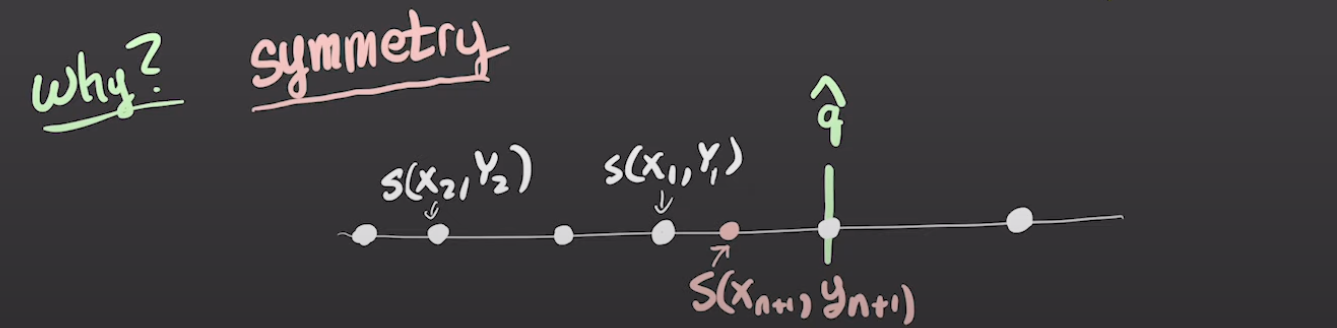
Think about it like this: say the white dots are the calibration samples. Red is the test data. We’ll put in the output if . This is right if there’s a “label” in the calibration set that have a score . Note: we do not care about false positives here. So as long as the score of this “label” actually does not fall on the right side of , all is good, and that probability of mistake is (this sample can be between any samples in the calibration set).
Another classification algorithm
 Now we use cumulative sum up to the ground truth class as score.
Now we use cumulative sum up to the ground truth class as score.
Conformalized quantile regression
First, train models that output quantile values directly. That can be done with Pinball loss.
Then you calibrate that quantile:
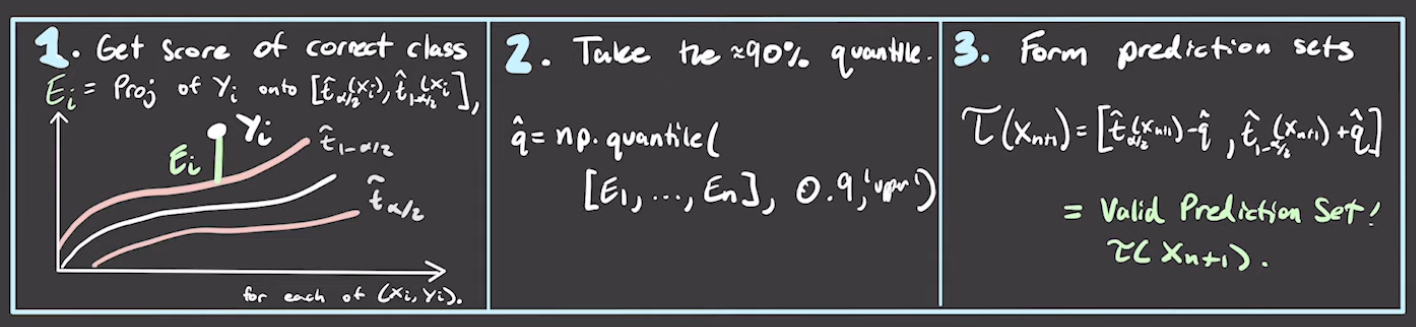
There’s also part 2 and 3 video that I also finished, but didn’t got the time to finish the notes. To be finished later.