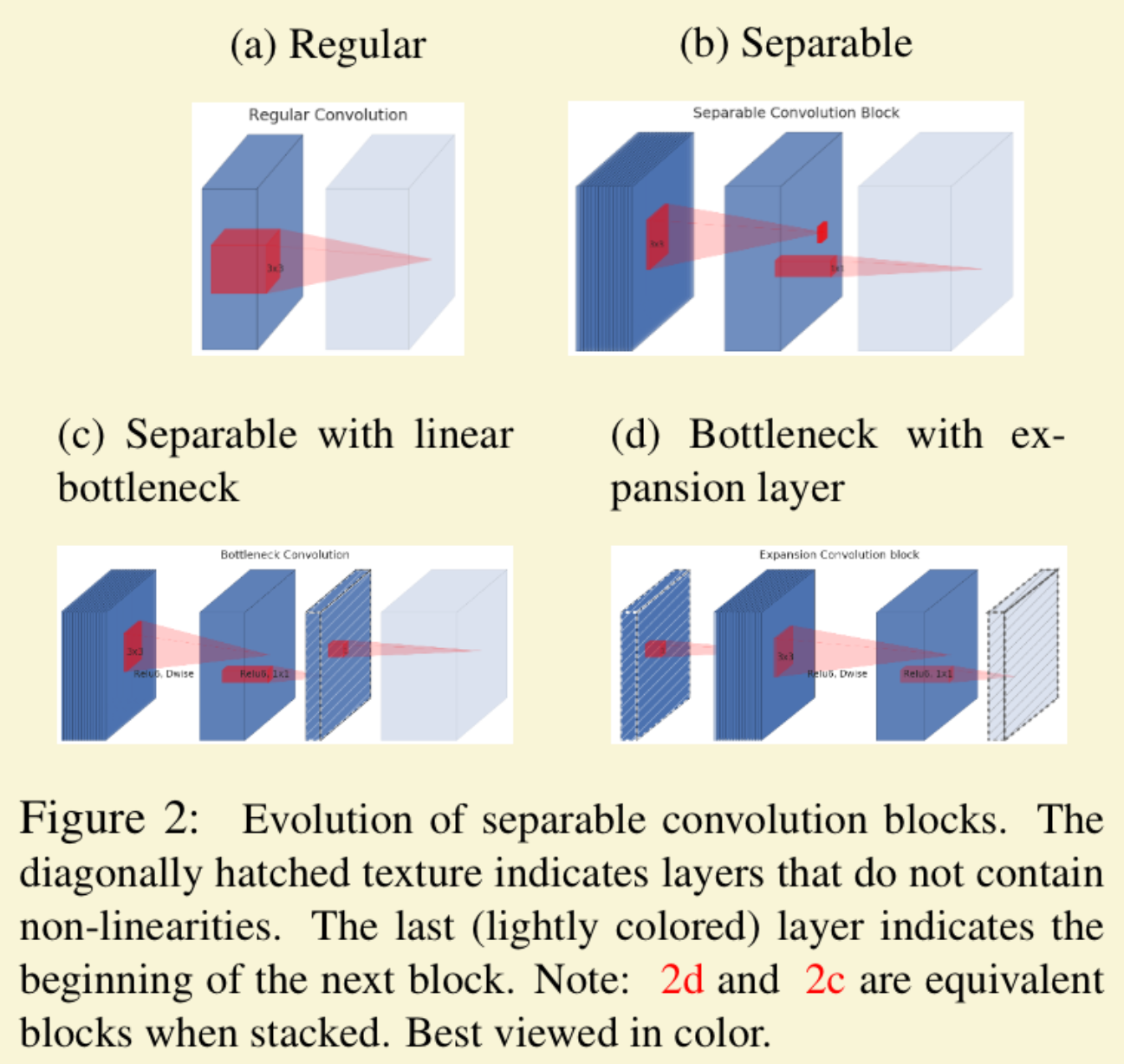
Informally, for an input set of real images, we say that the set of layer activations (for any layer ) forms a “manifold of interest”. It has been long assumed that manifolds of interest in neural networks could be embedded in low-dimensional subspaces. mobilenet_v2, page 2
Consider the case for ReLU, which in space leads to piece linear curve with n-joints, and thus we got information lost. Here in the image we can see some data is just collapsed in low dim. On higher dim this is fine, since now the manifold is only a small part of the input space.

Thus, we force the manifold to be low dimension, by having this bottleneck, and we do not have ReLU or other activations on this bottleneck.