The paper claims: I’m the new generation of MoT! There was tracking-by-detection, tracking-by-regression, and I’m tracking-by-attention!
Technically, our TrackFormer also performs regression in the mapping of object embeddings with MLPs. However, the actual track association happens earlier via attention in the Transformer decoder.
I found that a pretty weak statement. Basically it’s saying “this rounds’ detection A does not directly translate to next rounds’ detection”.
Generally speaking, TrackFormer is applying DETR to tracking.
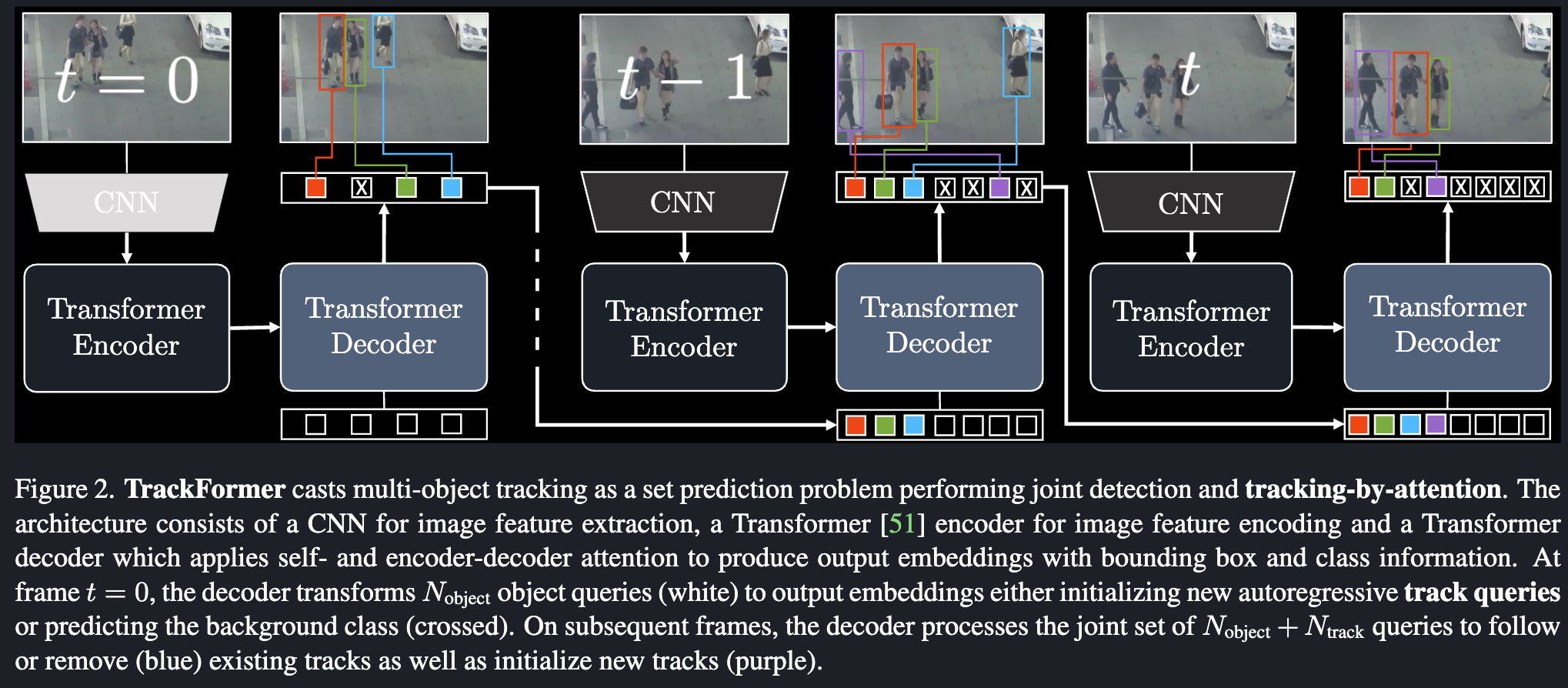 DETR only do it for one frame, but here, it reuse the track query generated as the “object query” for next frame, and use that positional information to do association.
DETR only do it for one frame, but here, it reuse the track query generated as the “object query” for next frame, and use that positional information to do association.
The loss used is still Biparticle matching + set prediction loss.