This notes is based on the deep dive video given by Edward Z Yang. He also has a blog that hosts some PyTorch internal deep dives.
Some knowledge not covered by the video: deploy requires no graph breaks.
Overview
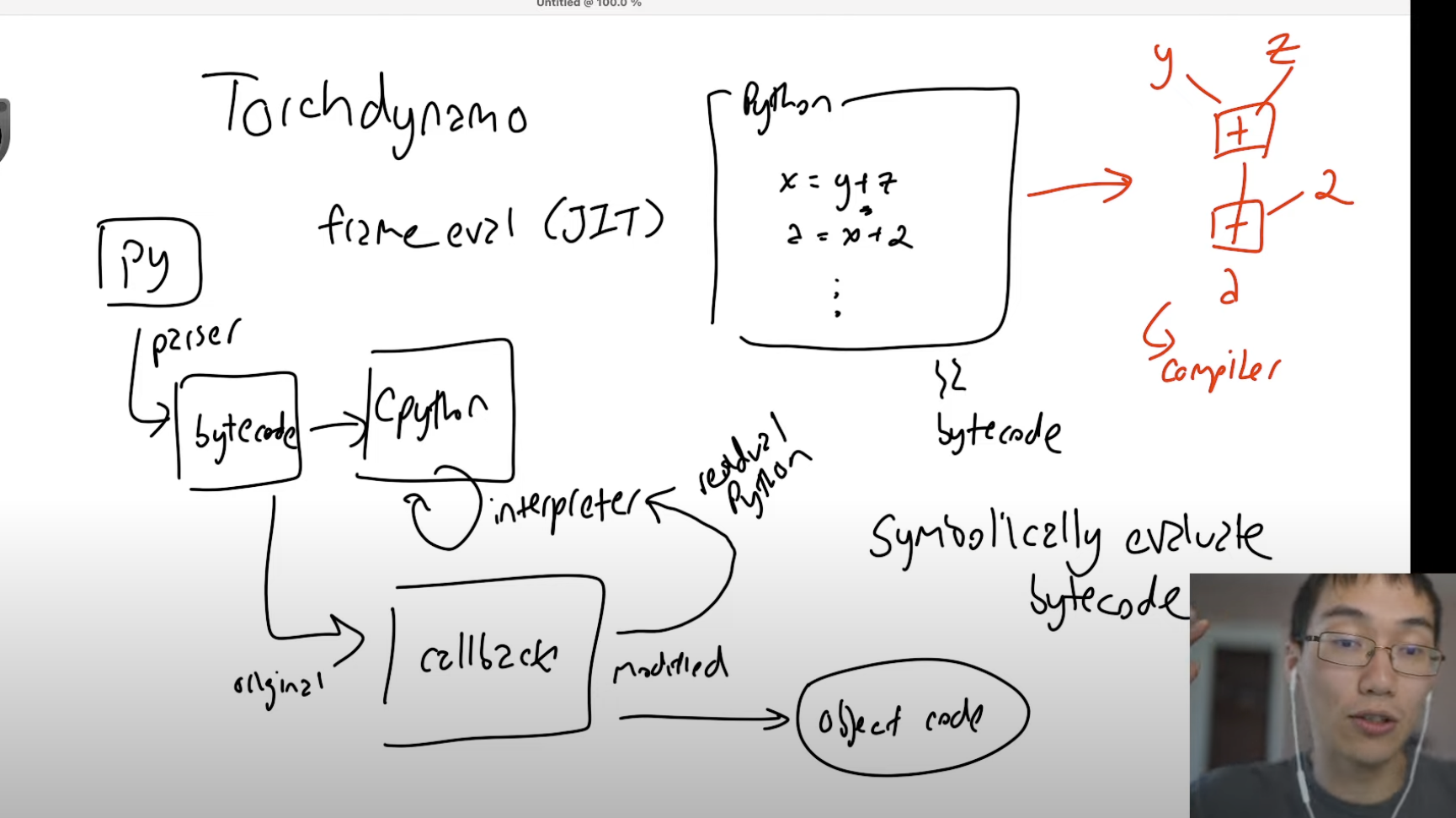
TorchDynamo wants to do similar things as TorchScript and FX Script: catch the graph, and then operate on it. In that sense it’s similar to JIT. TorchDynamo takes an easier route than Pypy, in that instead of operating directly on the Python code itself, it operated on the parsed bytecode, to be run by CPython. Operating on byte code provides a simpler interface.
What’s that bytecode thing look like? Some opcode that Python provides a disassembler for. All documented in the dis module.
In summary, Torch Dynamo convert bytecode to FXGraph, possibly multiple subgraphs, and they can be output as bytecode, just like JIT.
How does achieve that?
In CPython’s C API, one is allowed to set a frame handler for Python functions. That frame means function frame here, so all the stack information. So Torch Dynamo basically does a cached compilation of the code (an Python bytecode interpreter inside Python, symbolically interpreting the code), converting original opcodes into a FX Graph. Specifically, we pay special attention to Torch tensors, so they are put into a graph and can be compiled.
This is a stack machine, so we don’t need to provide register no. to BINRAY_ADD . The name stack machine / register machine is a common theme among VMs, e.g. JVM is a stack machine. It can also be thought of as postfix notation.
An example of how LOAD_FAST is handled: (for source, see here)
def LOAD_FAST(self, inst): name = inst.argval if self.exec_recorder and name in self.f_locals: self.exec_recorder.add_local_var(name, self.f_locals[name]) try: self.push(self.symbolic_locals[name].unwrap()) except KeyError: if name.startswith("."): try: # This happens in dict/list comprehensions self.push(self.symbolic_locals[name.replace(".", "implicit")]) except KeyError: unimplemented("undefined LOAD_FAST (implicit)") else: unimplemented("undefined LOAD_FAST") # for continuation functions if name.startswith("___stack"): self.symbolic_locals.pop(name)
You can see really the important part is self.push, which means pushing the stuff to a self maintained stack.
def push(self, val: Optional[VariableTracker]): assert val is None or isinstance( val, VariableTracker ), f"push expects VariableTracker, got {typestr(val)}" self.stack.append(val) # type: ignore[arg-type]
What about BINARY_ADD, etc.? It’s implemented via this:
So it’s popping n vars from stack, call_function, which concretely or symbolically evaluated result.
[! Graph break vs guard tradeoff]
We can get a more generic tracing by having graph breaks, saying “it’s unclear how to handle it”, or put guards saying “this generated bytecode is only valid if b is a constant that == 42”. If it’s not the same, then we need to compile a new version.
Where’s call_function defined then? Depends on the variable. E.g. for a constant dict, here.
elif name == "items": assert not (args or kwargs) if self.source: tx.output.guard_on_key_order.add(self.source.name()) return TupleVariable( [TupleVariable([k.vt, v]) for k, v in self.items.items()] )elif name == "__len__": assert not (args or kwargs) return ConstantVariable.create(len(self.items))elif name == "__setitem__" and arg_hashable and self.mutable_local: assert not kwargs and len(args) == 2 tx.output.side_effects.mutation(self) self.items[Hashable(args[0])] = args[1] return ConstantVariable.create(None)
The video and the latest source has already differ in how it handles __getitem__, but as can be seen, it overloads all methods currently exposed via the Python interface, and does somenthing with them, mutating the graph and sometimes directly getting the result. Same for tensor, where all operations are logged into graph.