So in task execution / motion planning the system my predict future actions (execution horizon). Only get executed (execution horizon). The paper studies what’s the best way to make this action chunking work in the face of inference latency.
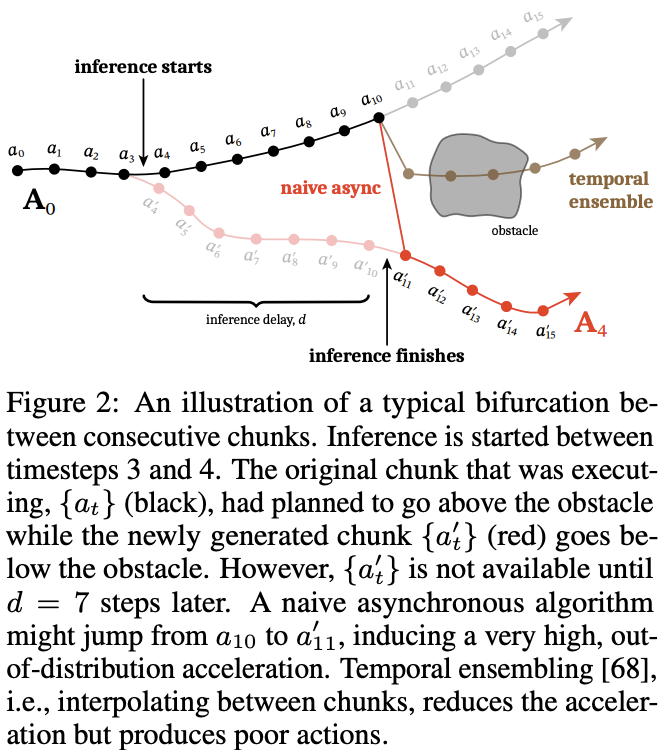
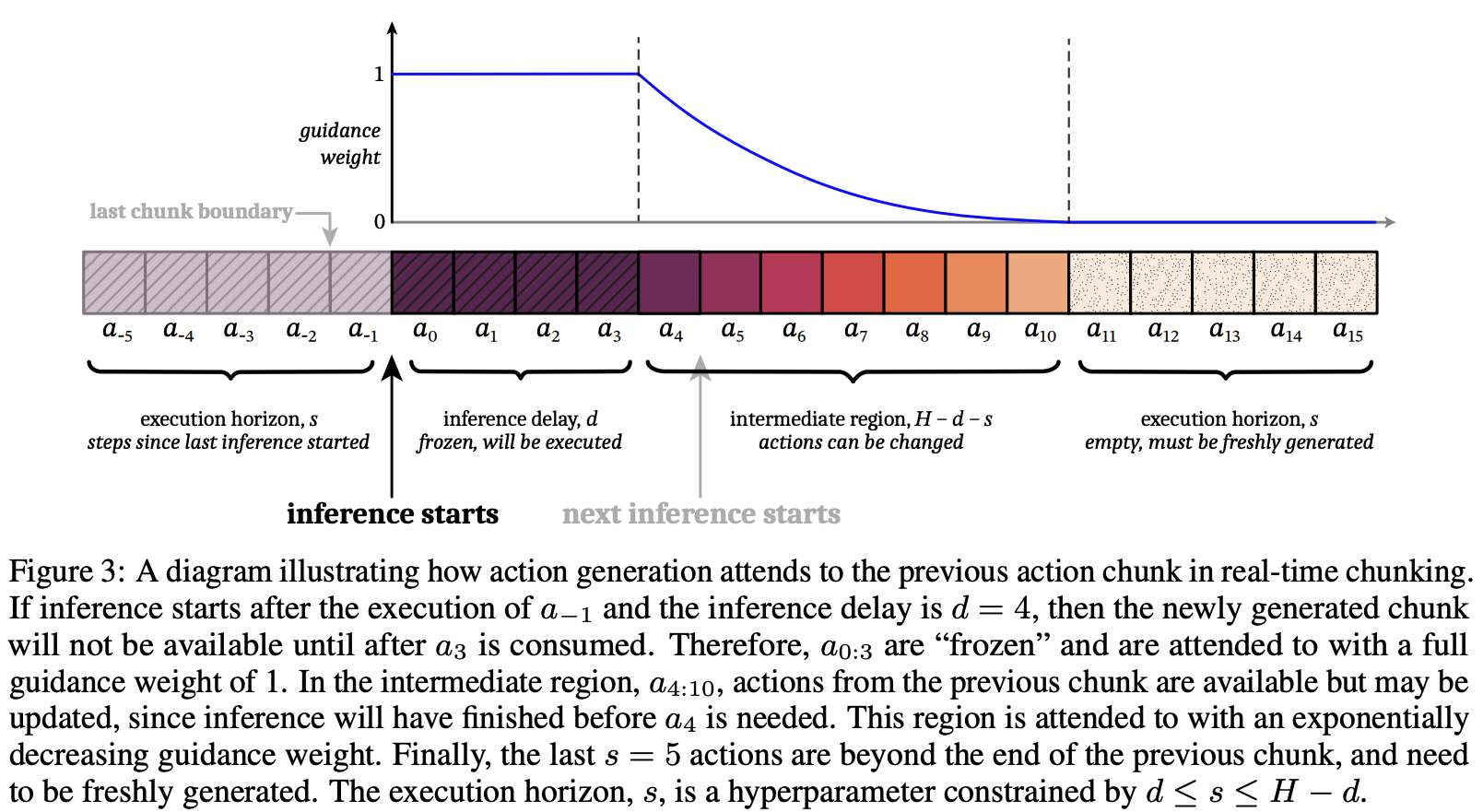
Our key insight is to pose real-time chunking as an inpainting problem. To make the new chunk “compatible”, we must use the overlapping timesteps where we have access to the remaining actions of the previous chunk. The first d actions from the new chunk cannot be used, since those timesteps will have already passed by the time the new chunk becomes available. Thus, it makes sense to “freeze” those actions to the values that we know will be executed; our goal is then to fill in the remainder of the new chunk in a way that is consistent with this frozen prefix (see Figure 3), much like inpainting a section of an image that has been removed
So basically they are saying inpainting is perfect for stuff that need continuity but smarter than just ensembling.
For the inpainting, they used a training-free way with Flows, based on pseudoinverse guidance (ΠGDM).
Since ΠGDM is not perfect, and the guidance can be weak, they use soft masking that includes overlapping actions with exponential decay mask. Recall that the difference is (the new policy can overwrite the old policy, but the old policy may still have left).
Question
Q: It’s still blending. How is this better than simple ensemble? A: It seems likeTE mixes outputs; RTC mixes information by turning the previous chunk into a constraint and resampling a coherent trajectory that satisfies it. No formal guarantee.