The note only covers the core encoder-decoder attention part., BP-LSTM and stuffs are not important.
def attention_context(attention_key, attention_value, query, lens):
"""
Args:
attention_key, attention_value: values from simple MLP layer from listener.
query: output from deep cell
query + attention_key to generate the attention (softmax).
Then this attention is multiplied on attention value.
"""
energy = torch.bmm(attention_key.transpose(0, 1), torch.unsqueeze(query, 2)).squeeze(2)
attention = F.softmax(energy, dim=1).mul(sequence_mask(lens).float().to(DEVICE).detach())
attention = F.normalize(attention, p=1, dim=1)
context = torch.bmm(torch.unsqueeze(attention, 1), attention_value.transpose(0, 1)).squeeze(1)
return context, attention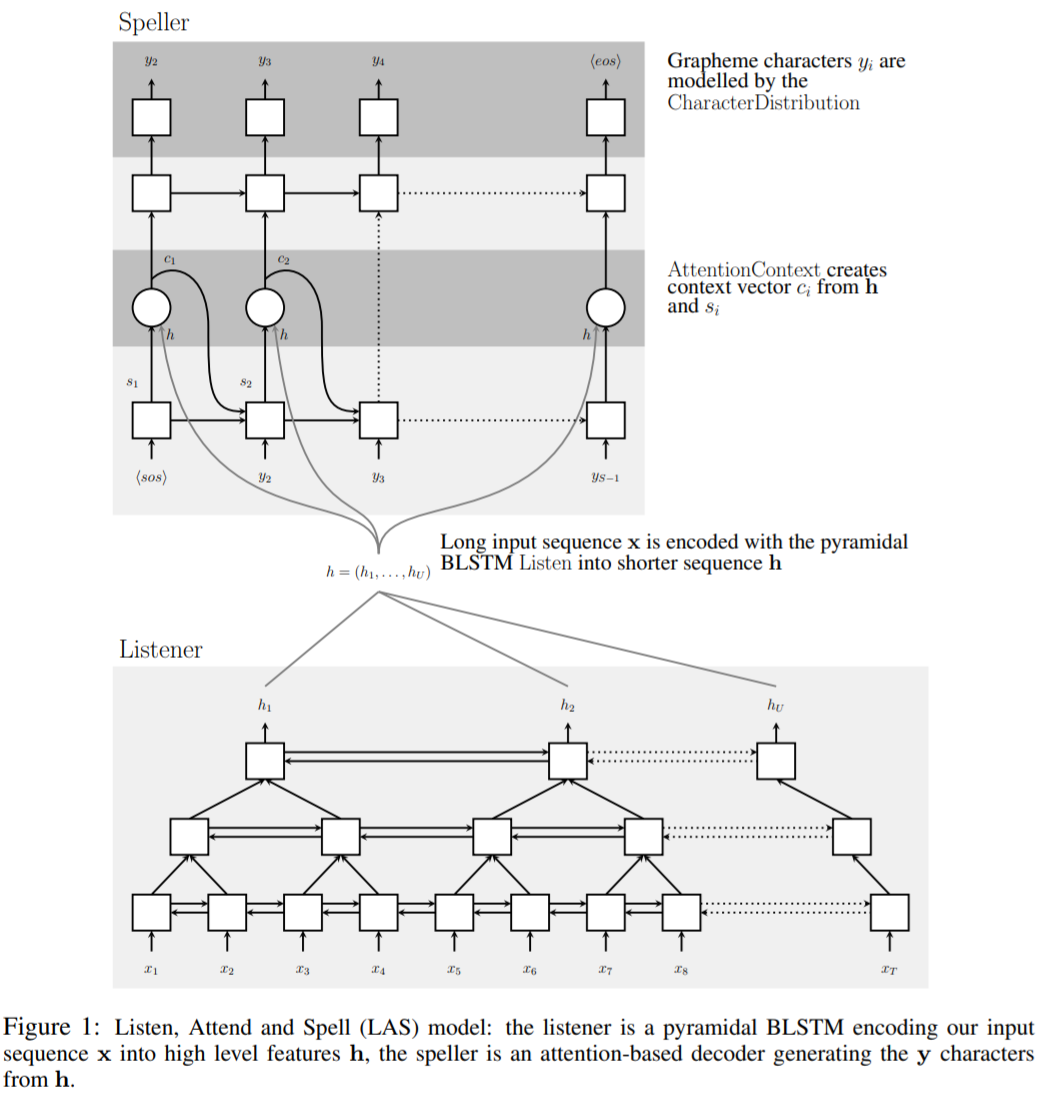
The here is query (output from cell).