Generated via Claude 4.6 Opus, resulted from a conversation.
The Kullback-Leibler divergence measures how one probability distribution differs from a reference distribution :
It has several independent derivations. The most concrete starts from coding theory.
Coding Theory Motivation
Why start from coding theory for a quantity about probability distributions?
A probability distribution assigns beliefs over outcomes. The coding question asks: if you had to act on those beliefs — commit resources under uncertainty — how costly would it be? Code length is the most stripped-down version of that: allocating a finite resource (bits) based on how likely you think each outcome is.
keeps appearing not because we care about bits per se, but because the logarithm is the unique function that converts multiplicative probability structure into additive cost structure while respecting independence. Coding theory is just the cleanest context where that becomes concrete — you can point at a literal string of bits and say “this is what your wrong beliefs cost you.”
You could skip coding entirely: define by formula, prove non-negativity, show uniqueness from axioms. That’s mathematically complete but unmotivated. The coding interpretation gives physical intuition for why each piece is there — why weights, why , why the ratio .
The Setup: Encoding Messages
Suppose we need to transmit a sequence of symbols (events, classes, outcomes) over a channel. Each symbol is drawn from some distribution . We want to assign a binary code to each symbol — shorter codes for frequent symbols, longer codes for rare ones.
For example, if we have four symbols with equal probability , we need 2 bits each: 00, 01, 10, 11. But if symbol A occurs 50% of the time, we’d prefer to give it a shorter code.
The Kraft Inequality: What Constrains Code Lengths
For a code to be uniquely decodable (no codeword is a prefix of another), the code lengths must satisfy:
This is the Kraft inequality. It’s a hard constraint from the structure of binary prefix codes — it limits how many short codewords you can have. If you make one code shorter, others must get longer.
Optimal Code Lengths → Entropy
Given this constraint, what code lengths minimize the expected cost ? This is a constrained optimization problem. Using Lagrange multipliers, the solution is:
Plugging back in, the minimum achievable expected code length is:
This is entropy — not defined axiomatically, but derived as the solution to “minimize expected code length subject to Kraft.” That’s Shannon’s source coding theorem: no lossless code beats , and codes exist that come arbitrarily close.
Note
Fractional bits is generally not an integer. Practical codes like Huffman coding round to integers (achieving average length between and ). Arithmetic coding gets arbitrarily close to by encoding sequences jointly rather than symbol-by-symbol. The theorem is an asymptotic statement about what’s achievable in principle.
Using the Wrong Code → Cross-Entropy
Now suppose reality follows , but we design our code for distribution . By the same Kraft argument, the optimal code lengths for are . But symbols still occur with frequency . The expected code length becomes:
This is cross-entropy. The weighting doesn’t change — reality is still — we’ve just plugged in the wrong code lengths.
The Excess Cost → KL Divergence
The difference between what we pay and what we could have paid:
KL divergence is the extra bits per symbol you pay for using instead of .
"Surprise" is an interpretation, not the foundation
is often introduced as the “surprise” of event , with entropy defined as “expected surprise.” This is a useful interpretation — the quantity is indeed zero for certain events, large for rare ones, and additive for independent events. But these properties aren’t axioms chosen because “surprise should work this way.” They’re consequences of being the optimal code length under the Kraft inequality. “Surprise” is a name we give to the result after the fact.
Other Derivations
Hypothesis Testing
Given i.i.d. samples from , the expected log-likelihood ratio between and is:
KL divergence is the expected evidence per sample in favor of over when is true. This connects to Stein’s lemma: governs the exponential decay rate of Type II error in hypothesis testing.
Axiomatic Uniqueness
KL divergence can be characterized as essentially the unique divergence satisfying:
- with equality iff
- Additivity over independent variables
- Invariance under sufficient statistics (the data processing inequality)
This is formalized through Csiszár’s work on -divergences.
Connection to Riemannian Geometry
For two nearby distributions and on the Statistical Manifold, KL divergence to second order is:
where is the Fisher Information matrix. The Fisher metric is the local quadratic approximation of KL divergence — this is how information geometry derives the Riemannian structure of probability space from KL divergence, not the other way around.
This is why the Natural Gradient — which uses — is the steepest descent direction in the geometry induced by KL divergence rather than Euclidean distance.
Properties
- Non-negative: (Gibbs’ inequality), with equality iff
- Asymmetric: in general — it is not a true metric
- Not a distance: violates triangle inequality and symmetry
- Additive: for independent variables,
The following comes from blog post:
- Approximating KL Divergence by John Schulman
- KL Divergence for Machine Learning by Dibya Ghosh, who at the time was Sergey’s student.
Discussed with Claude Sonnet 4.6
Forward vs. Reverse KL: Geometric Intuition
KL divergence is asymmetric — — and the two directions have fundamentally different optimization behavior. The names forward and reverse are convention-dependent, so the behavior is the thing to hold onto.
Consider fitting an approximate distribution to a target .
In the illustration, is the blue one, bimodal, and the normal one, orange.
Minimizing — sampling from , penalizing where has mass that misses:
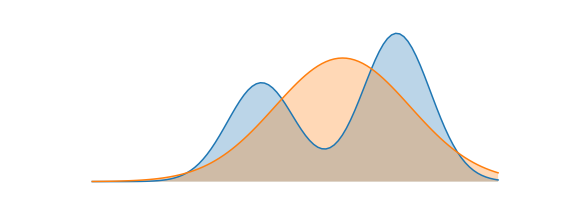 A good approximation under this objective satisfies: wherever has high probability, must also have high probability. The mechanism is that wherever but , the term blows up — so is forced away from zero there. If is bimodal, will spread between both modes rather than miss one entirely, even if the result fits neither mode well. This is mass-covering (or mean-seeking) behavior.
A good approximation under this objective satisfies: wherever has high probability, must also have high probability. The mechanism is that wherever but , the term blows up — so is forced away from zero there. If is bimodal, will spread between both modes rather than miss one entirely, even if the result fits neither mode well. This is mass-covering (or mean-seeking) behavior.
Minimizing — sampling from , penalizing where has mass that doesn’t support:
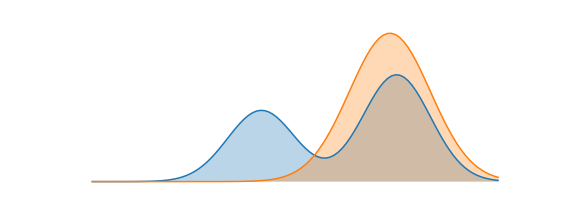 A good approximation under this objective satisfies: wherever has high probability, must also have high probability. The mechanism is that wherever but , the term blows up — so is afraid to put mass outside ‘s support. If is bimodal, will snap to one mode and ignore the other. The entropy term in the expansion prevents from collapsing to a point; the typical behavior is to find the widest mode of and mimic it exactly. This is mode-seeking behavior.
A good approximation under this objective satisfies: wherever has high probability, must also have high probability. The mechanism is that wherever but , the term blows up — so is afraid to put mass outside ‘s support. If is bimodal, will snap to one mode and ignore the other. The entropy term in the expansion prevents from collapsing to a point; the typical behavior is to find the widest mode of and mimic it exactly. This is mode-seeking behavior.
Gradient scaling intuition
The functional derivative with respect to makes the asymmetry precise:
The term diverges as — this is the mechanism behind mass-covering. The term grows only logarithmically, which is why mode-seeking exerts much weaker pressure toward coverage. Source: Max Shen’s blog
What Access Do You Need?
The choice of direction is often constrained by what you have access to, not just preference:
- requires samples from — you evaluate at those samples. This is the supervised learning setting: you have a dataset drawn from the true distribution.
- requires evaluating pointwise — you sample from and score those samples under . This is the RL setting: you can’t sample optimal trajectories, but you can score any trajectory via reward.
Connections to Supervised Learning and RL
Supervised learning minimizes forward KL. Given a dataset of samples , minimizing Cross Entropy loss over a model is identical to minimizing , since the entropy of is a constant:
This covers classification (cross-entropy loss), regression (MSE = NLL of a Gaussian), and maximum likelihood estimation generally.
RL minimizes reverse KL. In the control-as-inference framing (Sergey’s work), optimal trajectories have probability . We can’t sample from this distribution directly, but we can evaluate it. Minimizing over a policy recovers the max-entropy RL objective — which is exactly why reverse KL is the natural regularizer in RLHF and PPO. You want the actor to stay within the reference’s support, not cover all of it.
Monte Carlo Estimation of KL
When and are high-dimensional (e.g., distributions over sequences), computing analytically is intractable. We only have pointwise access to and at sampled . So we need a Monte Carlo estimator.
Define (the density ratio at a sample). Three natural estimators exist, each with different bias/variance properties.
The Three Estimators
All three are trying to estimate the same quantity , but they trade off differently.
is the direct definition rewritten: exactly (unbiased). But individual samples can be negative (since has no sign constraint), while the true KL is always non-negative. This sign-flipping creates high variance — the estimator is correct on average but noisy sample by sample.
fixes the sign problem by squaring: every sample is non-negative. But in general — it is biased. The bias is small when , and grows as the distributions diverge.
achieves the best of both: it is unbiased like and always non-negative like .
Numerical Comparison (from Schulman)
, , true :
| Estimator | bias / true KL | std / true KL |
|---|---|---|
| 0 | 20 | |
| 0.002 | 1.42 | |
| 0 | 1.42 |
With larger divergence (, true ):
| Estimator | bias / true KL | std / true KL |
|---|---|---|
| 0 | 2 | |
| 0.25 | 1.73 | |
| 0 | 1.70 |
dominates: unbiased with low variance in the small-KL regime, and still competitive when KL is large. The bias of becomes serious once and are far apart.
is not always the right choice
The numerical comparison above makes look strictly better, but the choice of estimator depends on how KL is used in code — not just value estimation quality. Xihuai Wang (2025) shows that when KL is used as a differentiable loss term (direct backprop), naively backpropagating through on-policy gives the forward KL gradient, not reverse — the wrong direction. And when KL is used as reward shaping (stop-gradient), introduces a bias term equal to into the policy gradient update. In both cases or may be more appropriate depending on the setup. See Choosing KL Estimators in RL for the full analysis.
Notably, is the one that’s being used in GRPO.
Why Works: Three Perspectives
1. Control Variate
Any quantity with zero expectation under can be added to without introducing bias. The only natural zero-mean term here is , since . So for any :
is still unbiased. The question is what minimizes variance. The optimal depends on and and has no closed form. But a simple argument fixes : since is concave, for all , so setting guarantees the estimator is non-negative everywhere. Positivity alone substantially reduces variance.
2. f-Divergence and Second-Order Universality
An f-divergence is any functional of the form:
for a convex with . KL corresponds to . The expectation of is the f-divergence with . These are different divergences, but a key fact is:
All f-divergences agree to second order near
For any differentiable convex , a parametric family near :
D_f(p_0 | p_\theta) = \frac{f''(1)}{2} ,\theta^\top F \theta + O(\theta^3) $$ where $F$ is the [[Fisher information]] matrix. Normalizing so $f''(1) = 1$, all f-divergences look like $\frac{1}{2}\theta^\top F\theta$ locally — the same quadratic.
Both (KL) and (‘s expectation) satisfy . So ‘s expectation is a faithful local surrogate for KL whenever . The bias only becomes visible when the distributions separate enough for third-order terms to matter.
3. Bregman Divergence
The deepest perspective. A Bregman divergence generated by a convex function is:
This measures the gap between and the tangent plane to at , evaluated at . Since is convex, it lies above all its tangent lines, so always — and the gap vanishes only when .
Now let , and evaluate :
So is exactly the Bregman divergence of , between the ratio and the equilibrium point (where ). Non-negativity is not a clever trick — it falls out immediately from convexity of .
KL itself is also a Bregman divergence
where is the negative entropy, acting on probability vectors. So both KL and are Bregman divergences — one between distributions, one between scalar values of the ratio . The non-negativity and the quadratic shrinking near both descend from the same convexity argument.
The General Recipe
For any f-divergence with convex , subtracting the tangent at gives an always-positive, unbiased estimator:
This is — the Bregman divergence of at the equilibrium. For , use (which has ), giving the estimator .
| Target | Estimator | |
|---|---|---|
The Unifying Inequality
All three perspectives trace back to one fact:
This is just concavity of , or equivalently convexity of . It is also the same inequality used to prove via Jensen’s inequality. The non-negativity of KL and the non-negativity of share the same root.