TL;DR: Slap CenterNet on a 3D detector and profit.
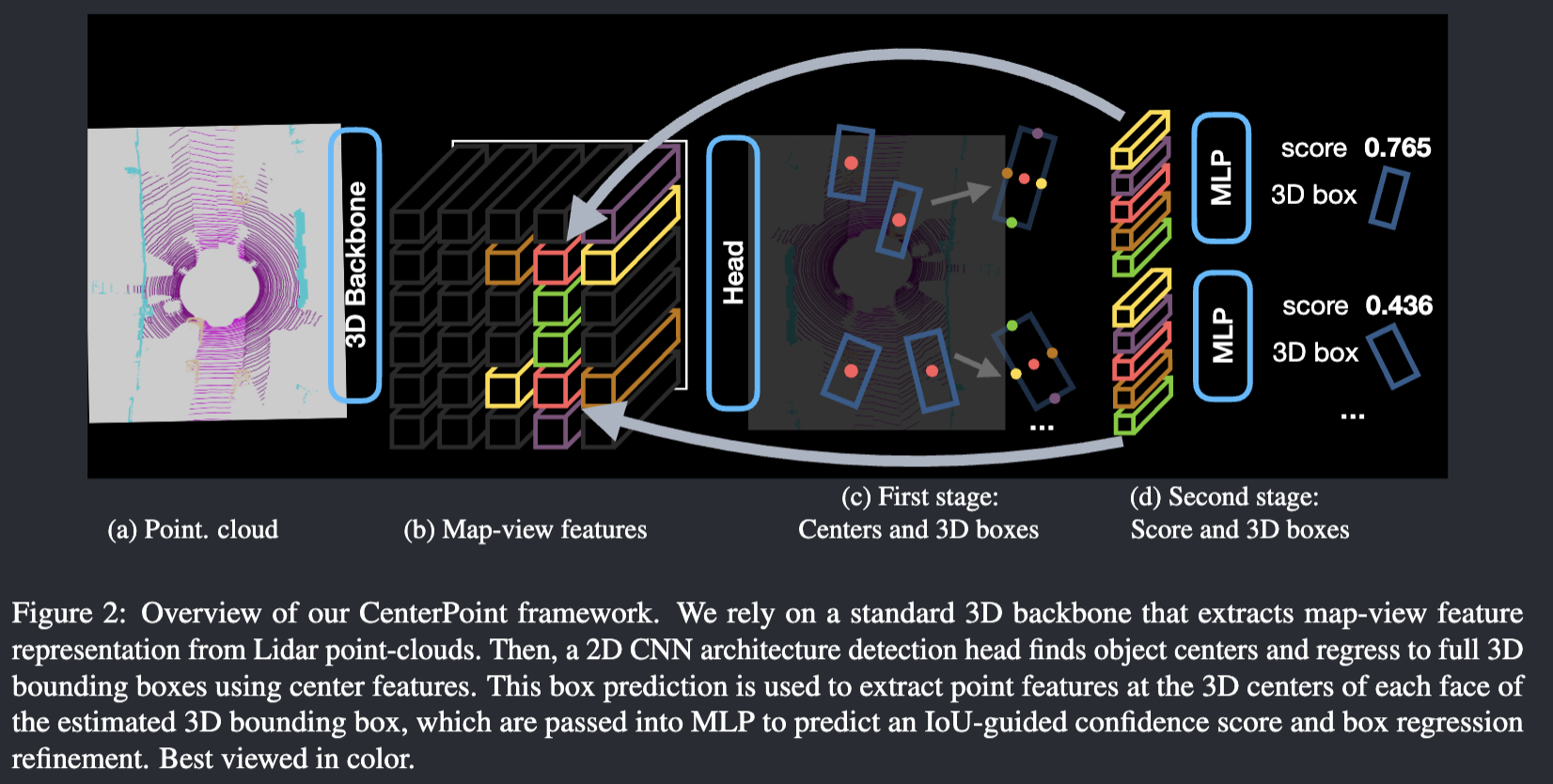
A 3D object detector such as VoxelNet or PointPillars would output a map-view feature map. From that we can get center heatmap together with other attributes. Worth noting is that in BEV, object are much sparser than image. To counter that, the gaussian radius used to render ground truth peak need to be enlarged. They borrow from CornerNet on the radius formula.
Similar to CenterTrack, velocity is predicted with 2 frames as input.
We also need a second stage:
However, all properties of the object are currently inferred from the object’s center-feature, which may not contain sufficient information for accurate object localization. For example, in autonomous driving, the sensor often only sees the side of the object, but not its center
Since the box is predicted in the first stage, we can get the point feature from the 3D center of each face of the predicted bounding box, pass them to MLP and further refine the result, with 10% of the computation cost. The final scoare is the geometric average of the two scores from the first and second stage.