Model structure wise I don’t see much novel. It’s basically applying LLS and combine Lidar. It does some work to make the inference faster. The overall structure is pretty simple.
Why BEV
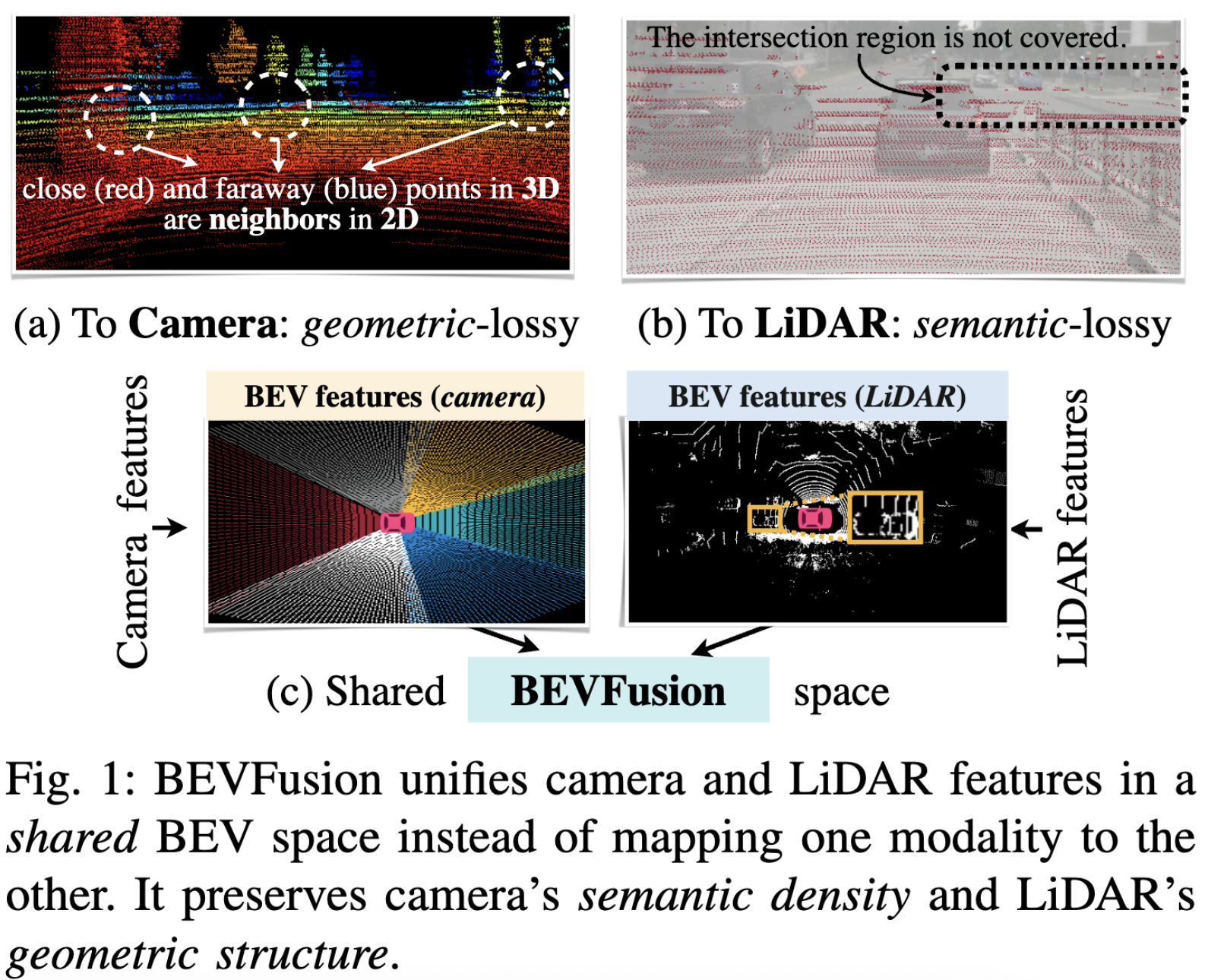
Details
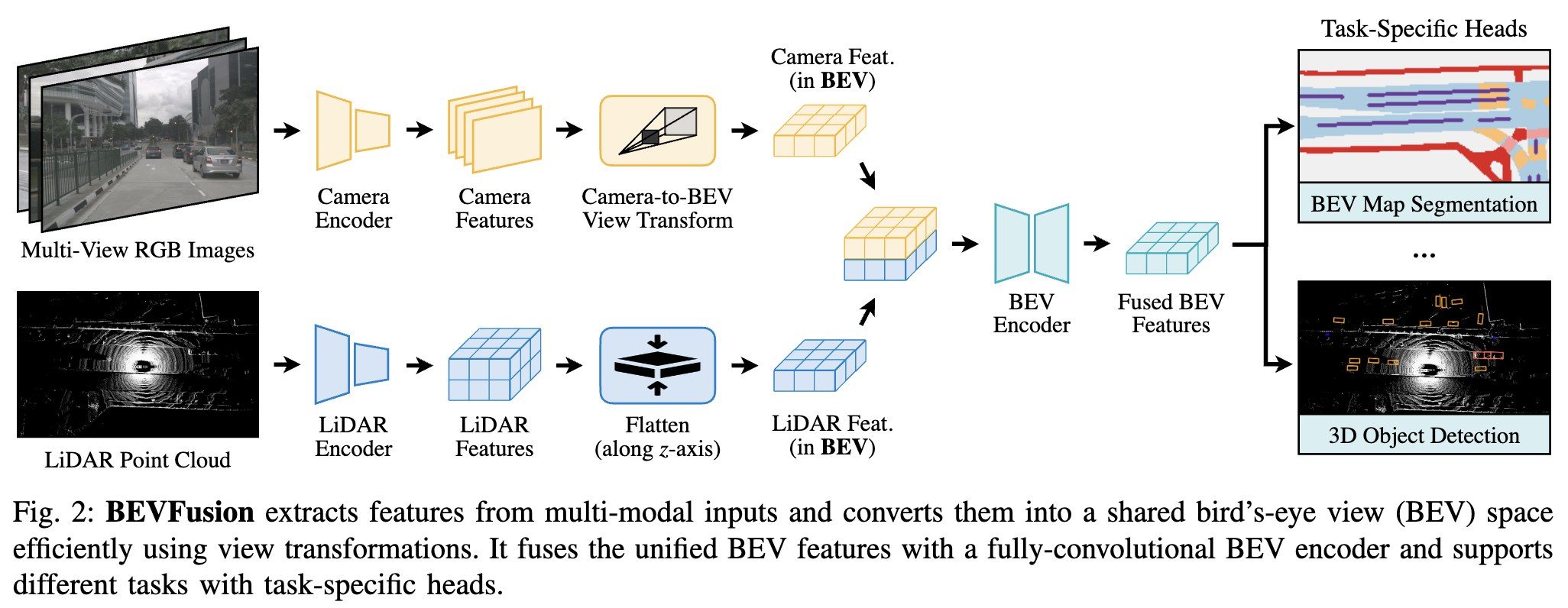
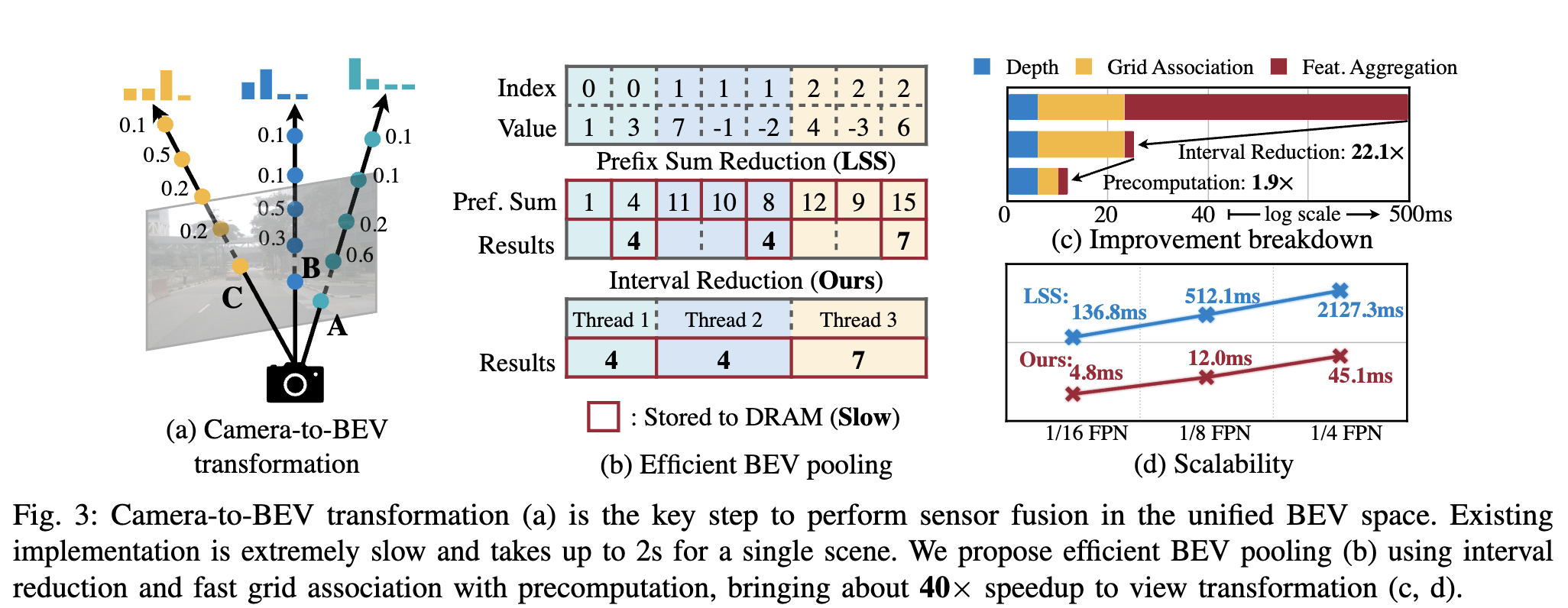
They use the same way as LSS for camera-to-bev transformation: predict discrete depth for each pixel. So the output is of shape NHWD. Note the H and W here are image size. We then quantize it along the x, y axes, same as LSS.
The BEV pooling is inefficient. We can speed it up by caching, assuming the camera calibration stays the same. We then need to pool the points within the grid. LLS’s prefix sum way is inefficient. The author writes a custom kernel to make it much faster.